


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
 (21)
(21)
Последнее равенство является необходимым и достаточным условием независимости x1, x2.
Отметим, что функция распределения F(х, у) имеет смысл и в дискретном случае. В непрерывном случае при изучении совместных свойств случайных величин, как правило, удобнее пользоваться плотностью вероятности f(х, у).
Пример. Случайная точка (x1, x2) равномерно распределена в треугольнике со сторонами: х = 0, y = 0, x + y = 3.
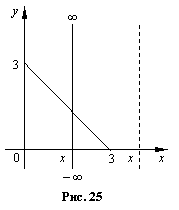
Найти: совместную плотность f(x,y), плотности вероятности f1(x), f2(y) случайных величин x1, x2. Проверить зависимы x1 и x2 или нет.
Решение. Так как случайная точка (x1, x2) равномерно
 распределена в треугольнике AOB (рис. 24), то f (x, y) = const для точек из DАОВ. Тогда, используя свойство 30, имеем
распределена в треугольнике AOB (рис. 24), то f (x, y) = const для точек из DАОВ. Тогда, используя свойство 30, имеем
Sосн · h = 1, следовательно
![]() · h = 1, откуда h =
· h = 1, откуда h = ![]() и
и
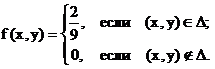
 По формулам (20) находим:
По формулам (20) находим:
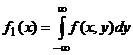 .
.
Если х Ï [0, 3], то f (x, y)=0 (рис.25) и, следовательно, f1 (x) = 0.
Если хÎ [0,3], то f (x, y) = ![]() , откуда
, откуда 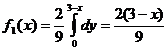 .
.
Окончательно,
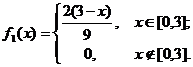
аналогично,
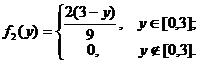
Так как f1(x) · f2 (y) ¹ const, то равенство (21) не выполняется, следовательно x1, x2 статистически зависимы.
§3. Ковариация двух случайных величин. Коэффициент корреляции
1. Пусть с испытанием связаны случайные величины x1,x2 с числовыми характеристиками (а1,s1), (а2,s2). Ковариацией случайных величин x1, x2 называется число
cov (x1, x2) = M [(x1 – a1) (x2 – a2)].
Из определения следует: в дискретном случае
![]() (22)
(22)
в непрерывном случае
cov (x1, x2) = ![]() . (23)
. (23)
Укажем основные свойства ковариации.
10. cov (x, x) = dx.
20. cov (x1, x2) = M [x1, x2]-а1а2.
30. Если x1, x2 независимы, то cov (x1, x2)=0.
40. |cov (x1, x2) | ≤ s1· s2 .
50. Если в 40 имеет место равенство: |cov(x1,x2)| =s1· s2, то между x1,x2 имеется линейная функциональная связь:
Аx1 + Вx2 + С = 0 при некоторых А, В,С.
Геометрически это означает, что реализации случайной точки (x1, x2) с достоверностью ложатся на прямую Ах + By + С = 0.
Докажем свойства 10 – 40.
1. cov (x, x)= M [(x – a) (x – a)]= dx.
2. cov (x1, x2) = M [(x1x2– a1x2 – a2x1 + a1a2] =M [x1·x2] – a1M [x2] – a2M [x1] + a1 · a2 = M [x1 · x2] – a1 · a2 – a2· a1 + a1 · a2 = M [x1 · x2] – a1 · a2.
3. Из независимости x1,x2 следует независимость случайных величин x1–a1, x2–a2. Так как математическое ожидание произведения независимых случайных величин равно произведению их математических ожиданий, то имеем
cov (x1, x2) = M (x1 – a1) M (x2 – a2)=(M[x1]– a1) (M[x2]– a2)= =(a1 – a1)( a2 – a2)=0.
4. Доказательство этого свойства проведем для непрерывного случая. Представим указанную в начале параграфа интегральную формулу для ковариации в виде
![]()
где обозначено
![]()
(для удобства записи пределы интегрирования опущены). Воспользуемся известным фактом математического анализа-неравенством Буняковского: для любых непрерывных φ1, φ2 и любой области D
![]()
Отсюда следует:
![]()
Имеем:
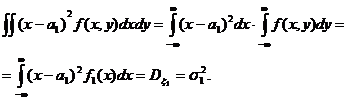
В этом вычислении учтено свойство 50 плотности вероятности f(х, у) и определение дисперсии непрерывной случайной величины. Аналогично найдем
![]()
Таким образом
![]()
что и требовалось.
