


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Dans chaque paire de rйsultats (B, X) et ( L, X), la valeur supйrieure correspond а une plus grande similaritй entre les clusters concernйs. Les valeurs colorйes en vert dйmontrent que le rйsultat obtenu avec un tel ou tel coefficient s’est avйrй correcte. Les rйsultats erronйs sont marquйs en rouge.
Par exemple comme textes de rйfйrence pour l’йchantillon 103, nous avons pris le 4иme document biologique et le 10иme linguistique. Le 4иme document linguistique a йtй choisi comme texte de contrфle. Ensuite, les clusters thйmatiques pour le terme “articulation” ont йtй construits а la base de chaque texte et comparйs entre eux а l’aide des indices de similaritй. Comme nous pouvons noter, les deux coefficients ont rйvйlйs une plus grande ressemblance entre le cluster de contrфle et celui du texte linguistique ce qui est un rйsultat positif. Regardons les contextes afin de prouver cette estimation :
- B4 : Les os du squelette sont liйs entre eux par des articulations comportant un, deux ou trois degrйs de libertй. L’index, le majeur, l’annulaire et l’auriculaire, appelйs aussi doigts longs, comportent trois articulations… L10 : Pour les consonnes, le lieu d’articulation va des lиvres en avant, jusqu’au pharynx, voire au larynx en arriиre, en passant par les diffйrentes parties du palais et de la langue… L4 : Cette section prйsente donc quatre йtudes, ayant йtй effectuйes chez des sujets sains et dyslexiques, observant la perception du voisement et du lieu d'articulation, de mкme que l'impact de la position du voisement dans la syllabe ou le mot sur la perception des phonиmes.
Dans les deux contextes linguistiques, le terme “articulation” fonctionne au sein du groupe nominal “lieu d’articulation”, et nous pouvons йgalement observer des mots-clйs caractйristiques de ce domaine : “consonne”, “voisement”, “syllabe”, “phonиme”, etc. Pourtant, dans le contexte biologique, le terme en question est utilisй avec de tels mots-clйs que “os”, “squelette”, “auriculaire”, etc.
Ainsi а l’aide de notre mйthode automatique, nous avons pu attribuer le document L4 au champ thйmatique de la linguistique et dйfinir le terme “articulation” dans ce contexte comme “production des йlйments du langage parlй par les modifications provoquйes au passage de l'air expirй, d'aprиs les dispositions des cordes vocales, de la langue, des joues, des dents, des lиvres”. Par consйquent dans cette situation, la traduction йquivalente dans la langue cible sera le terme “артикуляция” et non pas “сустав”.
Cependant pour certains йchantillons, nous pouvons classer les rйsultats comme erronйs. Nous pouvons constater que dans le cas de l’indice classique (I) le nombre d’erreurs s’йlиve а 4 tandis que l’indice adaptй (I’) en donne 2 fois moins. Par la suite, nous prйsenterons la situation gйnйrale pour tout l’ensemble d’йchantillons et analyserons la fiabilitй de chaque indice.
Le tableau 8 prйsente les rйsultats calculйs а l’aide de l’indice basй sur la similaritй entre les reprйsentations vectorielles.
Tableau 8. Rйsultats obtenus via l’indice I’
rйsultats des tests | |||
biologie | linguistique | ||
domaine de rйfйrence | biologie | 217 | 14 |
linguistique | 19 | 232 |
Dans le tableau 8, nous voyons le nombre d’йchantillons analysйs dans chaque discipline avec la prйcision du nombre des rйponses correctes, qui sont marquйes en vert, et des erreurs reзues avec les calculs d’aprиs la formule 3 qui correspond au coefficient adaptй pour le traitement des textes via la construction des reprйsentations vectorielles des unitйs lexicales. La mention “domaine de rйfйrence” indique le domaine auquel les textes traitйs appartiennent effectivement. Par contre, les colonnes “rйsultats des tests” nous prйsentent les rйsultats qui ont йtй obtenus grвce а notre mйthode. Par exemple, nous pouvons constater que notre algorithme a donnй les rйponses fiables pour 217 йchantillons biologiques contre 14 erreurs et pour 232 йchantillons linguistiques contre 19. Donc pour l’indice adaptй de similaritй, dans 449 cas sur 482 le rйsultat s’est avйrй correct, ce qui reprйsente 93%.
