
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1.3.2 Характеристики рассеяния
Характеристики положения описывают центр распределения. В то же время значения вариант могут группироваться вокруг него как в широкой, так и в узкой полосе. Поэтому для описания распределения необходимо охарактеризовать диапазон изменения значений признака. Для описания диапазона варьирования признака используются характеристики рассеяния. Наиболее широкое применение нашли размах вариации, дисперсия, стандартное отклонение и коэффициент вариации.
Размах вариации определяется как разность между максимальным и минимальным значением признака в изучаемой совокупности:
R=xmax-xmin.
Очевидным достоинством рассматриваемого показателя является простота расчета. Однако поскольку размах вариации зависит от величин только крайних значений признака, то область его применения ограничена достаточно однородными распределениями. В остальных случаях информативность этого показателя весьма невелика, поскольку существует очень много распределений, сильно отличающихся по форме, но имеющих одинаковый размах. В практических исследованиях размах вариации используется иногда при малых (не более 10) объемах выборки. Так, например, по размаху вариации легко оценить, насколько различаются лучший и худший результаты в группе спортсменов.
В рассматриваемом примере:
R=16,36 – 13,04=3,32 (м).
Второй характеристикой рассеяния является дисперсия. Дисперсия представляет собой средний квадрат отклонения значения случайной величины от ее среднего значения. Дисперсия есть характеристика рассеяния, разбросанности значений величины около ее среднего значения. Само слово «дисперсия» означает «рассеяние».
При проведении выборочных исследований необходимо установить оценку для дисперсии. Дисперсия, вычисляемая по выборочным данным, называется выборочной дисперсией и обозначается S2.
На первый взгляд наиболее естественной оценкой для дисперсии является статистическая дисперсия, вычисленная, исходя из определения, по формуле:
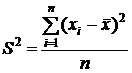 .
.
В этой формуле 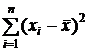 - сумма квадратов отклонений значений признака хi от среднего арифметического
- сумма квадратов отклонений значений признака хi от среднего арифметического ![]() . Для получения среднего квадрата отклонений эта сумма поделена на объем выборки п.
. Для получения среднего квадрата отклонений эта сумма поделена на объем выборки п.
Однако такая оценка не является несмещенной. Можно показать, что сумма квадратов отклонений значений признака для выборочного среднего арифметического меньше, чем сумма квадратов отклонений от любой другой величины, в том числе от истинного среднего (математического ожидания). Поэтому результат, получаемый по приведенной выше формуле, будет содержать систематическую ошибку, и оценочное значение дисперсии окажется заниженным. Для ликвидации смещения достаточно ввести поправочный коэффициент ![]() . В результате получается следующее соотношение для оценочной дисперсии:
. В результате получается следующее соотношение для оценочной дисперсии:
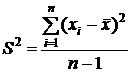 .
.
При больших значениях n, естественно, обе оценки - смещенная и несмещенная – будут различаться очень мало и введение поправочного множителя теряет смысл. Как правило, уточнение формулы для оценки дисперсии следует производить при n<30.
В случае сгруппированных данных последнюю формулу для упрощения вычислений можно привести к следующему виду:
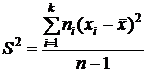 ,
,
где k - число интервалов группировки;
ni - частота интервала c номером i;
xi - срединное значение интервала c номером i.
В качестве примера проведем вычисление дисперсии для сгруппированных данных разбираемого нами примера (см. табл. 4.):
S2=[4 (13,375-14,5331)2+8 (14,045-14,5331)2+10 (14,715-14,5331)2+
5 (15,385-14,5331)2+2 (16,055-14,5331)2]/28=0,5473 (м2).
Дисперсия случайной величины имеет размерность квадрата размерности случайной величины, что затрудняет ее интерпретацию и делает не очень наглядной. Для более наглядного описания рассеяния удобнее пользоваться характеристикой, размерность которой совпадает с размерностью исследуемого признака. С этой целью вводится понятие стандартного отклонения (или среднего квадратического отклонения).
Стандартным отклонением называется положительный корень квадратный из дисперсии:
![]() .
.
В разбираемом нами примере стандартное отклонение равно
![]() (м).
(м).