2. На практике при изучении совместных свойств случайных величин, как правило, пользуются нормированной ковариацией или коэффициентом корреляции:
![]() (24)
(24)
Из свойств ковариации вытекают следующие свойства коэффициента корреляции.
≤ r ≤ 1.
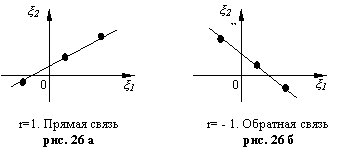
20. Если r = ± 1, то между x1, x2 имеется линейная функциональная связь (рис.26). Уравнение прямой вычисляется по параметрам (а1, а2, σ1, σ2, r).
30. Если x1, x2 независимы, то r = 0.
Замечание 1. Из 10-30 следует, что коэффициент корреляции (и, соответственно, ковариации) является некой мерой связи между x1, x2. Более подробные рассмотрения показывают следующее. Если ׀ r׀ » 1, то связь между x1, x2 близка к линейной функциональной: реализации случайной точки (x1,x2) с практической достоверностью ложатся вблизи заранее прогнозируемой прямой Ах + By + С = 0. Если r » 0, то либо x1, x2 независимы, либо связь между ними имеется, но далека от линейной связи.
Помнить: коэффициент корреляции является мерой линейной связи между случайными величинами.
Замечание 2. В силу свойства 30 из независимости случайных величин x1,x2 следует r=0. Обратное утверждение неверно: имеются примеры, когда r=0 и при этом x1, x2 зависимы. Укажем важный частный случай, когда из r = 0 следует независимость x1, x2. Будем говорить, что случайные величины x1,x2 имеют совместное нормальное распределение с параметрами (а1, σ1, а2, σ2, r), если плотность вероятности случайной точки (x1, x2) дается формулой
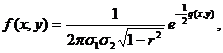 (25)
(25)
где
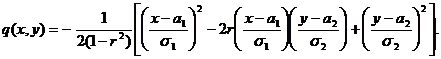 Можно показать, что а1, а2 – математические ожидания, σ1, σ2 – СКО случайных величин x1, x2, r- коэффициент корреляции.
Можно показать, что а1, а2 – математические ожидания, σ1, σ2 – СКО случайных величин x1, x2, r- коэффициент корреляции.
![]() (26)
(26)
где
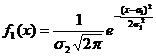 ,
, 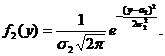
Нетрудно показать, используя свойство 50 плотности вероятности f(x,y), что f1(x), f2(y) – плотности вероятности случайных величин x1, x2; поэтому в силу свойства 60 f(x,y) x1, x2 независимы.
Помнить: в нормальном случае коэффициент корреляции является точной мерой связи между x1, x2.
Замечание 3. Числа (а1, σ1, а2, σ2, r) называются числовыми характеристиками случайной точки (x1, x2). Пары (а1, σ1), (а2, σ2) характеризуют отдельно x1, x2; r является мерой связи между x1, x2. В непрерывном случае параметр r вычисляется по формулам (23), (24), остальные параметры – по формулам
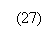
![]()
![]()
![]()
![]()
Пример 1. Найти числовые характеристики случайной точки (x1, x2) в ситуации примера на стр.57.
Решение. Имеем
![]() s1 = s2 =
s1 = s2 = ![]() .
.
Коэффициент корреляции найдем по формулам (22), (24) с учетом свойства 20 для ковариации. Имеем
M [x1 · x2] = ![]() =
=
![]() откуда
откуда
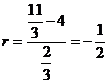 .
.
Пример 2. Найти числовые характеристики случайной точки (x1, x2) в ситуации примера на стр. 60.
Решение. Имеем
а1 = а2 = 1, D1 = D2 = ![]() , s1 = s2 =
, s1 = s2 = ![]() .
.
Коэффициент корреляции найдем по формулам (23), (24)
cov (x1, x2) = ![]()
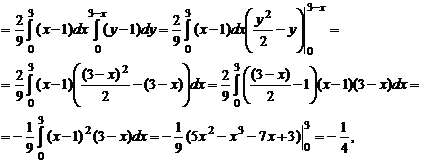 откуда
откуда
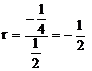 .
.
