


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Oщ "ai" reprйsente les йlйments du cluster A, et "bj" correspond aux йlйments du cluster B. Ce critиre (formule 3) permet йgalement d’йvaluer la ressemblance entre les deux ensembles mais avec une plus grande flexibilitй.
Premiиrement, le rйsultat du calcul basй sur l’indice classique peut кtre uniquement positif ou nйgatif, comme nous le voyons sur la formule 4,
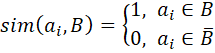
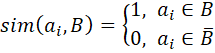 (4)
(4)
puisque nous ne pouvons obtenir +1 que dans le cas oщ le mкme lexиme est prйsent dans les deux ensembles, c’est-а-dire quand l’йlйment ai fait partie de l’ensemble B. Dans toute autre situation ce coefficient sera йgal а 0. Par contre, la valeur du calcul d’aprиs la formule 3 peut varier dans l’intervalle entre 0 et +1 car ce n’est pas le nombre d’unitйs identiques qui est pris en compte mais la similaritй des cosinus entre les vecteurs respectifs.
![]()
![]() (5)
(5)
Comme nous pouvons voir, la proximitй entre les йlйments du cluster A au cluster B (formule 5) est le rйsultat d’йvaluation de valeur de similaritй la plus йlevйe entre chaque paire d’unitйs des deux clusters.
Par consйquent, le deuxiиme critиre peut кtre utilisй pour йtablir le degrй de similaritй entre les clusters en question et pour vйrifier la ressemblance entre chaque paire de mots-clйs.
Deuxiиmement, le premier critиre s’est avйrй trиs sensible au nombre de mots dans les clusters. Cependant, les textes а analyser peuvent avoir une longueur diffйrente et la frйquence d’apparition d’une telle ou telle unitй lexicale peut йgalement varier. En consйquence, il devient difficile de fixer le volume des clusters ce qui constitue une йtape importante de notre travail. Lors des calculs d’aprиs la premiиre formule, nous avons choisi de limiter le nombre d’йlйments dans un cluster а 40, puisqu’avec un nombre infйrieur les erreurs йtaient plus frйquentes, et un nombre supйrieur n’influenзait pas les rйsultats d’une faзon considйrable. De plus, il est dangereux d’augmenter le nombre d’unitйs dans les clusters car il est important de travailler avec les йlйments les plus similaires, et l’extension des clusters impliquera les mots assez йloignйs du terme central.
En ce qui concerne la formule vectorielle, les rйsultats de tels calculs ne dйpendent pas d’une faзon significative du nombre de mots dans les ensembles, et par consйquent, ce critиre permet d’йtablir le degrй de similaritй entre les clusters mкme si les unitйs identiques n’y sont pas prйsentes а un nombre considйrable.
Donc lors de notre projet, nous avons utilisй les deux critиres dйcrits ci-dessus afin de dйterminer d’une faзon automatique le champ thйmatique des textes analysйs et de situer le sens des termes homonymiques interdisciplinaires au sein du domaine biologique ou linguistique afin de choisir une traduction йquivalente en fonction du contexte scientifique.
Ainsi, nous avons йlaborй une mйthode de crйation des clusters comportant les йlйments nominatifs similaires au niveau sйmantique а la base d’une analyse des contextes йlйmentaires. Les reprйsentations vectorielles des unitйs lexicales nous ont permis d’йvaluer l’indice de similaritй entre chaque paire de substantifs via l’estimation de cosinus de l’angle entre deux vecteurs en question, dont les valeurs varient entre -1 et +1. Par consйquent, il est devenu possible de crйer des clusters des unitйs similaires au niveau sйmantique qui constituent une reprйsentation du champ thйmatique auquel appartient tel ou tel texte. Par la suite, nous pourrons йvaluer la ressemblance entre les clusters de nouveaux textes et les clusters originaux а l’aide des indices de similaritйs choisis et faire une supposition sur le domaine auquel appartiennent les documents en question.
II.2. Approbation de la mйthode йlaborйe de dйsambiguпsation des homonymes terminologiques
Aprиs avoir йlaborй un algorithme de l’identification du champ thйmatique des textes via une analyse automatique des associations de similaritй, nous avons testй cette mйthode sur de nouveaux documents afin de vйrifier l’hypothиse de notre projet. La procйdure d’une telle approbation comprend les йtapes suivantes :
Sйlectionner les documents textuels pour vйrifier notre hypothиse; Rйaliser le prйtraitement des textes; Composer les йchantillons de contrфle; Construire les clusters pour chaque йchantillon de contrфle; Identifier le champ thйmatique de tous les textes de contrфle.