Стандартное отклонение имеет те же единицы измерения, что и результаты измерения исследуемого признака и, таким образом, оно характеризует степень отклонения признака от среднего арифметического. Иными словами, оно показывает, как расположена основная часть вариант относительно среднего арифметического.
Стандартное отклонение и дисперсия являются наиболее широко применяемыми показателями вариации. Связано это с тем, что они входят в значительную часть теорем теории вероятностей, служащей фундаментом математической статистики. Помимо этого, дисперсия может быть разложена на составные элементы, позволяющие оценить влияние различных факторов на вариацию исследуемого признака.
Помимо абсолютных показателей вариации, которыми являются дисперсия и стандартное отклонение, в статистике вводятся относительные. Наиболее часто применяется коэффициент вариации. Коэффициент вариации равен отношению стандартного отклонения к среднему арифметическому, выраженному в процентах:
![]() .
.
Из определения ясно, что по своему смыслу коэффициент вариации представляет собой относительную меру рассеяния признака.
Для рассматриваемого примера:
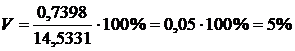 .
.
Коэффициент вариации широко используется при проведении статистических исследований. Будучи величиной относительной, он позволяет сравнивать колеблемости как признаков, имеющих различные единицы измерения, так одного и того же признака в нескольких разных совокупностях с различными значениями среднего арифметического.
Коэффициент вариации используется для характеристики однородности полученных экспериментальных данных. В практике физической культуры и спорта разброс результатов измерений в зависимости от значения коэффициента вариации принято считать небольшим (V<10%), средним (11-20%) и большим (V> 20%).
Ограничения на использование коэффициента вариации связаны с его относительным характером – определение содержит нормировку на среднее арифметическое. В связи с этим при малых абсолютных значениях среднего арифметического коэффициент вариации может потерять свою информативность. Чем ближе значение среднего арифметического к нулю, тем менее информативным становится этот показатель. В предельном случае среднее арифметическое обращается в ноль (например, температура) и коэффициент вариации обращается в бесконечность независимо от разброса признака. По аналогии со случаем погрешности можно сформулировать следующее правило. Если значение среднего арифметического в выборке больше единицы, то использование коэффициента вариации правомерно, в противном случае для описания разброса опытных данных следует использовать дисперсию и стандартное отклонение.
В заключение этой части рассмотрим оценку варьирования значений оценочных характеристик. Как уже было отмечено, значения характеристик распределения, рассчитанные по данным эксперимента, не совпадают с их истинными значениями для генеральной совокупности. Точно установить последние не представляется возможным, поскольку, как правило, невозможно обследовать всю генеральную совокупность. Если использовать для оценки параметров распределения результаты разных выборок из одной и той же генеральной совокупности, то окажется, что эти оценки для разных выборок отличаются друг от друга. Оценочные значения флуктуируют около своих истинных значений.
Отклонения оценок генеральных параметров от истинных значений этих параметров называются статистическими ошибками. Причиной их возникновения является ограниченный объем выборки - не все объекты генеральной совокупности входят в нее. Для оценки величины статистических ошибок используется стандартное отклонение выборочных характеристик.
В качестве примера рассмотрим наиболее важную характеристику положения - среднее арифметическое. Можно показать, что стандартное отклонение среднего арифметического определяется соотношением:
![]() ,
,
где σ - стандартное отклонение для генеральной совокупности.
Поскольку истинное значение стандартного отклонения не известно, то для оценки стандартного отклонения выборочного среднего используется величина, называемая стандартной ошибкой среднего арифметического и равная:
![]() .
.
Величина ![]() характеризует ошибку, которая в среднем допускается при замене генерального среднего его выборочной оценкой. Согласно формуле, увеличение объема выборки при проведении исследования приводит к уменьшению стандартной ошибки пропорционально корню квадратному из объема выборки.
характеризует ошибку, которая в среднем допускается при замене генерального среднего его выборочной оценкой. Согласно формуле, увеличение объема выборки при проведении исследования приводит к уменьшению стандартной ошибки пропорционально корню квадратному из объема выборки.
