


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Доказательство. Доказательство проведем в рамках схемы геометрической вероятности (рис. 5).
![]() .
.
Замечание. 1. Будем говорить, что событие В не зависит от события А, если выполняется равенство Р(В/А) = Р(В), в этом случае
![]() . (8)
. (8)
Вероятность произведения независимых событий равна произведению вероятностей этих событий.
Доказать самостоятельно:
если событие В не зависит от события А, то событие А не зависит от В.
2. 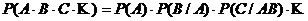 .
.
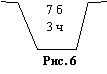 Пример. В урне содержится 7 белых и 3 черных шара (рис. 6).
Пример. В урне содержится 7 белых и 3 черных шара (рис. 6).
Испытание: из урны берут наугад два шара равновозможным образом.
Найти вероятность того, что они:
а) оба белые (Р(бб) – ?);
б) оба черные (Р (чч) – ?);
в) одного цвета;
г) разного цвета.
Решение.
I способ. По определению вероятности (1) (гл.1§1) и по формуле (2) имеем:
а) Р(бб) 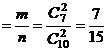 ;
;
б) Р(чч) 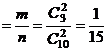 .
.
II способ. По формулам (6) и (7) имеем:
а) Р(бб) = Р (1й белый и 2й белый) = Р(1й белый) ·Р (2й б/ 1й б) =
![]() .
.
б) Р(чч) = Р (1й черный и 2й черный) = Р(1й ч) ·Р (2й ч/ 1й ч) =
![]() .
.
в) Р(одного цвета) =Р (1й б и 2й б или 1й ч и 2й ч) = Р(бб + чч) =
= Р(бб) + Р (чч) =![]() =
=![]() .
.
г) I способ.
Р (разного цвета) = Р (б·ч + ч·б) = Р (б·ч) + Р(ч·б) =
![]() .
.
II способ.
Р (разного цвета) = 1 – Р (одного цвета) = 1 – ![]() =
= ![]() .
.
§ 5. Формула полной вероятности. Формула Байеса
Рассмотрим следующую задачу. имеются три урны с указанным количеством белых и черных шаров (рис. 7).
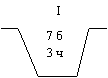 | 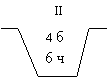 | 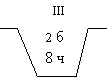 |
Рис. 7
Испытание: из наугад выбранной урны наугад берут один шар. Найти вероятность того, что шар белый.
обозначим: событие А – выбран белый шар, Р(А) – ?.
Введем три предположения (гипотезы):
Н1 – выбран шар из I-ой урны;
Н2 – выбран шар из II-ой урны;
Н3 – выбран шар из III-ей урны.
Очевидно, эти гипотезы являются несовместными событиями, одно из которых обязательно реализуется в результате испытания, то есть
![]() .
.
Найдем вероятности следующих событий:
![]() ,
, ![]() ,
, 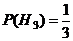 .
.
Р(А·Н1) = Р(Н1)Р(А/Н1), ![]() ;
;
Р(А·Н2) = Р(Н2)Р(А/Н2), ![]() ;
;
Р(А·Н3) = Р(Н3)Р(А/Н3), ![]() .
.
Откуда имеем:
Р(А) = Р (АН1 + АН2 + АН3) = Р (АН1) + Р (АН2) + + Р (АН3) ![]() .
.
Перенесем эту задачу в следующую общую ситуацию: событие А может наступить при одной из n взаимоисключающих гипотез Н1, Н2, …, Нn. Рассуждая аналогично, применяя формулы сложения, умножения событий, получаем формулу
Р(А) = Р(Н1)Р(А/Н1)+Р(Н2)Р(А/Н2) + … +Р(Нn)Р(А/Нn), (9)
которая называется формулой полной вероятности.
Вычисление вероятностей гипотез при наличии дополнительной информации. Формула Байеса.
Рассмотрим две задачи.
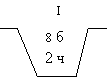 | 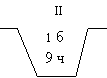 |
рис. 8
1. Известно, что в соседней комнате проводилось следующее испытание: из наугад выбранной урны (рис. 8) брали наугад один шар. Какова вероятность того, что его брали: а) из первой урны (Н1); б) из второй урны (Н2)?
В этой ситуации оба предположения следует считать равновозможными:
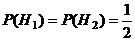 .
.
2. Известно, что в соседней комнате проводилось то же испытание, и был вынут белый шар. какова вероятность, что шар взят: а) из первой урны; б) из второй урны.
