
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Формулы для вычисления Kj могут показаться сложными; в действительности с помощью электронной вычислительной машины средней мощности все вычисления проводятся и печатаются очень быстро (менее часа для 500 коммун). Для подобных вычислений можно использовать, например, машину Гамма ЕТ.
Без вычислительных машин осуществление этого метода становится практически невозможным из-за трудоемкости и дороговизны.
Здесь можно сделать несколько критических замечаний. Реальное богатство коммуны представляется пропорциональным числу ее жителей. Маленькая коммуна, если даже ее жители богаты и коммуна отнесена к богатым, оказывается, очевидно, бедной перед лицом необычных расходов. Поэтому такая классификация не годится в вопросах, которые касаются всего, отличного от обычных субсидий. Можно рассмотреть различные варианты этого метода. Например, можно было бы учесть динамический аспект задачи. Коммуны меняются из года в год и частичные индексы Aj, Bj , … , Ij нужно оценивать на основе многих наблюдений; быть может, следовало бы провести соизмерение во времени, чтобы можно было учесть относительную эволюцию богатств коммуны и числа ее жителей?
С точки зрения статистической теории можно упрекнуть этот метод в пренебрежении тем фактом, что некоторые распределения, скажем Dj и Fj, на самом деле отличны от нормального; с другой стороны, несомненно, должны быть учтены корреляции между факторами, хотя они и очень слабы.
Кроме того, возможно, что голосующие, выбрав веса, начинают испытывать некоторое сожаление о своих личных выборах после объявления результатов. Может быть, стоило бы снова ввести соизмерение после первого тура голосования, а затем снова продолжить выборы, если это необходимо. Действительно, важно, чтобы, с одной стороны, объявленные мнения не очень отличались друг от друга и, с другой стороны, чтобы результаты были приняты всеми. Хорошее средство для достижения этих целей — поставить голосующих перед лицом последствий их выборов, что приведет к дальнейшей корректировке последних.
Вот почему именно благодаря исследованию операций и
электронно-вычислительной технике муниципальные советники
Верхней Сены пришли к соглашению.
Соизмерение ценностей
Каждый раз, когда бывает нужно сравнить одни данные с другими, очевидно, необходимо располагать единицей, которая позволяет их соизмерять, чтобы затем можно было их классифицировать.
Можно было бы полагать, что один тот факт, что большинство данных, которые входят в задачи исследования операций, выражаются в денежных единицах, уже позволяет легко сравнивать эти данные.
Первое возражение вызвано тем, что денежная единица подвержена изменениям с течением времени, и таким образом, становится трудно сравнивать данные, относящиеся к двум или многим различным периодам. В качестве примера мы установим кривую изменения итога оборота одного коммерческого общества между 1954 и 1960 гг. Это общество, продавая французские товары (категории С) и заграничные товары (категории H, L, М), реализовало за время с 1954 по 1960 г. следующий оборот (табл. 15.1):
Таблица 15.1
Итог оборота (в млн. старых франков)
Год | 1954 | 1955 | 1956 | 1957 | 1958 | 1959 | 1960 |
Общий итог оборота….. | 160,1 | 152,1 | 199,2 | 206,7 | 202,3 | 211,2 | 243,5 |
% заграничного товара……. | 51,7 | 54,8 | 63,4 | 60,0 | 52,5 | 59,0 | 61,8 |
![]()
Статистики рассмотрели средние ежегодные цены каждой из категорий товаров и, беря за основу цену 1954 г., равную 100, вывели их относительную эволюцию (табл. 15.2).
Затем была составлена таблица 15.3 долей (по цене) различных категорий товаров по отношению к общим ежегодным итогам оборота.
Обозначая через a, b, g и d коэффициенты таблицы 15.3, можно таким образом найти среднюю ежегодную цену
![]() .
.