Для рассматриваемого примера значение стандартной ошибки среднего арифметического равно 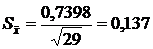 . В нашем случае она оказалась в 5,4 раза меньше значения стандартного отклонения.
. В нашем случае она оказалась в 5,4 раза меньше значения стандартного отклонения.
1.3.3 Характеристики формы
При проведении статистических исследований встречаются распределения, имеющие самые разнообразные формы. Для характеристики отклонения формы распределения от симметричной используется коэффициент асимметрии или просто асимметрия, обозначаемая As и вычисляемая по формуле:
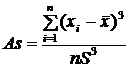 ,
,
где xi - значение i-й варианты;
![]() - среднее арифметическое;
- среднее арифметическое;
S - среднее квадратическое отклонение;
n - объем выборки.
Для симметричной формы распределения коэффициент асимметрии равен нулю. На рис. 8 и 9. показано два асимметричных распределения. Одно из них (рис. 8) имеет положительную асимметрию (As>0), а другое (рис. 9) – отрицательную (As<0). Иногда положительную асимметрию называют левосторонней, а отрицательную – правосторонней. Смысл этого заключается в том, что максимум распределения (и большая часть вариант) смещен влево (или соответственно вправо от значения среднего арифметического.

Рис. 8. Положительная (левосторонняя) асимметрия
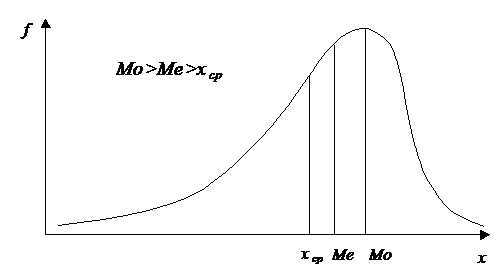
Рис. 9. Отрицательная (правосторонняя) асимметрия
Для сгруппированных данных формула для вычисления коэффициента асимметрии имеет вид:
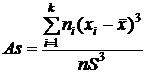 .
.
Здесь ni –частота интервала с номером i;
xi - его срединное значение;
k - число интервалов группировки.
В рассматриваемом примере о толкании ядра:
As=[4 (13,375-14,5331)3+8 (14,045-14,5331)3+10 (14,715-14,5331)3+
5 (15,385-14,5331)53+2 (16,055-14,5331)3]/[29* 0,73983]= 0,260663.
Коэффициент асимметрии положителен, следовательно, можно предположить, что распределение признака в генеральной совокупности имеет левостороннюю асимметрию.
Для быстрой предварительной оценки асимметрии распределения можно воспользоваться ее простейшим показателем - мерой скошенности. Мера скошенности (Sk) определяется как отклонение среднего арифметического (![]() ) от моды (Мо):
) от моды (Мо):
![]() .
.
Нормировка на среднее квадратическое отклонение S производится для обезразмеривания, что необходимо для сравнительного анализа степени асимметрии различных распределений. Применение этого показателя основано на том, что равенство среднего арифметического, моды и медианы имеет место только для симметричных распределений. Поэтому наиболее просто связать показатель асимметрии с соотношением характеристик положения: чем больше разница между средним арифметическим и модой, тем больше асимметрия распределения. В нашем примере:
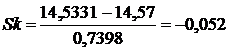 .
.
Как видим, и мера скошенности имеет значение, близкое к нулю. В рассматриваемом случае As>0, а Sk<0. Никакого противоречия в этом нет, поскольку, с одной стороны, оба показателя являются выборочными, и, следовательно, вычислены с погрешностью, а, с другой стороны, оба они близки к нулю. Это соответствует случаю или симметричного распределения, или распределения, мало отличающегося от симметричного.
Следующий показатель - эксцесс - служит для характеристики так называемой крутости, т. е. островершинности или плосковершинности распределения. Эксцессом называется случайная величина, определяемая соотношением:
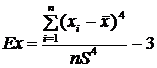 .
.
Число три вычитается из частного потому, что для весьма важного и широко распространенного в природе закона нормального распределения значение этого частного равно трем. Таким образом, для нормального распределения эксцесс равен нулю. Кривые, более островершинные по сравнению с кривой нормального распределения, обладают положительным эксцессом, а кривые более плосковершинные – отрицательным эксцессом. Таким образом, нормальное распределение служит эталоном, а эксцесс показывает крутизну эмпирического распределения относительно крутизны кривой нормального распределения (см. рис. 10).