В этой ситуации гипотезы нельзя считать равновозможными: в первой урне значительно больше белых шаров, чем во второй. Как в этой ситуации найти вероятности гипотез?
Эта задача может быть в общем виде сформулирована так:
1) в данном испытании интересующее нас событие А может наступить при одной из n взаимоисключающих гипотез Н1, Н2, …, Нn;
2) известно, что испытание проведено и его результат известен: наступило событие А. Как найти вероятности Р(Н1/А), Р(Н2/А), …, Р(Нn/А)?
Утверждение. В указанной ситуации справедлива формула:
![]() , (10)
, (10)
которая называется формулой Байеса.
Доказательство. По формуле (7) имеем
Р(А·Нk) = Р(А) · Р(Нk/А),
Р(А·Нk) = Р(Нk) · Р(А/Нk).
Откуда, учитывая формулу (9), получаем
![]() .
.
§ 6. Схема с повторением испытаний (схема Бернулли)
Рассмотрим следующую часто встречающуюся ситуацию.
1. Проводится серия n независимых испытаний. независимость испытаний означает, что при выполнении каждого следующего испытания полностью восстанавливается комплекс условий, при которых выполнялось предыдущее испытание.
2. При каждом испытании интересующее нас событие А (успех) наступает с вероятностью р и не наступает с вероятностью q = 1 – p. такую ситуацию будем называть схемой с повторением испытаний или схемой бернулли.
Обозначим через x число успехов в серии из n независимых испытаний. Очевидно, x в зависимости от случая принимает значения
0, 1, 2, …, n.
Каковы вероятности этих значений?
Теорема 1. Справедлива формула
![]() , k = 0, 1,…, n. (11)
, k = 0, 1,…, n. (11)
эта формула называется формулой Бернулли.
Доказательство.
![]()
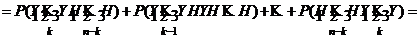
![]()
![]() .
.
Здесь Y (успех) – появление события А, Н (неуспех)– непоявление события А.
Число слагаемых в этой сумме равно числу способов выбрать k мест из n свободных мест, то есть числу сочетаний из n по k:
![]() ,
,
что и требовалось доказать.
Пример 1. Проводится десять независимых бросаний монеты. Найти вероятность того, что три раза из 10 выпадет герб.
Решение. Здесь успех – выпадение герба, x – число успехов, p = q = ![]() , n = 10, k =3. Следовательно, из формулы (11) имеем
, n = 10, k =3. Следовательно, из формулы (11) имеем
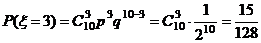 .
.
Пример 2. Проводится 100 независимых бросаний монеты. Найти Р (40≤ x≤ 60), x - число выпадений герба.
Решение.
Р (40≤ x≤ 60) = Р(x = 40) + Р(x = 41) + Р(x = 42) + … +
+ Р(x = 60) =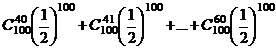 .
.
Мы видим: если в схеме Бернулли число испытаний n велико, то подсчет вероятностей вида P(m1 ≤ x≤ m2) с помощью формулы Бернулли весьма затруднен.
укажем приближенную формулу для подсчета таких вероятностей, доказанную независимо французскими математиками Муавром и Лапласом.
для этого вначале введем функцию, которая называется функцией Лапласа и обозначается Ф(х):
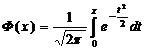 . (12)
. (12)
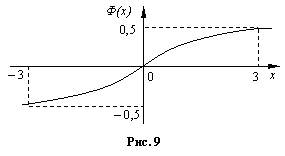 Укажем график и некоторые свойства этой функции.
Укажем график и некоторые свойства этой функции.
10. Ф(0) = 0;
20. Ф (– х) = – Ф(х);
30. если | x | ≥ 3, то Ф (х) » ± 0,5 с большой точностью.
Для функции Лапласа имеются таблицы.
Теорема 2. В схеме Бернулли при достаточно большом числе испытаний справедлива приближенная формула:
P(m1 ≤ x ≤ m2) » 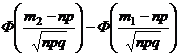 . (13)
. (13)
эта формула называется интегральной формулой Муавра-Лапласа. Доказательство этой формулы приводится в §3 главы 3. Вычисления показывают, что эта формула является практически точной при n ≥ 30.
