


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
рис.27
1) разделим отрезок ![]() на некоторое число m интервалов одинаковой длины
на некоторое число m интервалов одинаковой длины ![]() .
.
2) подсчитаем число элементов выборки, попадающих в каждый интервал:
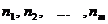 (41)
(41)
Очевидно, ![]() .
.
Числа (41) называются частотами попадания в интервал.
3) составим таблицу
Таблица 1
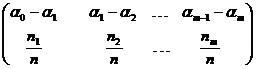 .
.
Элементы второй строки называются относительными частотами попадания в интервал.
Очевидно, ![]() .
.
Эта таблица называется выборочным распределением случайной величины ![]() .
.
4) изобразим выборочное распределение на графике
![]() f* (x)
f* (x)
 | |
|
 . . .
. . .

х
![]()
![]()
![]() . . .
. . . ![]()
![]()
рис. 28
За единицу масштаба на оси абсцисс примем длину интервала ![]() . Очевидно, площадь построенной ступенчатой фигуры равна единице.
. Очевидно, площадь построенной ступенчатой фигуры равна единице.
Построенный график называется гистограммой относительных частот и представляет собой выборочный аналог плотности вероятности случайной величины.
§ 3. Выборочная функция распределения
Построим выборочный аналог функции распределения F (x).
Для этого вначале на каждом интервале (рис.27) выберем середину ![]() и составим таблицу.
и составим таблицу.
Таблица 2
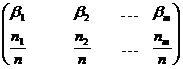 .
.
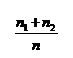
![]()
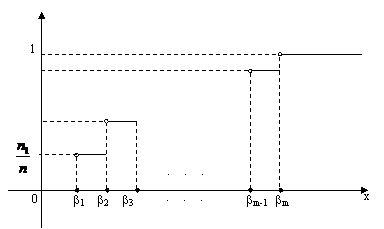

рис. 29
На оси ординат откладываем накопленные относительные частоты. Кружочки на графике означают, что соответствующие точки выброшены.
Можно доказать, что при достаточно большом объеме выборки и при достаточно мелком делении интервалов с практической достоверностью ![]() близка к истинной функции распределения F (x).
близка к истинной функции распределения F (x).
§ 4. Выборочные оценки параметров случайной величины. Основные требования к оценкам
Для выполнения инженерных расчетов, связанных с прогнозированием по массовым случайным явлениям и основанных на методах теории вероятностей, необходимо знать параметры случайных величин, участвующих в этих расчетах: математическое ожидание, дисперсию и т. д.
На практике эти параметры находятся приближенно по данным опыта.
Пусть с испытанием связана случайная величина ![]() с неизвестным параметром
с неизвестным параметром ![]() , и пусть в результате серии независимых испытаний получена выборка (40). В качестве приближенного значения параметра
, и пусть в результате серии независимых испытаний получена выборка (40). В качестве приближенного значения параметра ![]() принимают надлежащим образом выбранную комбинацию элементов выборки (40).
принимают надлежащим образом выбранную комбинацию элементов выборки (40).
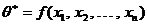 .
.
Величина ![]() называется выборочной оценкой параметра
называется выборочной оценкой параметра ![]() .
.
К выборочным оценкам предъявляются следующие три основных требования: состоятельность, несмещенность, эффективность.
Чтобы были понятны даваемые далее определения этих понятий, обратим внимание на следующее: до выполнения испытаний числа (40) представляют собой независимые случайные величины, подчиненные одному и тому же закону распределения, совпадающему с законом распределения случайной величины ![]() , поэтому
, поэтому ![]() также является случайной величиной, и имеет смысл говорить о математическом ожидании, дисперсии, СКО и т. д. случайной величины
также является случайной величиной, и имеет смысл говорить о математическом ожидании, дисперсии, СКО и т. д. случайной величины ![]() .
.
1. Оценка ![]() называется состоятельной, если при неограниченном увеличении объема выборки
называется состоятельной, если при неограниченном увеличении объема выборки ![]() сходится по вероятности к истинному значению параметра
сходится по вероятности к истинному значению параметра ![]() :
:
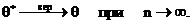
Это означает: при достаточно большом объеме выборки с практической достоверностью (с вероятностью, близкой к единице) ![]() практически совпадает с истинным значением
практически совпадает с истинным значением ![]() .
.
2. Оценка ![]() называется несмещенной, если ее математическое ожидание совпадает с истинным значением параметра
называется несмещенной, если ее математическое ожидание совпадает с истинным значением параметра ![]() :
: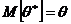 .