Tableau 9. Rйsultats obtenus via l’indice I
rйsultats des tests | |||
biologie | linguistique | ||
domaine de rйfйrence | biologie | 164 | 67 |
linguistique | 76 | 175 |
Le tableau 9 nous prйsente les rйsultats calculйs а l’aide du coefficient classique. Nous pouvons noter que le nombre d’erreurs dans les deux disciplines est considйrablement plus йlevй que celui obtenu avec l’indice prйcйdent. Pour les textes biologiques, le nombre de rйponses correctes, qui sont colorйs en vert, fait 164 sur 231 et pour les textes linguistiques 175 sur 251. Ainsi, dans le cas de la formule classique, 339 rйsultats sont valides sur 482. Donc, nous avons reзu le pourcentage йgale а 70%.
II.3. Interprйtation des rйsultats
II.3.1. Etablissement des fiches terminologiques
A l’йtape de constitution de la liste des termes homonymiques interdisciplinaires, nous avons conзu 80 fiches terminologiques pour tous les concepts reprйsentйs par les unitйs terminologiques extraites. Ces fiches sont conformes aux normes de l’Organisation internationale de normalisation et comportent les donnйes terminologiques regroupйes selon de diffйrents types de catйgories axйes sur le traitement des donnйes terminologiques et traductologiques.
II.3.2. Elaboration de la mйthode automatique de dйsambiguпsation des homonymes terminologiques
Afin d’atteindre le but principal de notre projet, nous avons йlaborй une mйthode d’analyse automatique des relations de proximitй entre les йlйments des corpus textuels. Ainsi, nous avons d’abord proposй un moyen d’extraction des termes homonymiques interdisciplinaires par le calcul de leurs frйquences et l’analyse de leurs dйfinitions. Ensuite, nous avons йlaborй le principe de construction des clusters thйmatiques pour chaque concept reprйsentй par les termes homonymiques а l’aide des reprйsentations vectorielles des mots-clйs et d’une йvaluation de similaritй cosinus entre les vecteurs. Finalement, nous avons choisi deux critиres pour йvaluer la ressemblance entre les clusters de nouveaux documents et des textes de rйfйrence et comparй leurs caractйristiques.
paraison des critиres de similaritй
Afin de vйrifier notre hypothиse sur l’identification du champ thйmatique des documents textuels via une analyse des liens sйmantiques de similaritй entre les unitйs lexicales, nous avons constituй les йchantillons de contrфle pour chaque terme en vue de valider la mйthode йlaborйe dans chaque cas particulier. A l’йtape finale, nous avons gйnйralisй tous ces rйsultats. Nous avons йgalement йvaluй le degrй de similaritй а l’aide de deux indices dйcrits dans les pages prйcйdentes.
Nous avons donc obtenu les rйsultats finals qui tйmoignent de la situation gйnйrale. L’indice adaptй au traitement des textes qui est basйe sur les reprйsentations vectorielles des unitйs lexicales a donnй 93% des rйponses positives tandis que l’indice classique de Sшrensen-Czekanowski qui permet d’йvaluer la similaritй entre les йlйments par la comparaison des symboles identiques a donnй 70% des rйsultats corrects.
Ainsi, nous pouvons constater que notre supposition sur une plus grande fidйlitй des rйsultats dans le cas des calculs avec l’indice adaptй s’est avйrй juste, et que ce critиre est meilleur en vue de la dйsambiguпsation des homonymes terminologiques а l’aide de la mйthode йlaborйe.
II.3.4. Identification du domaine de connaissance et choix de la traduction йquivalente а l’aide des liens sйmantiques de similaritй
Lors de notre projet, nous avons йvaluй le degrй de similaritй entre les clusters construits pour les textes de contrфle et les clusters formйs а la base des textes de rйfйrence, et nous avons vйrifiй si notre analyse automatique avait donnй les rйsultats valides. Finalement, nous avons obtenu 93% des rйponses fiables, ce qui signifie que, dans la majoritй des cas, la mйthode йlaborйe sйlectionne correctement le champ thйmatique des textes et la traduction des termes homonymiques appropriйe au contexte de leur fonctionnement. La reprйsentation graphique 16 permet d’illustrer ces rйsultats.