Вернемся к решению примера 2.
решение. Здесь n =100, p = q = ![]() . По формуле Муавра-Лапласа найдем
. По формуле Муавра-Лапласа найдем
Р (40 ≤ x ≤ 60)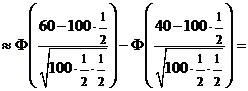
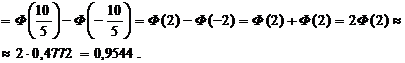
Замечание. Интегральная формула Муавра-лапласа указывает правила вычисления вероятности неравенств вида P(m1 ≤ x ≤ m2) в схеме Бернулли при большом числе испытаний. Укажем правило вычисления вероятностей P(x=k) в этой ситуации.
Рассмотрим функцию
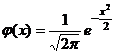 .
.
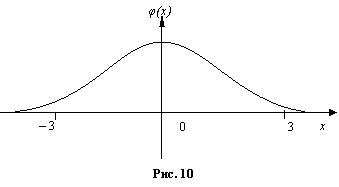 |
Очевидно, φ(х) связана с функцией Лапласа равенством
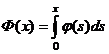 .
.
При большом числе испытаний справедлива приближенная формула
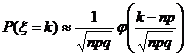 . (
. (![]() )
)
эта формула называется локальной формулой Муавра-Лапласа. Для функции (13') имеются таблицы.
Глава 2. Случайные величины
§ 1. Дискретные и непрерывные случайные величины
Пусть с испытанием связано некоторое число, зависящее от случая. Такое число называется случайной величиной. Случайные величины будем обозначать буквами греческого алфавита: x, h и так далее.
Примеры случайных величин.
1. Число успехов в серии из n независимых испытаний в схеме Бернулли.
2. Число вызовов, поступающих на АТС за единицу времени.
3. Результат измерений какой-либо величины с помощью прибора.
4. Продолжительность телефонного разговора.
случайная величина называется дискретной, если она принимает отдельные изолированные значения, и непрерывной, если ее возможные значения заполняют сплошь промежуток на числовой оси или всю числовую ось.
Очевидно, в первых двух примерах случайные величины являются дискретными, в последних двух примерах – непрерывными.
Статистически зависимые и независимые величины
В математическом анализе изучаются жесткие зависимости между величинами, когда каждому значению одной величины отвечает определенное значение другой. Такие зависимости называются функциональными. Например, площадь круга функционально зависит от его радиуса:
S = pr2.
В теории вероятностей изучаются слабые зависимости между величинами, когда значению одной величины отвечает разброс значений другой величины. такие зависимости называются статистическими.
Определение. Пусть с испытанием связаны случайные величины x,h. Если для любой пары чисел a, b справедливо равенство
P ( x < a / h < b) = P (x < a),
то говорят, что случайная величина x статистически не зависит от h. Если хотя бы для одной пары a, b это равенство не выполняется, то говорят, что случайная величина x статистически зависит от h.
определение статистической независимости имеет следующий смысл: x не зависит от h, если информация о значениях случайной величины h не позволяет высказать никаких новых суждений о случайной величине x.
Пример 1. Из урны берут один за другим два шара. Пусть x,h – номера первого и второго шара. Очевидно, что номер h статистически зависит от номера x.
Пример 2. Из урны берут один за другим два шара, при этом перед взятием второго шара первый шар возвращают в урну и производится перемешивание.
В этом случае номер второго шара h статистически не зависит от номера первого шара x.
Замечание. Ранее мы вводили понятие "независимые события": событие А не зависит от события В, если
Р(А/В) = Р(А).
Очевидно, статистическая независимость случайных величин x, h означает: для любых a, b событие x < a не зависит от события h < b.
§ 2. Закон распределения дискретной случайной величины
Напомним, что дискретная случайная величина принимает отдельные изолированные значения.
Законом распределения дискретной случайной величины x называется таблица
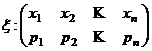 ,
,
где x1 < x2 < … < xn – возможные значений величины x,
а pk (k = 1, …, n) – их вероятности, то есть рk = P(x =хк ).
При этом должно выполняться равенство р1 + р2 + … + рn = 1.
Это равенство означает, что при испытании одно из значений заведомо реализуется. Таблица показывает, как суммарная вероятность 100% распределяется по возможным значениям случайной величины. отсюда термин "закон распределения".