.
3. Оценка ![]() называется эффективной, если она несмещенная и при этом имеет наименьшую дисперсию (наименьший разброс относительно
называется эффективной, если она несмещенная и при этом имеет наименьшую дисперсию (наименьший разброс относительно ![]() ) по сравнению с другими несмещенными оценками параметра
) по сравнению с другими несмещенными оценками параметра ![]() .
.
§ 5. Состоятельные несмещенные оценки для математического ожидания, дисперсии, ковариации
Пусть с испытанием связана случайная величина ![]() с неизвестными числовыми характеристиками (а, D) и пусть набрана независимая выборка (40).
с неизвестными числовыми характеристиками (а, D) и пусть набрана независимая выборка (40).
В дальнейшем будем употреблять следующий удобный термин: любую функцию ![]() от выборки (40) будем называть статистикой.
от выборки (40) будем называть статистикой.
Лемма 1. Статистика
![]() (42)
(42)
является состоятельной несмещенной оценкой математического ожидания а.
Доказательство. 1. Мы знаем, что элементы выборки (40) являются независимыми случайными величинами с одним и тем же законом распределения, совпадающим с законом распределения случайной величины ![]() , а значит, имеют те же числовые характеристики (а, D).
, а значит, имеют те же числовые характеристики (а, D).
По теореме Чебышева среднее арифметическое независимых случайных величин с одинаковыми параметрами (а, D), при неограниченном возрастании числа слагаемых сходится по вероятности к общему математическому ожиданию

что и означает состоятельность оценки.
2. Имеем
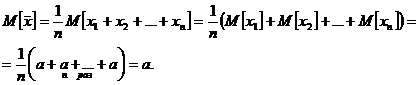
Это означает несмещенность оценки ![]() .
.
Лемма 2. Статистика
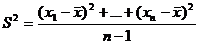 (43)
(43)
является состоятельной несмещенной оценкой дисперсии D. Доказывается аналогично лемме 1.
Замечание 1. Если в формуле (43) заменить (n - 1) на n , то оценка останется состоятельной, но будет смещенной. Величина S2 называется исправленной дисперсией.
Замечание 2. Из леммы 2 следует, что статистика:
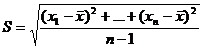
является состоятельной оценкой для СКО 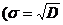 ). Можно доказать, что
). Можно доказать, что ![]() , т. е. оценка S является смещенной оценкой для
, т. е. оценка S является смещенной оценкой для ![]() .
.
Пусть по данным опыта получим ряд значений случайной точки (![]() ) (выборка):
) (выборка):
(х1, у1) (х2, у2), …, (хn, уn).
Справедлива следующая
Лемма 3. Состоятельной несмещенной оценкой для cov(![]() ) является выборочная ковариация
) является выборочная ковариация
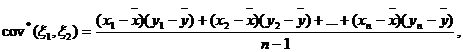 где
где ![]()
§ 6. Два распределения, связанные с нормальным законом
Сформируем два результата, которые понадобятся далее.
Теорема 1. Пусть случайные величины ![]() независимы и нормальны с параметрами (0,1), тогда случайная величина
независимы и нормальны с параметрами (0,1), тогда случайная величина ![]() подчинена закону распределения с плотностью вероятности
подчинена закону распределения с плотностью вероятности
![]()
Рис.30
– распределение (Пирсона)
Теорема 2. Пусть случайные величины ![]() независимы и нормальны с параметрами (0,1), тогда случайная величина
независимы и нормальны с параметрами (0,1), тогда случайная величина
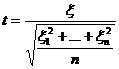
подчинена закону распределения с плотностью
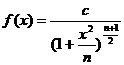

рис.31
t – распределение (Стьюдента)
В обоих случаях константа С подобрана так, чтобы площадь под графиком плотности была равна 1.
Число n называется числом степеней свободы.
§ 7. Квантиль распределения
Пусть имеется случайная величина ![]() с функцией распределения F(x). Будем предполагать, что функция F(x) непрерывна и строго монотонна.
с функцией распределения F(x). Будем предполагать, что функция F(x) непрерывна и строго монотонна.
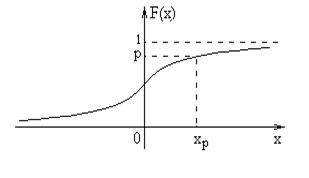
Рис.32
Зададимся числом pÎ (0,1).