§4. Совместное распределение нескольких случайных величин. Многомерный нормальный закон
Пусть с испытанием связаны n случайных величин x1, x2,….,ξn. Укажем кратко, как введенные в этой главе понятия переносятся на этот случай.
1. Совместной функцией распределения случайных величин x1, x2,….,ξn называется функция
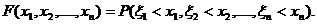
Совместной плотностью вероятности случайных величин x1, x2,….,ξn называется функция
![]() Имеет место равенство
Имеет место равенство
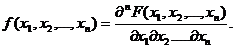
2. Обозначим аi, σj математическое ожидание и СКО случайной величины ξi, кij – ковариацию случайных величин ξi, ξj:
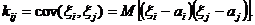
Матрица
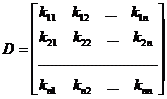
называется дисперсионной матрицей случайных величин x1, x2,….,ξn. Отметим следующие свойства матрицы D.
10. Элементы главной диагонали матрицы D – дисперсии случайных величин x1, x2,….,ξn:
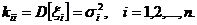
20. Матрица D симметрическая: kij=kji.
30. Собственные числа матрицы D неотрицательны.
Свойства 10, 20 очевидны. Предлагаем читателю проверить свойство 30 для частного случая n=2. В этом случае матрица D имеет вид
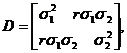 (28)
(28)
где r – коэффициент корреляции случайных величин x1, x2.
3. В §3 этой главы было введено понятие совместного нормального распределения случайных величин x1, x2 – см. формулу (25). Это понятие обобщается следующим образом. Говорят, что случайные величины x1, x2,….,ξn имеют совместное нормальное распределение, если совместная плотность вероятности дается формулой
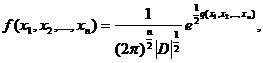
где ![]() - определитель дисперсионной матрицы D,
- определитель дисперсионной матрицы D,
![]()
сij – элементы матрицы C=D-1.
Нетрудно проверить, что в частном случае n=2 это определение совпадает с определением (25); для этого нужно воспользоваться формулой (28) для матрицы D и формулой обращения матрицы второго порядка с отличным от нуля определителем:
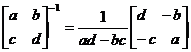
(предлагаем читателю выполнить проверку самостоятельно).
Справедливы утверждения: если x1, x2,….,ξn имеют совместное нормальное распределение, то каждая из них отдельно также нормальна; если каждая ξi нормальна и при этом x1, x2,….,ξn независимы, то их совместное распределение также нормально, и имеет место формула
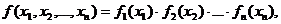
где fi(x) – плотность вероятности ξi. В общей ситуации из нормальности каждой отдельно ξi не вытекает нормальность совместного распределения.
Понятие совместного нормального распределения играет важную роль в приложениях теории вероятностей.
Глава 5. Закон больших чисел. Предельные теоремы
Под законом больших чисел понимают закономерности в массовых случайных явлениях, когда взаимодействие большого числа случайных факторов приводит к неслучайному результату. Пример закономерности такого типа приведен во введении: доля наступления случайного события в длинной серии независимых одинаковых испытаний практически неслучайна. Другой замечательный пример: оказывается, в ряде случаев закон распределения суммы большого числа случайных слагаемых не зависит от законов распределения слагаемых и может быть предсказан! Назначение предельных теорем теории вероятностей: дать строгие формулировки и обоснования различных форм закона больших чисел. В этой главе мы кратко рассмотрим результаты такого типа.
§1. Закон больших чисел в форме Чебышева
На практике хорошо известна следующая закономерность, которую можно сформулировать так: среднее арифметическое большого числа независимых однотипных случайных факторов практически неслучайно. Например, среднее арифметическое большого числа измерений одной и той же величины практически не отличается от истинного значения этой величины; средняя кинетическая энергия большого числа хаотически движущихся молекул практически неслучайна и характеризует температуру тела.
Методы теории вероятностей позволяют дать строгую математическую формулировку этого закона.
Пусть имеется бесконечная последовательность случайных величин
x1, x2, … , xn, … (29)
Будем кратко называть случайные величины (29) однотипными, если они имеют одно и тоже математическое ожидание а и одну и туже дисперсию D.
Теорема. Пусть случайные величины (29) однотипны и независимы, тогда имеет место соотношение
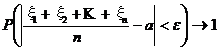 при n ® ¥, (30)
при n ® ¥, (30)
где а = М [xk], k = 1, 2, …, e – любое как угодно малое положительное число.