Пример. Производятся три выстрела по цели. Вероятность попадания при одном выстреле равна ![]() . Найти закон распределения числа попаданий в цель.
. Найти закон распределения числа попаданий в цель.
Решение. имеем схему Бернулли, где успехом является попадание в цель ![]() , число испытаний n = 3, x – число успехов после трех испытаний. Требуется найти закон распределения случайной величины x.
, число испытаний n = 3, x – число успехов после трех испытаний. Требуется найти закон распределения случайной величины x.
Пользуясь формулой Бернулли ![]() ,
,
найдем
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
Итого 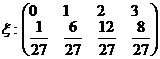 .
.
§3. Математическое ожидание дискретной случайной величины
При решении инженерных задач, связанных с расчетом случая, фундаментальную роль играют так называемые числовые характеристики случайных величин: математическое ожидание и дисперсия. математическое ожидание имеет смысл центрального значения случайной величины. дисперсия характеризует разброс значений случайной величины относительно центра. В этом и следующем параграфах мы изучим эти понятия для дискретной случайной величины.
Пусть x - дискретная случайная величина с законом распределения
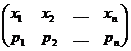 .
.
Математическим ожиданием случайной величины x называется число:
М [ x ] = mx = x1· p1 + x2 · p2 + … + xn · pn
(сумма произведений возможных значений на их вероятности).
Пример 1.
![]()
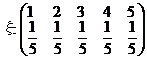
![]() .
.
мы видим: если значения x равновозможны, то математическое ожидание совпадает со средним арифметическим возможных значений x.
Пример 2.
![]()
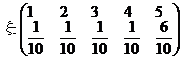
![]() .
.
Помнить: математическое ожидание характеризует центральное значение случайной величины с учетом возможных значений и их вероятностей: маловероятные значения вносят малый вклад в формирование математического ожидания, наиболее вероятные значения вносят основной вклад.
Свойства математического ожидания.
10. М [ a ] = а.
Математическое ожидание неслучайной величины равно самой величине.
20. М [ а x ] = a M [ x ].
Неслучайный множитель выносится за знак математического ожидания.
30. M [ x + h ] = M [ x ] + M [ h ].
Математическое ожидание суммы случайных величин равно сумме математических ожиданий.
40. Если x, h статистически независимы, то
Доказательство.
1. Имеем: ![]() , откуда получаем ma = 1· a = a.
, откуда получаем ma = 1· a = a.
2. Пусть
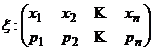 , тогда
, тогда 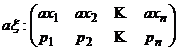 ,
,
откуда М [ а x ] = ax1· p1 + ax2· p2 +…+ axn· pn = a M [ x ].
Для наглядности далее будем предполагать, что x, h принимают два возможных значения:
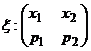 ; h
; h 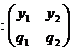 .
.
3. x + h : 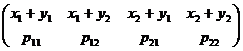 ;
;
M [ x + h ] 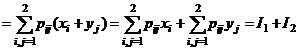 ;
;
I1 = p11 x1 + p12 x1 + p21 x2 + p22 x2 = (p11 + p12)x1 + (p21 + p22)x2.
![]()
![]() ;
;
доказано: р11 + р12 = р1, аналогично получим: р21 + р22 = р2,
тем самым I1 = p1x1 + p2x2 = M [ x ].
Также доказывается, что I2 = M [ h ].
4. В силу теоремы умножения для независимых событий имеем: x · h : 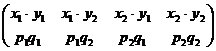 .
.
Тогда
M [ x · h ] = p1q1x1y1 + p1q2x1y2 + p2q1x2y1 + p2q2x2y2 =
= (p1x1 + p2x2) · (q1y1 + q2y2) = M [ x ] · M [ h ].
§4. Дисперсия дискретной случайной величины
Пусть
;
mx = x1· p1 + x2 · p2 + … + xn · pn – математическое ожидание x (центр);
x – mx – отклонение x от центра;
(x – mx)2 – квадрат отклонения x от центра.
Очевидно,
(x – mx)2 : 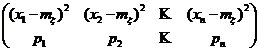 .
.
Дисперсией дискретной случайной величины x называется математическое ожидание квадрата отклонений от центра:
D[ x ] = Dx = M[(x – mx)2] = p1 (x1– mx)2 + p2 (x2– mx)2 +…+ + pn(xn – mx)2.