Квантилем уровня p распределения F(x) называется корень уравнения F(x) = p, х - ?
Обозначим его ![]() (см. рис.32). Из определения функции F(x) вытекает:
(см. рис.32). Из определения функции F(x) вытекает: ![]() .
.
Нам понадобится далее квантили распределений Пирсона и Стьюдента. Они обозначаются:
![]() ,
, ![]()
Для этих квантилей имеются таблицы.
§8. Доверительные интервалы для математического ожидания и дисперсии
Пусть с испытанием связана случайная величина ![]() с неизвестными числовыми характеристиками (а, D) и пусть по выборке (40) вычислены оценки
с неизвестными числовыми характеристиками (а, D) и пусть по выборке (40) вычислены оценки ![]()
Зададимся числом р в интервале (0,1).
Теорема. В указанной ситуации при достаточно большом объеме выборки с вероятностью р имеют место неравенства
![]() (44)
(44)
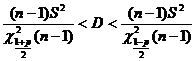 . (45)
. (45)
Интервалы (44), (45) называются доверительными интервалами для математического ожидания и дисперсии. Число р называется уровнем доверия или доверительной вероятностью.
Здесь n-объем выборки, ![]() -квантили распреде-лений Пирсона и Стьюдента.
-квантили распреде-лений Пирсона и Стьюдента.
Указанные интервалы иногда называют интервальными оценками для математического ожидания и дисперсии.
Пример. Выполнена выборка значений случайной величины ![]() объема n = 25 и вычислены состоятельные несмещенные оценки для математического ожидания и
объема n = 25 и вычислены состоятельные несмещенные оценки для математического ожидания и
дисперсии: ![]() Найти доверительные интервалы для математического ожидания и дисперсии с уровнем доверия р = 0,95.
Найти доверительные интервалы для математического ожидания и дисперсии с уровнем доверия р = 0,95.
В силу неравенств (44), (45) с р = 0,95 имеют место интервальные оценки:
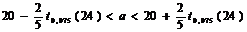 ;
;
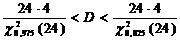 .
.
По таблице квантилей (IV, V) найдем:
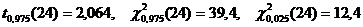 .
.
Подставляя эти значения, получим: с вероятностью 0,95 верны неравенства:
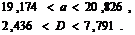
§ 9. Общая схема проверки гипотез по данным опыта
Пусть исследователем выдвинута по некоторым соображениям гипотеза Н и требуется проверить справедливость этой гипотезы по данным опыта.
Укажем правило (схему) проверки гипотезы, разработанную в математической статистике.
Пусть построена статистика (функция от выборки) ![]() со следующим свойством: если гипотеза Н верна, то известен закон распределения случайной величины Z.
со следующим свойством: если гипотеза Н верна, то известен закон распределения случайной величины Z.
1. Задаются малым числом 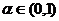 , (например, a = 0,01 или a = 0,05) и находят множество V значений случайной величины Z такое, что
, (например, a = 0,01 или a = 0,05) и находят множество V значений случайной величины Z такое, что
![]() . (46)
. (46)

![]() Z
Z
![]() V
V
2. Производят выборку ![]() и вычисляют значение Z по этой выборке. Обозначим его
и вычисляют значение Z по этой выборке. Обозначим его ![]() .
.
Возможны два случая:
|
|
![]()
![]()
![]()
![]()
![]()
![]()
![]() V
V ![]() V
V
Гипотеза отвергается Гипотеза принимается
Комментарии: В первом случае гипотеза не согласуется с данными опыта, т. к. при этой гипотезе вероятность попадания Z в область V ничтожно мала (46).
В этом случае говорят: расхождение гипотезы с данными опыта значительно.
Во втором случае гипотеза согласуется с данными опыта, т. к. при этой гипотезе вероятность попадания в область ![]() равна
равна 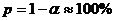 .
.
Расхождение гипотезы с опытом незначимо.
Термины:
V – критическая область;
![]() - область принятия гипотезы;
- область принятия гипотезы;
a - уровень значимости;
![]() - критерий проверки гипотезы.
- критерий проверки гипотезы.
3. На практике критическую область V находят следующим образом. Вычисляют квантиль случайной величины ![]() уровня
уровня 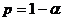 . Тогда V – множество значений Z, больших либо равных
. Тогда V – множество значений Z, больших либо равных ![]() (рис. (33)).
(рис. (33)).
|
![]()
Рис.33
В самом деле, из определения квантиля следует:
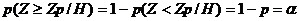 .
.