Рис. 10. Островершинное и плосковершинное распределения
Для сгруппированных данных формула для вычисления эксцесса имеет следующий вид:
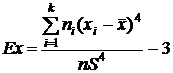 .
.
В нашем примере:
Ex=[4 (13,375-14,5331)4+8 (14,045-14,5331)4+10 (14,715-14,5331)4+
5 (15,385-14,5331)4+2 (16,055-14,5331)4]/[29∙0,73984] - 3= -0,66.
Отрицательное значение эксцесса свидетельствует о наличии тенденции к плосковершинности у рассматриваемого эмпирического распределения.
2 Исследование корреляции и регрессия
Задание. Даны результаты экспериментального исследования двух признаков. Исследовать, существует ли взаимосвязь между этими признаками. Сравнить вариацию двух обследуемых признаков. Если между двумя наборами данных существует связь, то построить линию регрессии. Рассчитать коэффициент ранговой корреляции Спирмена.
2.1 Общие сведения
2.1.1 Виды взаимосвязи
Исследования в области физической культуры и спорта носят, как правило, комплексный характер, при котором изучается не одна характеристика обследуемого объекта, а целая совокупность показателей. В ряде случаев между исследуемыми показателями обнаруживается взаимосвязь. Существует два вида взаимосвязи – функциональная и статистическая.
Функциональной называется взаимосвязь, при которой каждому значению одного показателя соответствует строго определенное значение другого. Например, средняя скорость V движения автомобиля на расстояние S связана со временем движения t: ![]() .
.
Статистической взаимосвязью называется взаимосвязь, при которой одному значению первого показателя может соответствовать несколько значений второго показателя. В качестве примера можно привести зависимость веса человека от его роста. Одному значению роста может соответствовать несколько значений веса.
Среди статистических зависимостей наибольший интерес представляют корреляционные. Корреляционная зависимость заключается в том, что средняя величина одного показателя (Y) изменяется в зависимости от значения другого (X).
Для изучения взаимосвязей используются корреляционный и регрессионный анализ. Корреляционный анализ состоит в определении степени связи между двумя случайными величинами (Y и X). Основной задачей корреляционного анализа является определение формы, направленности и тесноты взаимосвязи. При исследования корреляции используются графический и аналитический подходы.
Графический анализ начинается с построения корреляционного поля. Корреляционное поле (или диаграмма рассеяния) является графической зависимостью между результатами измерений двух признаков. Для ее построения исходные данные наносят на график, отображая каждую пару значений (xi,yi) в виде точки с координатами xi и yi в прямоугольной системе координат.
2.1.2 Форма зависимости
Визуальный анализ корреляционного поля позволяет сделать предположение о форме взаимосвязи двух исследуемых показателей. По форме взаимосвязи корреляционные зависимости принято разделять на линейные (см. рис. 11) и нелинейные (см. рис. 12).
|
|
Рис 11. Линейная статистическая связь | Рис 12. Нелинейная статистическая связь |
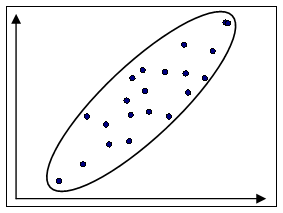
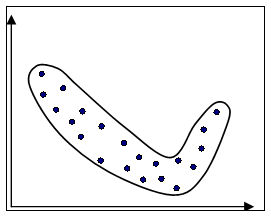
При линейной зависимости огибающая корреляционного поля близка к эллипсу. Линейная взаимосвязь двух случайных величин состоит в том, что при увеличении одной случайной величины другая случайная величина имеет тенденцию возрастать (или убывать) по линейному закону.
Выявление формы статистической зависимости необходимо для выбора метода оценки тесноты (силы) взаимосвязи.
2.1.3 Направленность взаимосвязи
Направленность является положительной, если увеличение значения одного признака приводит к увеличению значения второго (см. рис. 13).
|
|
Рис 13. Положительная направленность | Рис 14. Отрицательная направленность |


Направленность является отрицательной, если увеличение значения одного признака приводит к уменьшению значения второго (см. рис. 14).