Это означает: при достаточно большом n с практической достоверностью (с вероятностью » 100%) выполняется равенство
![]() .
.
Эта теорема впервые была доказана русским математиком . Доказательство теоремы основано на трех леммах.
Лемма 1. Пусть случайная величина h≥ 0. Тогда справедливо неравенство
Р (h≥ D) ≤ ![]() , (31)
, (31)
где D – любое положительное число.
Доказательство проведем для непрерывной случайной величины. Плотность вероятности случайной величины h f (х) = 0 при х < 0, так как h≥ 0.
По определению математического ожидания имеем:
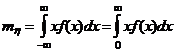 ≥
≥ 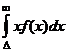 ≥
≥ 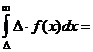
![]() (h≥ D),
(h≥ D),
откуда следует неравенство (31).
Лемма 2. Пусть x – случайная величина с числовыми характеристиками (а, D), тогда справедливо неравенство:
Р (| x – a| <e ) ≥ 1 – ![]() .
.
Доказательство. Имеем
Р (| x – a| ≥ e ) = P ((x – a)2 ≥ e 2) ≤ ![]() .
.
Здесь использовано неравенство (31) при h = (x – a)2, D = e 2.
Из полученного неравенства следует
Р (| x – a| <e ) = 1 – Р (| x – a| ≥ e ) ≥ 1 – ![]() .
.
Лемма 3. Пусть x1, x2, …, xn - независимые однотипные случайные величины с числовыми характеристиками (а, D). Тогда при любом e>0 справедливо неравенство
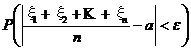 ≥ 1 –
≥ 1 – ![]() . (32)
. (32)
где e – любое положительное число, a = M [xi], D = D [xi], i = 1, 2, …, n..
Неравенство (32) называется неравенством Чебышева.
Доказательство. Обозначим
![]() .
.
Из свойств математического ожидания и дисперсии для независимых случайных величин следует:
![]()
![]()
Таким образом, случайная величина ![]() имеет числовые характеристики
имеет числовые характеристики ![]() ; применяя к ней лемму 2, получим требуемое неравенство (32).
; применяя к ней лемму 2, получим требуемое неравенство (32).
Доказательство теоремы Чебышева.
В силу неравенства Чебышева (32) имеем при любом n двойное неравенство
1 ≥ ≥ 1 – ![]() .
.
Переходя к пределу при n ® ¥ и учитывая теорему сравнения из теории пределов, получим требуемое соотношение (30).
Замечание. Введем удобный термин. Пусть имеется последовательность случайных величин
h1, h2, …, hn, … . (33)
Говорят, что последовательность (33) сходится по вероятности к неслучайной величине а и пишут
![]() при n ® ¥,
при n ® ¥,
если для любого e > 0 выполняется соотношение
Р (| hn – a| <e ) ® 1 при n ® ¥.
Очевидно, теорема Чебышева может быть сформулирована так: среднее арифметическое независимых однотипных случайных величин при неограниченном увеличении числа слагаемых сходится по вероятности к их общему математическому ожиданию.
Пример. Сколько надо провести независимых равноточных измерений данной величины, чтобы с вероятностью не менее 0,95 гарантировать отклонение среднего арифметического этих измерений от истинного значения величины не более, чем на 1 (по абсолютной величине), если СКО каждого измерения не превосходит 5?
Решение. Пусть xi – результат i-го измерения (i = 1,2,…, n), a – истинное значение измеряемой величины, то есть M [xi] = a при любом i; с учетом равноточности измерений xi имеют одинаковую дисперсию D ≤ 25. В силу независимости измерений xi – независимые случайные величины.
Необходимо найти n, при котором
![]() ≥ 0,95.
≥ 0,95.
В соответствии с неравенством Чебышева (32) данное неравенство будет выполняться, если
1 – ![]() ≥ 1–
≥ 1– ![]() ≥ 0,95, откуда легко найти
≥ 0,95, откуда легко найти
n ≥500 измерений.
§ 2. Теорема Бернулли
В начале курса теории вероятностей было сформулировано: вероятность случайного события есть доля наступления этого события в длинной серии независимых одинаковых испытаний. Укажем строгую математическую формулировку этого утверждения.