Ainsi, nous avons procйdй au traitement des termes homonymiques interdisciplinaires а l’aide d’une analyse de leurs modиles d’emploi dans les textes biologiques et linguistiques que nous avons choisis lors de l’йtape dйcrite ci-aprиs.
II.2.1. Sйlection des documents textuels pour vйrifier notre hypothиse
Notre objectif suivant est de complйter notre corpus avec des textes de contrфle dont les thйmatiques correspondent aux domaines concernйs. Nous avons choisi plusieurs ouvrages biologiques et linguistiques dont un grand nombre a йtй tirй du site de l’archive ouverte pluridisciplinaire “Hyper articles en lignes (HAL)”. C’est une vaste plateforme, crййe au dйbut de XXIиme siиcle par le Centre national de la recherche scientifique, qui donne un accиs libre aux travaux publiйs par des chercheurs franзais et йtrangers (voir les ressources numйriques).
Lors de la validation de notre mйthode, nous nous sommes adressйs йgalement aux textes dйcrits dans la premiиre partie du prйsent travail. Les clusters construits а la base de ces documents ont constituй une sйrie de points de repиres en vue de fixer les thйmatiques des clusters de contrфle.
II.2.2 Rйalisation du prйtraitement des textes
Avant de passer а une construction des clusters thйmatiques, nous avons effectuй un traitement prйalable du corpus qui йtait mis а jour а l’йtape prйcйdente. Nous avons donc dйtectй les termes homonymiques au sein de ces documents ainsi qu’йvaluй la frйquence de leurs apparitions dans chaque texte. Rappelons, que dans la premiиre partie de ce travail nous avons fixй le seuil minimal de frйquence d’utilisation des mots-clйs а 10 pour assurer une certaine fiabilitй de nos calculs.
position des йchantillons de contrфle
A l’йtape suivante, nous avons crйй 482 йchantillons tests, dont 231 comportent les termes dans leurs sens biologiques et 251 sont constituйs autour des termes linguistiques. Les йchantillons sont composйs de plusieurs йlйments. Tout d’abord, chaque йchantillon comprend un terme homonymique. Puis, viennent trois textes oщ ce terme est frйquemment employй, dont deux sont obligatoirement de thйmatiques diffйrentes et constituent les documents de repиres, et le troisiиme est justement un document de contrфle. Ici il convient de prйciser que chaque texte analysй peut figurer а la fois dans plusieurs йchantillons et y jouer le rфle soit d’un repиre soit d’un essai.
Finalement, le dernier йlйment de tout йchantillon est le domaine de rйfйrence. C’est un libellй de la discipline а laquelle appartient effectivement le texte de contrфle ce qui permet de dйfinir le sens du terme en question et de choisir une traduction йquivalente. Ce dernier йlйment a une grande importance puisqu’il permet de vйrifier le rйsultat obtenu avec notre mйthode et d’йvaluer la fiabilitй de nos calculs.
II.2.4. Construction des clusters pour chaque йchantillon de contrфle
Par la suite, nous avons construit les clusters thйmatiques а la base des textes de chaque йchantillon. Par consйquent, au sein de chaque test nous avons trois clusters, dont deux correspondant aux textes de repиres et un correspondant au texte de contrфle. Cela a йtй rйalisй d’aprиs le modиle dйcrit dans les pages prйcйdentes.
Au dйbut, nous avons crйй les reprйsentations vectorielles de tous les mots clйs frйquents dans les textes concernйs. Ensuite, nous avons calculй les cosinus des angles entre chaque paire de vecteurs. A la fin, nous avons conзu les clusters de 40 unitйs les plus similaires avec les termes centraux. Lors de la description des critиres de comparaison des clusters thйmatiques, nous avons apportй une prйcision sur le choix du nombre d’йlйments dans les ensembles.
II.2.5. Identification du champ thйmatique de tous les textes de contrфle
Aprиs avoir construit les clusters, nous avons pu йtablir le degrй de leur similaritй. Une telle comparaison a йtй rйalisйe par le biais des critиres permettant d’йvaluer la ressemblance entre deux ensembles. Dans le cadre de notre projet, nous nous sommes servis de deux formules, celle de l’indice classique de Sшrensen-Czekanowski (formule 2) et celle de l’indice un peu plus adaptй pour rйaliser les opйrations de calcul avec les reprйsentations vectorielles et les valeurs des cosinus (formule 3).
Ainsi, au sein de chaque йchantillon, nous avons comparй le cluster du texte de contrфle avec les clusters thйmatiques des textes de repиres afin de choisir entre ces derniers celui qui comporte les йlйments les plus similaires avec celui de contrфle. En consйquence, nous avons pu identifier le champ thйmatique auquel appartient le cluster en question et choisir la traduction йquivalente.