![]() Таблица 15.2
Таблица 15.2
| C | H | L | M |
1954 1955 1956 1957 1958 1959 1960 1961 (Оценка) | 100 103 106 118 128 134 141 148 | 100 105 108 113 125 152 154 163 | 100 102 115 141 162 214 224 246 | 100 108 114 124 141 167 175 188 |
Таблица 15.3
a | b | g | d | |
| C | H | L | M |
1954 1955 1956 1957 1958 1959 1960 1961 (Оценка) | 48,3 45,2 36,6 40 47,5 41 38,2 43 38 | 26,9 24,3 32 30,3 30,8 26,2 21 20 21 | 14,8 23,4 24,3 23,7 16,7 20,8 20,4 18,5 20,5 | 10 7,1 7,1 6 5 12 20,4 18,5 20,5 |
Результаты этого подсчета собраны в таблице 15.4.
Таблица 15.4
Средняя ежегодная цена проданных товаров
1954 | 1955 | 1956 | 1957 | 1958 | 1959 | 1960 | 1961 (оценка) |
100 | 103,6 | 109,4 | 122,3 | 133,4 | 159,3 | 167,6 | 176,5 178,4 |
Из этой таблицы был выведен итог оборота, приведенный к основе 100 в 1954 г. (табл. 15.5).
Таблица 15.5
Итоги оборота, приведенные к основе 100 в 1954 г.
Год | 1954 | 1955 | 1956 | 1957 | 1958 | 1959 | 1960 | 1961 |
Реализованный итог оборота……… | 160,1 | 152,1 | 199,2 | 206,7 | 202,3 | 211,2 | 243,5 | 340(?) |
Приведенное значение…………….. | 100 | 92,3 | 113,8 | 105,5 | 94,7 | 82,8 | 90,7 | 120(?) |
Теперь легко определить реальные колебания итога оборота как функцию времени (рис. 15.2).
![]()
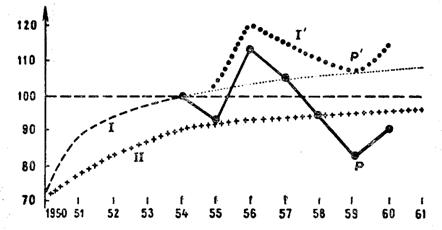
Рис. 15.2.
Посмотрим, каковы причины колебаний итога оборота. В 1955 г. увеличение таможенного налога (политика II), предпринятое правлением, приводит к некоторому понижению, которое, к счастью, компенсировалось в 1956— 1957 гг. свободой обмена, позволившей импортировать и продавать гораздо большую часть иностранных товаров. В 1958 г. затруднения в импорте приводят оборот к уровню, сравнимому с уровнем 1955 г.; он падает еще ниже в 1959 г. и вновь поднимается в 1960 г. благодаря новым мерам, благоприятствующим импорту.
Осторожные оценки позволяют предвидеть, что если бы проводилась политика I перед 1955 г., то это привело бы к развитию I' вследствие отмены свободы обмена. Самой низшей точкой была бы точка Р' (экономическая ситуация, аналогичная ситуации 1954 г.). Остается узнать, можно ли предсказать итог оборота на 1961 г. в размере 310 млн. или же предпочтительней остановиться на уже реализованном обороте в 243 млн., учитывая разницу в таможенных налогах между политиками I и II.
По поводу «полезности»
Хотя в предшествующем примере нам и пришлось проделать несколько простых подсчетов для сравнения итогов оборотов в различные годы, мы провели их с легкостью. Имея необходимую информацию, мы могли бы также сравнить различные политики управления по их результатам. К несчастью, это не всегда так.
Мы могли бы представить себе новый пример, где нужно было бы делать выбор между политиками управления, результаты которых были бы различны по отношению к некоторым критериям: распределяемым дивидендам, образуемым запасам, удовлетворению персонала, увеличению продажи, увеличению чистого дохода и т. д. Мы предпочтем ограничиться гораздо более непосредственными гипотезами.