Пусть выполняется серия n независимых одинаковых испытаний и при каждом испытании событие А наступает с вероятностью р (схема Бернулли). Обозначим
Wn = | число наступлений события А | . |
n |
Число Wn называется частотой события А в серии из n испытаний.
Теорема. В указанной ситуации при неограниченном возрастании числа независимых испытаний частота случайного события А сходится по вероятности к вероятности этого события:
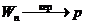 при n ® ¥.
при n ® ¥.
Доказательство. Очевидно, Wn – случайная величина, при этом справедливо равенство
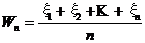 , где
, где
xi – число наступлений события А в i -ом испытании.
Проверим, что случайные величины xi удовлетворяют условиям теоремы Чебышева.
1. x1, x2, … , xn независимы в силу независимости испытаний.
2. Закон распределения случайной величины xi для всех i = 1, …, n имеет вид
xi = 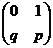 , q = 1 – p. (34)
, q = 1 – p. (34)
Отсюда
M [xi] = p · 1 + 0 · q = p,
D [xi] = p (1 – p)2 + q (0 – p)2 = pq. (35)
Следовательно, случайные величины xi однотипны с числовыми характеристиками: а = р, D = pq.
В силу теоремы Чебышева среднее арифметическое этих случайных величин сходится по вероятности к их общему математическому ожиданию:
![]() при n ® ¥,
при n ® ¥,
что и требовалось.
Замечание 1. Из сказанного выше следует: число успехов (наступлений события А в схеме Бернулли) дается формулой
x= x1+ x2+ … + xn, (36)
где xI – число успехов в i-ом испытании.
Из (35), (36) следует:
M [x] = n p, D [x] = npq. (37)
Таким образом, числовые характеристики биномиальной случайной величины с параметрами (n, p) даются формулами (37).
Замечание 2. Индикатором связанного с испытанием события А называется случайная величина, равная 1, если событие А произойдет и 0, если событие А не произойдет. Очевидно, закон распределения индикатора имеет вид (34), где р – вероятность наступления, q – вероятность ненаступления события А.
§ 3. Центральная предельная теорема
При изучении нормального распределения было сформулировано следующее утверждение: если случайные величины x1, x2, … , xn независимы и нормальны с одними и теми же (а, s), то сумма x1 + x2 + … + xn также нормальна. Оказывается справедливо гораздо более глубокое утверждение: если случайные величины независимы и имеют один и тот же закон распределения (неважно какой), то при достаточно большом числе слагаемых сумма x1 + x2 + … + xn приближенно нормальна. Это утверждение называется центральной предельной теоремой теории вероятности.
Приведем строгую формулировку этой теоремы.
Рассмотрим бесконечную последовательность независимых случайных величин x1, x2, … , xn , … с одним и тем же законом распределения, в частности, с одними и теми же параметрами (а, s).
Сумма первых n случайных величин
x1 + x2 + … + xn (38)
имеет числовые характеристики
M = na, D = ns2 ![]() СКО=s
СКО=s![]() . (39)
. (39)
Обозначим Fn(х) функцию распределения случайной величины (38). Поставим вопрос: как меняется Fn(х) при неограниченном возрастании числа слагаемых?
Функция распределения нормальной случайной величины с числовыми характеристиками (39) имеет вид (см.§5 главы 4)
![]() ,
,
где Ф (х) – функция Лапласса. Справедлива
Теорема. В указанной ситуации имеет место соотношение
![]() при n ® ¥.
при n ® ¥.
Практически это означает: при достаточно большом числе слагаемых сумма (38) независимых случайных величин с одним и тем же законом распределения с большой точностью подчинена нормальному закону с параметрами (na, s![]() ) независимо от закона распределения слагаемых.
) независимо от закона распределения слагаемых.
Пример. Определить вероятность того, что продолжи-тельность 100 производственных операций окажется в пределах от 77 до 82 ч., если среднее время одной операции 47,4с., а среднеквадратическое отклонение – 4,9 с.