§ 10. Проверка гипотезы о законе распределения случайной величины по данным опыта
Пусть с испытанием связана случайная величина ![]() с неизвестным законом распределения и пусть по некоторым соображениям выдвинута гипотеза Н:
с неизвестным законом распределения и пусть по некоторым соображениям выдвинута гипотеза Н: ![]() имеет закон распределения
имеет закон распределения 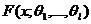 , где
, где ![]() – неизвестные параметры.
– неизвестные параметры.
Например, пусть гипотеза Н состоит в том, что случайная величина ![]() нормальна:
нормальна:
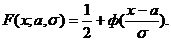
Укажем правило проверки гипотезы о законе распределения, принадлежащее Пирсону. Для этого построим критерий ![]() , т. е. такую статистику, для которой закон распределения известен при условии, что исходная гипотеза верна.
, т. е. такую статистику, для которой закон распределения известен при условии, что исходная гипотеза верна.
1 2 … m
![]()
![]()
![]()
![]() 1.
1.
![]()
![]()
Разделим отрезок 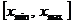 на m интервалов одинаковой длины
на m интервалов одинаковой длины 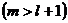 . Обозначим
. Обозначим 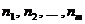 - частоты попадания элементов выборки в эти интервалы.
- частоты попадания элементов выборки в эти интервалы.
2. Обозначим ![]() - состоятельные оценки неизвестных параметров
- состоятельные оценки неизвестных параметров ![]() . Тогда гипотетическая функция распределения случайной величины имеет вид:
. Тогда гипотетическая функция распределения случайной величины имеет вид:
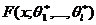 . (47)
. (47)
3. Вычислим вероятности ![]() попадания
попадания ![]() в эти интервалы по формуле:
в эти интервалы по формуле:
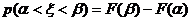 ,
,
где F(x) – функция (47).
4. Построим статистику Z по формуле:
![]() . (48)
. (48)
Критерий (48) был построен Пирсоном.
Теорема. Если гипотеза Н верна, то при достаточно большом объеме выборки случайная величина (48) подчинена приближенно закону распределения Пирсона ![]() с
с 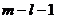 степенями свободы.
степенями свободы.
Из этой теоремы и указанной выше схемы проверки гипотезы вытекает следующее правило проверки гипотезы о законе распределения:
1. Задаются уровнем значимости ![]() и вычисляют квантиль
и вычисляют квантиль ![]() .
.
2. Выполняют выборку ![]() и по формуле (48) вычисляют
и по формуле (48) вычисляют ![]() .
.
3. Если
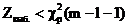 , гипотеза принимается.
, гипотеза принимается.
Если
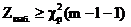 , гипотеза отвергается.
, гипотеза отвергается.
§ 11. Ошибки первого и второго рода. Мощность критерия
При проверке гипотез по указанному правилу возможны ошибки двух типов:
1. Ошибка первого рода: отвергается верная гипотеза. Вероятность этой ошибки равна уровню значимости a. Действительно, из определения a имеем:
![]() Р (ошибки 1-го рода)=
Р (ошибки 1-го рода)= ![]()
2. Ошибка второго рода: принимается неверная гипотеза. Вероятность этой ошибки обозначают b:
Р (ошибки второго рода)= 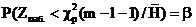 .
.
В конкретной ситуации эта вероятность может быть вычислена.
В математической статистике доказывается: при фиксированном объеме выборки уменьшение уровня значимости a влечет увеличение b и обратно, уменьшение b влечет увеличение a.
Единственный способ уменьшения одновременно a и b - это увеличение объема выборки.
В конкретных ситуациях можно минимизировать вероятность той ошибки, которая ведет к менее тяжелым последствиям. Рекомендуется, если это возможно, проводить проверку более одного раза (набрать хотя бы еще одну выборку).
3. Мощностью критерия называется вероятность отвергнуть неверную гипотезу:
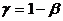 , где
, где
b - вероятность ошибки второго рода.
§ 12. Метод наименьших квадратов (МНК)
Напомним, что в классическом анализе изучаются жесткие или функциональные зависимости между величинами. В теории вероятностей и математической статистике изучаются слабые статистические зависимости. Изложим часто применяемый метод изучения слабых зависимостей по данным опыта – МНК.
Пусть изучается зависимость величины у от величины х.
1. Набирают выборку значений пары (х, у)
![]() . (49)
. (49)
2. Задаются видом зависимости у(х). Например, ищут у в виде многочлена некоторой степени с неизвестными коэффициентами
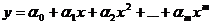 . (50)
. (50)
Задача состоит в подборе коэффициентов a0, a1,…, am так, чтобы формула (50) в некотором смысле хорошо согласовывалась с данными опыта (49).