Зависимости, имеющие положительные или отрицательные направленности, называются монотонными.
Таким образом, любая монотонная зависимость характеризуется направленностью, которая может быть положительной, или отрицательной.
Зависимость может и не иметь направленности.
2.1.4 Теснота (сила) взаимосвязи
Теснота взаимосвязи может быть оценена качественно по ширине корреляционного поля – чем меньше его ширина, тем больше теснота и сильнее зависимость.
Количественная оценка тесноты взаимосвязи двух случайных величин осуществляется с помощью коэффициента корреляции. Вид коэффициента корреляции и, следовательно, алгоритм его вычисления зависят от шкалы, в которой производятся измерения изучаемых показателей и от формы зависимости.
Принято различать следующие типы шкал: номинальная, порядковая (ординальная), интервальная, относительная (шкала отношения). В соответствии с этими типами шкал существует четыре типа переменных: номинальные, порядковые (ординальные), интервальные и относительные.
Номинальная шкала (или шкала наименований) используются только для качественной классификации. Свойства, характеризуемые с помощью этой шкалы, могут быть измерены только в терминах принадлежности к некоторым, существенно различным классам. Упорядочить эти классы невозможно. Примерами номинальных переменных являются пол, национальность, принадлежность к какому-либо виду спорта. Иногда номинальные переменные называют категориальными. Использование чисел в шкале наименований играет роль ярлыков, позволяющих различать изучаемые объекты. Например, номера игроков в команде.
Шкала порядка позволяет упорядочить (ранжировать) исследуемые объекты, указав какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. В тоже время она не позволяет определить “на сколько больше” или “на сколько меньше”. Примером порядковой переменной является место, занятое спортсменом на соревновании. Номер места позволяет сказать, какой спортсмен сильнее, а какой слабее, но не показывает “на сколько сильнее” или “на сколько слабее”.
Шкала интервалов позволяет не только упорядочивать исследуемые объекты, но и численно выразить и сравнить различия между ними. Особенностью интервальной шкалы является то, что точка отсчета (т. е. нулевая точка) может быть выбрана произвольно. Примерами интервальных переменных является температура, измеренная в градусах Фаренгейта или Цельсия, суставной угол. Шкала интервалов позволяет определить, на сколько одно измеренное значение больше (меньше) другого, но не дает возможности установить во сколько раз больше (или меньше).
Шкала отношений очень похожа на шкалу интервалов, но отличается от нее тем, что положение начала отсчета (точки абсолютного нуля) строго определено. Фиксирование точки отсчета дает возможность определять, во сколько раз одно измеренное значение больше (или меньше) другого. Примерами использования шкал отношений являются измерения времени прохождения дистанции или пространства (длины дистанции, прыжка).
Значение коэффициента корреляции может изменяться в диапазоне от -1 до +1:
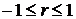 .
.
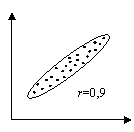
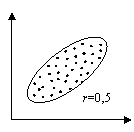
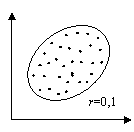
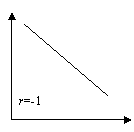
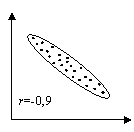
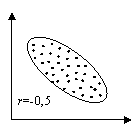
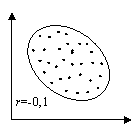
Абсолютное значение коэффициента корреляции показывает силу взаимосвязи. Чем меньше его абсолютное значение, тем слабее связь. Если он равен нулю, то связь вообще отсутствует. Чем больше значение модуля коэффициента корреляции, тем сильнее связь и тем меньше разброс в значениях yi при каждом фиксированном значении xi. Знак коэффициента корреляции определяет направленность взаимосвязи: минус – отрицательная, плюс – положительная (см. рис. 15).