Considйrons l’exemple d’un fragment du tableau des йchantillons pour le terme “articulation”.
Tableau 7. Echantillons pour le terme “articulation”
№ | terme | textes de rйfйrence | texte de contrфle | valeur de l'indice classique | valeur de l'indice adaptй | |||
B | L | X | I(B, X) | I(L, X) | I'(B, X) | I'(L, X) | ||
95 | articulation | B2 | L1 | B7 | 0.2750 | 0.0750 | 0.5248 | 0.4620 |
96 | articulation | B2 | L1 | L4 | 0.1500 | 0.0500 | 0.3495 | 0.4116 |
97 | articulation | B2 | L9 | L10 | 0.1000 | 0.1250 | 0.2998 | 0.4995 |
98 | articulation | B2 | L4 | B7 | 0.2750 | 0.1750 | 0.5248 | 0.4495 |
99 | articulation | B2 | L4 | L9 | 0.0750 | 0.0500 | 0.4120 | 0.4116 |
100 | articulation | B4 | L4 | L10 | 0.1000 | 0.1250 | 0.2998 | 0.5869 |
101 | articulation | B4 | L10 | B7 | 0.2750 | 0.1000 | 0.5248 | 0.4997 |
102 | articulation | B4 | L10 | L9 | 0.0750 | 0.1250 | 0.4120 | 0.4995 |
103 | articulation | B4 | L10 | L4 | 0.1500 | 0.1250 | 0.3495 | 0.5869 |
104 | articulation | B7 | L9 | B4 | 0.2750 | 0.0750 | 0.5248 | 0.4120 |
105 | articulation | B7 | L9 | L4 | 0.1750 | 0.0500 | 0.4495 | 0.4116 |
106 | articulation | B7 | L9 | L10 | 0.1000 | 0.1250 | 0.4997 | 0.4995 |
107 | articulation | B7 | L4 | B4 | 0.2750 | 0.1500 | 0.5248 | 0.3495 |
108 | articulation | B7 | L4 | L10 | 0.1000 | 0.1250 | 0.4997 | 0.5869 |
109 | articulation | B7 | L10 | B4 | 0.2750 | 0.1000 | 0.5248 | 0.2998 |
110 | articulation | B7 | L10 | L9 | 0.0750 | 0.1250 | 0.4620 | 0.4995 |
111 | articulation | B7 | L10 | L4 | 0.1750 | 0.1250 | 0.4495 | 0.5869 |
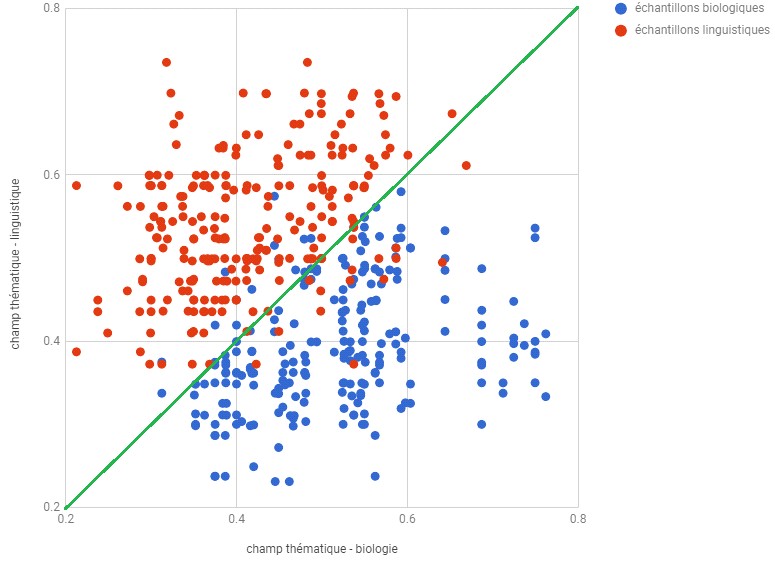
Le tableau 7 prйsente les йchantillons du 95иme au 111иme qui ont йtй construits pour le terme “articulation”. Les textes de rйfйrence des domaines de la biologie (B) et de la linguistique (L) (voir les textes de rйfйrence) sont indiquйs dans la troisiиme colonne. Ensuite dans la colonne “X”, nous voyons les numйros des textes de contrфle qui ont йtй traitйs au sein de chaque йchantillon. Finalement, les deux derniиres colonnes prйsentent les valeurs de l’indice classique (I) et de l’indice adaptй (I’) obtenues suite а l’estimation du degrй de similaritй entre les clusters des textes de contrфle avec ceux des textes de rйfйrence biologiques (B, X) ou linguistiques (L, X).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