3. В качестве меры расхождения между формулой (50) и данными опыта (49) принимается следующая величина
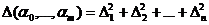 ,
,
где
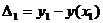 ,
,
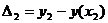 ,
,
……….
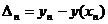 .
.
Разности ∆1,…., ∆n называются невязками.
Если формула (50) точна, то все невязки=0. Таким образом, в качестве меры расхождения между формулой (50) и опытом (49) принята сумма квадратов невязок. Мы пришли к следующей задаче:
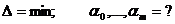
По правилам математического анализа точки экстремума гладкой функции нескольких переменных ищутся из условий:
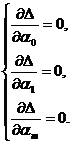 (51)
(51)
Система (51) является системой линейных уравнений относительно ![]() .
.
В теории доказывается, что эта система имеет точно одно решение. Решая эту систему по правилам линейной алгебры и подставляя найденные значения ![]() в формулу (50), получим требуемую приближенную зависимость у(х).
в формулу (50), получим требуемую приближенную зависимость у(х).
Пример. Пусть в результате серии испытаний получена выборка:
х | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
у | 7,4 | 8,4 | 9,4 | 9,4 | 9,5 | 9,5 | 9,4 |
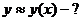
Имеем:
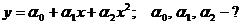
Найдем сумму квадратов невязок:
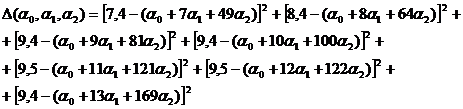
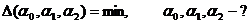
Составляем систему (51). Опуская вычисления, получим:
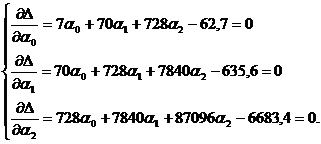
Решая эту систему, получим:
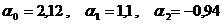 .
.
Тогда искомая зависимость имеет вид:
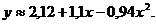
Дополнения
I. Образцы решения типовых задач
Непосредственное вычисление вероятностей
Для непосредственного вычисления вероятности используются ее классическое определение, даваемое формулой (1) и формулами комбинаторики (§2 главы 1).
Пример 1. Автомат, изготавливающий однотипные детали, дает в среднем 6% брака. Из большой партии взята наудачу одна деталь для контроля. Найти вероятность того, что она бракованная.
Решение. Пусть событие А – деталь бракованная. В этом испытании числом всех равновозможных исходов является число всех деталей, изготовляемых автоматом, то есть 100%. Благоприятствовать интересующему нас событию А будут бракованные, то есть m = 6%. Следовательно,
![]() .
.
Пример 2. В группе 20 студентов, среди которых 5 отличников. Произвольно выбрали 10 студентов. Найти вероятность следующего события А: среди выбранных студентов ровно 2 отличника.
Решение. Возможными исходами нашего испытания являются комбинации из 20 студентов по 10, отличающиеся лишь составом, то есть являются сочетаниями, и их число 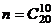 . Интересующему нас событию А будут благоприятствовать только те комбинации, в которых ровно 2 отличника. Поэтому
. Интересующему нас событию А будут благоприятствовать только те комбинации, в которых ровно 2 отличника. Поэтому ![]() . Откуда получаем
. Откуда получаем
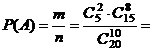
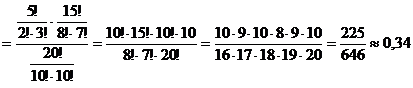 .
.
Пример 3. По условиям лотереи "Спортлото 6 из 45" участник лотереи, угадавший 4,5,6 видов спорта из отобранных при случайном розыгрыше 6 видов спорта из 45, получает денежный приз. Найдите вероятность того, что будут угаданы: а) все 6 цифр; б) 4 цифры.
Решение. а) Пусть событие А – угадывание всех 6 видов спорта из 45. Возможными исходами нашего испытания являются комбинации из 45 цифр по 6, отличающиеся составом, то есть являются сочетаниями и их число 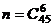 . Интересующему нас событию А благоприятствовать, очевидно, будет одна комбинация, то есть m = 1. Поэтому
. Интересующему нас событию А благоприятствовать, очевидно, будет одна комбинация, то есть m = 1. Поэтому
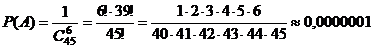 .
.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