Предположим, что существует (на самом деле) паштет из жаворонка (целиком из жаворонка, а не половина на половину — одна лошадь, один жаворонок...) и (тоже на самом деле) паштет из дрозда. Мы можем спросить у многих лиц из нашего окружения, что они предпочитают: А ответит, что он предпочитает паштет из жаворонка (это не увидительно, он родился в Питивье), В скажет, что он больше любит паштет из дрозда (В родом из Аяччо), С считает, что ему одинаково нравятся оба паштета и т. д. Чтобы уточнить эти точки зрения, можно попросить их оценить свое относительное удовлетворение при предположении, что предпочитаемый ими паштет отсутствует, а максимальная оценка удовлетворения равна 1. Мы получили бы таблицу такого типа:
Паштет из | ||
жаворонка | дрозда | |
A B C . . . | 1 0,6 0,5 . . . | 0,7 1 0,5 . . . |
После опроса большего числа лиц, вычисляя среднее арифметическое для каждого столбца, мы будем иметь, например, 0,7 в пользу паштета из жаворонка и 0,6 в пользу паштета из дрозда; мы сможем заключить, что предпочтения устанавливаются в виде:
паштет из жаворонка 0,7/1,3 = 0,54,
паштет из дрозда 0,6/1,3 = 0,46.
Задача становится более сложной, если мы вводим еще один элемент сравнения, скажем паштет из певчего дрозда. Проводя такие же опыты, как раньше, но предлагая на этот раз выбор между паштетом из певчего и обыкновенного дрозда[73], мы получим, например:
Паштет из | ||
певчего дрозда | обыкновенного дрозда | |
A B C . . . | 1 0,8 1 . . . | 0,6 1 0,8 . . . |
и среднее арифметическое равно 0,8 в пользу паштета из певчего дрозда и 0,6 в пользу паштета из обыкновенного дрозда.
Это позволяет нам заключить:
паштет из певчего дрозда 0,8/1,4 = 0,57;
паштет из обыкновенного дрозда 0,6/1,4 = 0,43.
Можно ли заключить, что паштет из певчего дрозда предпочитается паштету из жаворонка, как это следует из расчета по пропорции:
певчий дрозд 0,38,
жаворонок 0,33,
дрозд 0,29.
Здесь лучше применить другой способ. Попросим сначала каждого испытуемого приписать относительное удовлетворение каждому из трех блюд:
Паштет из | |||
певчего дрозда | жаворонка | обыкновенного дрозда | |
A B C . . . | 1 0,8 1 . . . | 0,9 0,9 0,8 . . . | 0,6 1 0,8 . . . |
Потребуем также от них предпочтений между одной порцией паштета из певчего дрозда и двумя порциями других паштетов: одной из жаворонка, другой из дрозда.
Предположим, что первый дегустатор отвечает, что он предпочитает паштет из певчего дрозда; удовлетворение s1, которое он от него получает, больше суммы удовлетворений s2 и s3, полученных им от других порций,
s1> s2+ s3.
Теперь мы пришли к тому, что значение s1 нужно взять большим, чем 0,9 + 0,6=1,5, например 1,6; отсюда мы получаем относительные предпочтения для A:
51,6; 29; 19,3.
B, может быть, ответит, что он предпочитает паштет из дрозда, откуда
s3> s1 + s2,
и относительные предпочтения равны, например,
27,6; 20,7; 51,7,
если положить
s3 =1,5.
В качестве другой ситуации вообразим следующую: C отвечает, что он не имеет предпочтений; тогда для него
s1 = s2 + s3,
откуда s1 =1,6 и
50; 25; 25.
Проделав те же вычисления для остальных опрошенных дегустаторов,
возьмем средние арифметические по столбцам и, нормируя результаты, получим выражение для удовлетворений в виде
48; 28; 24.
Заметим, что в этом процессе имеется значительный произвол; действительно, чтобы выполнялось неравенство
s1> s2+ s3.
мы выбрали s1=1,6, что действительно больше, чем 1,5; однако мы могли бы с тем же успехом взять s1 равным 1,7 или 1,8.
Итак, представляется возможным классифицировать ситуации, результаты или полезности, когда их имеется более двух, проводя опрос большого числа (заинтересованных) лиц, однако при условии, что выполняется гипотеза аддитивности, которая, как мы только что видели, является искусственной.