пример 1. 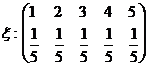 , mx = 3,
, mx = 3,
Пример 2.
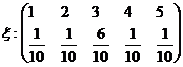 , mx = 3, Dx = 1.
, mx = 3, Dx = 1.
Помнить: дисперсия характеризует разброс случайной величины относительно центра с учетом возможных значений и их вероятностей.
Свойства дисперсии:
10. D [ a ] = 0;
20. D [ a x ] = a2 Dx;
30. если x, h статистически независимы, то
D [ x + h ] = D [ x ] + D [ h ].
40. Dx = M [x 2 ] – ![]() .
.
доказательство.
Первое и второе свойства непосредственно вытекают из определения и соответствующего свойства математического ожидания (доказать самостоятельно).
30. D [ x + h] = M [(x + h – mx + h)2] = m [(x + h – mx – – mh)2] = M [(x – mx+ h – mh)2] = M [(x– mx)2 + (h – mh)2 + + 2(x– mx)(h – mh)] = M [(x– mx)2 ] + M [(h – mh)2] + 2 M [x – – mx ]·M[h – mh] = Dx +dh +2(mx – mx)(mh – mx) = Dx +dh, что и требовалось.
Здесь существенно использовалась статистическая независимость случайных величин x – mx, h – mh.
40. Dx = M [(x– mx)2 ] = M [x 2 – 2x mx +![]() ] = M [x 2] –
] = M [x 2] –
– 2 M [x ]· mx + ![]() = M [x 2] –
= M [x 2] – ![]() .
.
Величина
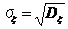
называется среднеквадратическим отклонением (СКО) случайной величины x . Очевидно, sx имеет тот же смысл, что и Dx – характеризует разброс случайной величины относительно центра с учетом возможных значений и их вероятностей. СКО имеет ту же физическую размерность, что и случайная величина x.
§ 5. Закон распределения и числовые характеристики непрерывной случайной величины
Мы знаем, что закон распределения дискретной случайной величины x задается таблицей, в которой перечислены ее возможные значения и указаны их вероятности. Для непрерывных случайных величин задание закона распределения в виде такой таблицы невозможно, так как в этом случае вероятности отдельных значений равны нулю.
Пример.
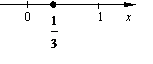 Испытание: берут наугад точку x на числовой оси так, что значения на отрезке [0, 1] равновозможны, остальные значения невозможны. Очевидно, x – непрерывная случайная величина.
Испытание: берут наугад точку x на числовой оси так, что значения на отрезке [0, 1] равновозможны, остальные значения невозможны. Очевидно, x – непрерывная случайная величина.
Найдем
![]() .
.
Закон распределения непрерывной случайной величины может быть задан двумя способами:
1. с помощью функции распределения F (x);
2. с помощью плотности вероятности f (x).
Функция распределения
Пусть с испытанием связана непрерывная случайная величина x.
![]() Зафиксируем произвольное число х. В зависимости от случая возможны три исхода испытания:
Зафиксируем произвольное число х. В зависимости от случая возможны три исхода испытания:
x > x, x = x, x < x.
Каждое из этих трех событий случайно, поэтому имеет смысл говорить об их вероятности. Обозначим
F (x) = p (x < x).
Функция F(x) называется функцией распределения случайной величины x.
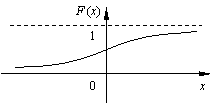 |
Рис. 11
свойства функции распределения
10. 0 ≤ F (x) ≤ 1;
20. F (x) монотонно не убывает (рис. 11);
30. F (– ¥) = 0, F (+ ¥) = 1;
40. P (a<x< b) = F (b) – F (a).
доказательство.
1. Это свойство вытекает из того, что вероятность любого события есть число, принадлежащее [0, 1].
2. Это свойство вытекает из того, что при увеличении х интервал ( – ¥, х) расширяется, поэтому вероятность попадания в этот интервал не уменьшается.
![]() 3. F (– ¥)
3. F (– ¥) ![]() ,
,
F (+ ¥) ![]() .
.
![]() 4. Имеем:
4. Имеем:
F (b) = P (x < b) = ![]() =
=
= P (x < a) + P (x = a) + P (x Î (a, b)) = F (a) + 0 + P (a<x< b).
Отсюда вытекает требуемое равенство 40.