решение. Обозначим через xi – случайную величину, равную продолжительности i-ой производственной операции, i = 1, 2, …, 100. Очевидно, по условию а = m = 47, 4 с.,
![]() с. Обозначим через
с. Обозначим через ![]() – случайную величину равную продолжительности 100 производственных операций, тогда
– случайную величину равную продолжительности 100 производственных операций, тогда ![]() = x1 + x2 + … + x100. По условию xi независимые и однотипные случайные величины, следовательно, из центральной предельной теоремы вытекает, что
= x1 + x2 + … + x100. По условию xi независимые и однотипные случайные величины, следовательно, из центральной предельной теоремы вытекает, что ![]() приближенно нормальна,
приближенно нормальна, ![]() ,
, ![]() и по формуле (19) имеем
и по формуле (19) имеем
Р (77 · 60≤ ![]() ≤ 82 · 60) = Р (4620 ≤
≤ 82 · 60) = Р (4620 ≤ ![]() ≤ 4920) =
≤ 4920) =
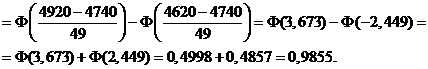
Замечание 1. Эта теорема впервые была доказана в XIXв. немецким математиком Линдебергом. Позднее русским ученым утверждение этой теоремы было значительно усилено: оказалось, что в ней требование одинакового закона распределения слагаемых не обязательно.
Приведем нестрогую формулировку теоремы Ляпунова: если случайные величины x1, x2, … , xn независимы и каждая из них не доминирует над остальными, то при достаточно большом числе слагаемых их сумма приближенно нормальна.
Наиболее общая формулировка центральной предельной теоремы была получена русским ученым в 20-е годы ХХ века.
Замечание 2. Теорема Ляпунова объясняет причину широкого распространения нормального закона. Действи-тельно, в ряде случаев случайные величины представляют собой результат наложения большого числа независимых небольших случайных факторов. Например, на показание измерительного прибора влияет большое число случайных факторов: колебание температуры, влажность и плотность воздуха, небольшие погрешности при изготовлении и эксплуатации прибора и т. д. Эти факторы независимы и каждый из них не доминирует над остальными, поэтому в силу теоремы Ляпунова показания прибора с большой точностью является нормальной случайной величиной.
Замечание 3. Покажем, что приведенная §6 гл.1 формула Муавра-Лапласа (13) является следствием центральной предельной теоремы.
В §2 главы 5 было показано: число успехов в схеме Бернулли может быть представлено в виде суммы (38) независимых случайных величин (индикаторов) с одним и тем же законом распределения и числовыми характеристиками m=np, D=npq.
Из центральной предельной теоремы следует: при достаточно большом числе испытаний число успехов x в схеме Бернулли является с большой точностью нормальной случайной величиной с функцией распределения
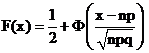 .
.
Откуда получаем
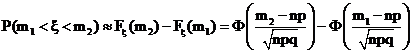
Глава 6. Элементы математической статистики
§ 1. Предмет математической статистики
Математическая статистика – наука о способах получения выводов из данных опыта, полностью опирается на методы теории вероятностей, в этом смысле теория вероятностей является частью математической статистики.
Укажем основные разделы математической статистики.
1. Теория оценок
Эта теория дает подходы к приближенному вычислению параметров случайных величин (матема-тического ожидания, дисперсии, ковариации и т. д.) по данным опыта.
2. Статистическая проверка гипотез
Эта теория дает подходы к проверке справедливости интересующих нас гипотез по данным опыта.
3. Дисперсионный анализ
Эта теория дает подходы к изучению слабых (статистических) зависимостей между величинами.
§ 2. Выборка из генеральной совокупности. Вариационный ряд. Гистограмма относительных частот
Пусть с испытанием связана случайная величина ![]() и пусть в результате серии n независимых испытаний получен набор значений
и пусть в результате серии n независимых испытаний получен набор значений ![]() :
:
![]() . (40)
. (40)
В математической статистике применяются следующие термины. Множество всех возможных значений случайной величины ![]() называется генеральной совокупностью. Набор чисел (40) называется выборкой из генеральной совокупности, число n называется объемом выборки, числа (40) называются элементами выборки. Элементы выборки (40), расположенные в порядке возрастания называются вариационным рядом:
называется генеральной совокупностью. Набор чисел (40) называется выборкой из генеральной совокупности, число n называется объемом выборки, числа (40) называются элементами выборки. Элементы выборки (40), расположенные в порядке возрастания называются вариационным рядом:
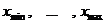 - вариационный ряд.
- вариационный ряд.
Число ![]() называется размахом выборки.
называется размахом выборки.
Выполним следующие построения:
![]()
![]()
![]() . . .
. . . ![]()
![]()
![]()


![]()
![]() . . .
. . . ![]()
![]()

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