|
|
|
|
|
|
|
|

|
|
|
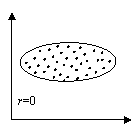
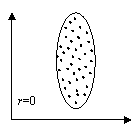
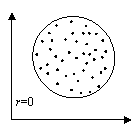
Рис.15. Корреляционные поля при различных значениях коэффициента корреляции
При проведении исследований в области спорта принята следующая классификация взаимосвязей по значению коэффициента корреляции (см. таблицу 5)
Таблица 5
Интерпретация значений коэффициент корреляции
1 |
| функциональная зависимость |
2 |
| сильная статистическая взаимосвязь |
3 |
| средняя статистическая взаимосвязь |
4 |
| слабая статистическая взаимосвязь |
5 |
| очень слабая статистическая взаимосвязь |
6 |
| корреляции нет |
В ряде случаев тесноту взаимосвязи определяют на основании коэффициента детерминации. Коэффициент детерминации равен квадрату коэффициента корреляции, выраженному в процентах:
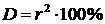
2.1.5 Коэффициент корреляции Бравэ-Пирсона
Коэффициент корреляции Браве-Пирсона применим в том случае, если измерение значений исследуемых признаков производятся в шкале отношений или интервалов и форма зависимости является линейной. Коэффициент корреляции характеризует только линейную взаимосвязь (степень ее тесноты). Линейная взаимосвязь двух случайных величин состоит в том, что при увеличении одной случайной величины другая случайная величина имеет тенденцию возрастать (убывать) по линейному закону.
Для вычисления коэффициента корреляции Браве-Пирсона используется формула:
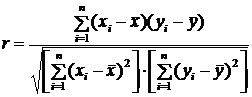 ,
,
либо
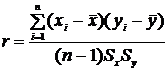 .
.
где ![]() и
и ![]() – средние, а
– средние, а ![]() и
и ![]() стандартные отклонения, рассчитанные по двум выборкам.
стандартные отклонения, рассчитанные по двум выборкам.
Рассчитанный коэффициент корреляции является выборочным, так как он определен для ограниченной совокупности, являющейся выборкой из генеральной совокупности. Поэтому делать вывод о существовании корреляции в генеральной совокупности только исходя из его значения, особенно если его модуль не очень близок к 1, преждевременно. Необходимо проверить статистическую значимость обнаруженной корреляции. Определение статистической значимости коэффициента корреляции осуществляется с помощью критерия Стьюдента. Основные этапы проверки гипотезы о достоверности коэффициента корреляции заключаются в следующем.
1. Задаются уровнем значимости α. В области физкультуры и спорта принято использовать уровень значимости α=0,05.
2. Формулируют гипотезы, которые в дальнейшем необходимо принять или отклонить. Н0: r=0 (в генеральной совокупности корреляции нет, а отличие от нуля выборочного коэффициента корреляции связано со случайными факторами). Н1: r≠0 (в генеральной совокупности корреляция есть).
3. Рассчитывают эмпирическое значение t критерия Стьюдента
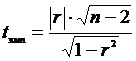
4. По специальной таблице определяют критическое значение критерия tкр для числа степеней свободы n=n-2 и уровня статистической значимости α (см. таблицу 1 Приложения).
5. Сравнивают эмпирическое значение критерия с критическим. Если tэмп ³ tкр, то полученный коэффициент корреляции достоверен, и между исследуемыми показателями существует статистическая связь с вероятностью q=1-α. Если же tэмп < tкр, то полученный коэффициент корреляции недостоверен, и между исследуемыми показателями нет взаимосвязи.
Существует и более простой способ проверки статистической значимости коэффициента корреляции. Он основан на использовании специальных таблиц критических значений коэффициента корреляции (см. таблицу 2 Приложения). Вычисленный коэффициент корреляции сравнивают с критическим значением rкр для объема выборки n и уровня значимости α. Если 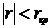 , то принимается гипотеза H0 и делается вывод об отсутствии значимой корреляции. Если же оказывается, что
, то принимается гипотеза H0 и делается вывод об отсутствии значимой корреляции. Если же оказывается, что 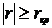 , то гипотеза H0 отклоняется и принимается гипотеза H1, согласно которой значение коэффициента корреляции в генеральной совокупности статистически значимо отличается от нуля на уровне значимости α.
, то гипотеза H0 отклоняется и принимается гипотеза H1, согласно которой значение коэффициента корреляции в генеральной совокупности статистически значимо отличается от нуля на уровне значимости α.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