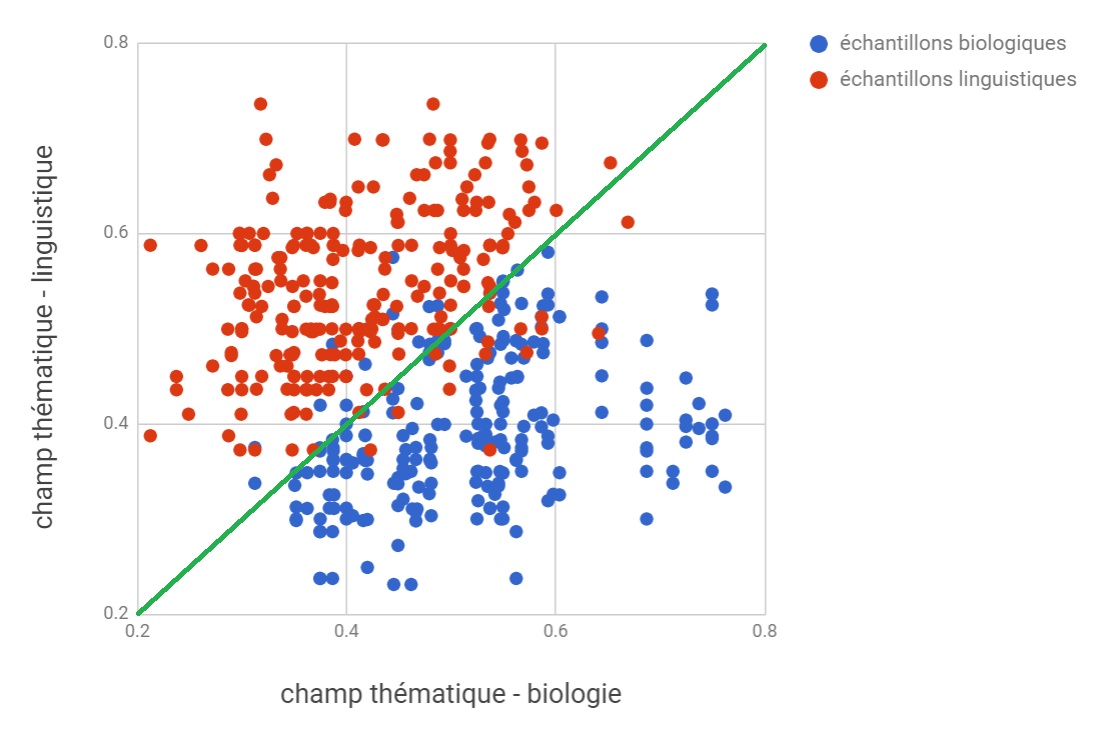
Figure 16. Rйpartitions des йchantillons
Nous pouvons observer sur la figure 16 les йchantillons biologiques qui sont reprйsentйs par les points bleus, les йchantillons linguistiques qui sont reprйsentйs par les points rouges et les deux axes “champ thйmatique - linguistique” et “champ thйmatique - biologie”. Le plan de sйparation vert marque la frontiиre entre les deux disciplines. La proximitй de chaque point par rapport а un tel ou tel axe dйmontre le degrй de similaritй entre le cluster de contrфle et les clusters thйmatiques de rйfйrence а l’intйrieur de chaque йchantillon. Le fait que la plupart des points bleus sont situйs en-dessous du plan de sйparation prouve que notre mйthode a correctement classifiй une grande partie des textes biologiques. La mкme remarque peut кtre faite au regard des textes linguistiques.
Nous voudrions йgalement apporter une prйcision concernant les points bleus localisйs en-dessus de la diagonale et les points rouges qui le sont me nous pouvons remarquer, dans une partie des tests notre algorithme a donnй une fausse rйponse. Cela est dы aux qualitйs des ensembles flous.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 |