Замечание. Функция распределения F (x) имеет смысл и для дискретных случайных величин. Например, функция распределения случайной величины
x : ![]()
представляет собой кусочно-постоянную функцию, график которой изображен на рис. 12 (кружок означает, что в этом месте отсутствует точка на графике).
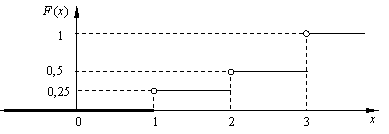 |
Рис. 12
Проверим это для случаев х >3, 2≤ х< 3. В первом случае имеем
F (x) = P (x < x) = P (x = 1 или x = 2 или x = 3) =
= P (x = 1) + P (x = 2) + P (x = 3) = 0,25 + 0,25 + 0,5 = 1.
Во втором случае
F (x) = P (x = 1 или x = 2) = Р (x = 1) + Р (x = 2) =
= 0,25 + 0,25 = 0,5.
Оставшиеся случаи 1≤ х< 2, x<1 предлагаем рассмотреть самостоятельно.
Плотность вероятности
![]() [ ] Пусть с испытанием связана непрерывная случайная величина x.
[ ] Пусть с испытанием связана непрерывная случайная величина x.
Плотностью вероятности случайной величины x в точке х называется предел отношения вероятности попадания в отрезок [x, x + Dx] к длине отрезка Dx при условии, что отрезок стягивается к точке х:
![]() .
.
Нестрого говоря, плотность вероятности – это вероятность попадания в отрезок длины 1.
Свойства плотности вероятности:
10. f (x) ≥ 0 при всех х.
20. P (x Î (a, b)) = 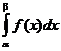
вероятность попадания в интервал равна заштрихованной площади (рис. 13).
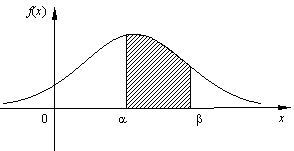 |
Рис. 13
30. Площадь S бесконечной фигуры, ограниченной графиком плотности f (x) и осью абсцисс, равна 1 (рис. 13): S = 1.
Доказательство.
1. Это свойство вытекает из того, что предел неотрицательной функции неотрицателен.
2. Имеем
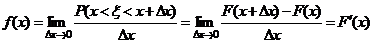 .
.
Отсюда получаем
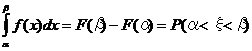 ;
;
учтено свойство 40 функции распределения.
3.  .
.
Помнить: кривая плотности вероятности показывает, как суммарная вероятность 100% распределяется по интервалам.
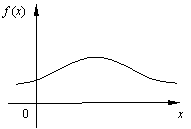
Замечание. Рассмотрим два крайних случая (рис.14, 15). В первом случае с вероятностью, близкой к единице, случайная величина x принимает значения, близкие к х0, в этом случае можно без большой погрешности считать, что x - неслучайная величина: x » х0. Во втором случае суммарная вероятность 100% приблизительно равномерно распреде-лена по широкому спектру возможных значений, то есть в этом случае x сильно случайная величина.
 |
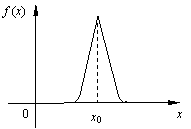 |
Рис. 14 Рис. 15
Связь между f (x) и F(x)
Пусть с испытанием связана непрерывная случайная величина x с плотностью вероятности f (x) и функцией распределения F (x). Справедливы равенства
10. 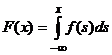 ;
;
20. 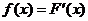 .
.
доказательство.
1. 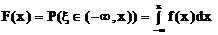 по свойству плотности вероятности.
по свойству плотности вероятности.
2. Это свойство было доказано выше (см. доказательство свойства 20 плотности).
Пример. Берут наугад точку x на оси так, что значения на [0, 1] равновозможны, а остальные невозможны. Найти: а) функцию распределения F(x); б) плотность вероятности f(x).
![]() Решение. а) F(x) – ? [ ]
Решение. а) F(x) – ? [ ]
Пусть
1. х ≤ 0: F (x) = P (x < x) = 0.
2. 0 < x≤ 1: F (x) = P (x < x) = P ( – ¥ < x≤ 0 или 0 < x < x) =
= P( – ¥ < x ≤ 0) + P (0 < x < x) = 0 + ![]() = x.
= x.
3. x > 1: F (x) = P (x < x) = P (x≤ 0 или 0 < x ≤ 1 или 1 <x < x) =
|

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