Таким методом американскими и французскими авторами было выполнено очень большое количество исследований.
Известно, что исходным построением швейцарской школы, основанной Вильфредо Парето, было введение частичного упорядочения; при этом для любой пары сравниваемых объектов х и у выясняется, является ли х предпочтительным по отношению к у (или наоборот) или же х может считаться эквивалентным у. Затем определяется отношение упорядочения — путем разбиения объектов на классы эквивалентности, не имеющие общих элементов.
Аксиомы, обычно применяемые американскими авторами, состоят в следующем. Пусть Oi — объекты, между которыми производится выбор.
Аксиома 1. Каждому элементу Oi можно поставить в соответствие неотрицательное число Xi.
Аксиома 2. Если Oi предпочитается Oj, то Xi > Xj; если Oi эквивалентно Oj, то Xi = Xj.
Аксиома 3. Если Xi и Xj соответствуют Oi и Oj, то Xi + Xj соответствует выбору, включающему Oi и Oj.
Из этой аксиомы вытекают следствия:
Следствие а. Если Oi предпочитается Oj, a Oj предпочитается Ok, то (Oi + Oj) предпочитается Ok.
Следствие б. Безразлично, что рассматривать: (Oj и Ok) или (Ok и Oj).
Следствие в. Если все равно, выбирать ли (Oj и Ok) или только Ok, то Xj = 0.
Из аксиомы 3 (гипотезы аддитивности) следует, что Oi и Oj могут быть выбраны одновременно, т. е. речь идет о ситуации, в которой выборы реализуемы независимо. Это очень важное ограничение.
Французская школа обычно не допускает аксиомы независимости. По этому поводу можно обратиться к работам Массе и Алле.
Что касается перехода от шкалы предпочтений к шкале ценностей, предлагаемого сторонниками субъективной теории стоимости, то он разбивается об аргументы защитников объективной теории.
Таким образом, речь идет о трудной задаче (даже в предположении, что ограничиваются только соизмерением ценностей), решение которой далеко от универсальности[74].
ГЛАВА 16. Новый Фреголи (Алгорифм Фаулкса и его приложения)
На днях мы посетили нашего друга Фреголи, хорошо известного в Мексике, и спросили у него, не мог бы он раскрыть нам секрет, который сделал его замечательным циркачом, неизменно любимым детьми и даже взрослыми. В самом деле, известно, что Фреголи может полностью сменить одежду в рекордное время. «Речь идет не о секрете, — сказал он нам, — а о логическом методе одевания и раздевания, переданном мне моими предками». И как хорошо воспитанный человек он счел возможным добавить: «Несомненно, математика, которая является вашей профессией, позволила бы вам представить себе усилия, которых потребовало от моего прадеда решение подобных задач».
Быть может, читатель будет удивлен этим утверждением. Избавим его от сомнений. Если математика прошлого действительно позволяла подсчитать количество комбинаций, которые нужно испробовать для того, чтобы одеться или раздеться по возможности наиболее удобным способом, то математика сегодняшнего дня позволяет определить лучшую (или лучшие) среди этих комбинаций. Предположим для простоты, что, когда наш друг Фреголи собирается сменить одежду, он не снимает белья — ни рубашки, ни кальсон. Тем не менее, чтобы предстать в обличье денди, ему все еще остается напялить на себя целую форму, содержащую брюки, жилет, пиджак, галстук, пальто, носки, ботинки, перчатки, а затем взять в руку трость с серебряным набалдашником.
Посмотрим, что он может сделать по крайней мере с восемью первыми предметами; при этом любой согласится с тем, что:
1) взять свою трость он сможет в последнюю очередь,
2) ему остается исследовать самое большее
8! = 8 ∙ 7 ∙ 6 ∙ 5 ∙ 4 ∙ 3 ∙ 2 ∙ 1 = 40 320
возможностей, из которых на самом деле большое количество отпадает вследствие невозможности надеть пальто раньше пиджака, пиджак раньше жилета и т. д.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
