

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Конечный узел Содержит несущее множество и вероятность для прогнозируемых выходных данных с учетом всех условий на пути, ведущем к текущему конечному узлу.
Узел регрессии Содержит формулу регрессии, которая представляет связь между входными данными и прогнозируемым атрибутом.
Дополнительные сведения см. в разделах Распределение узлов для дискретных атрибутов и Распределение узлов для непрерывных атрибутов.
NODE_SUPPORT
Количество вариантов, входящих в несущее множество этого узла.
MSOLAP_MODEL_COLUMN
Указывает столбец, содержащий прогнозируемый атрибут.
MSOLAP_NODE_SCORE
Отображает оценку, связанную с узлом. Дополнительные сведения см. в разделе Оценка узла.
MSOLAP_NODE_SHORT_CAPTION
Метка, используемая для отображения.
В модели дерева принятия решений отсутствует отдельный узел, хранящий статистику для модели в целом, такой как узел граничной статистики в модели упрощенного алгоритма Байеса или модели нейронной сети. Вместо этого модель создает отдельное дерево для каждого прогнозируемого атрибута, и на верхнем уровне дерева - узел (Все). Каждое дерево независимо от других. Если модель содержит только один прогнозируемый атрибут, в модели будет только одно дерево и только один узел (Все).
Каждое дерево, представляющее выходной атрибут, дополнительно делится на внутренние ветви (NODE_TYPE = 3), которые представляют разбиения. Каждое из этих деревьев содержит статистику о распределении целевого атрибута. Кроме этого, каждый конечный узел (NODE_TYPE = 4) содержит статистику, описывающую входные атрибуты и их значения, а также количество вариантов, входящих в несущее множество каждой пары «атрибут-значение». Поэтому в каждой ветви дерева принятия решений можно легко просмотреть вероятности или распределение данных без необходимости запрашивать исходные данные. Каждый уровень дерева обязательно представляет сумму своих непосредственных потомков.
Примеры получения такой статистики см. в разделе Запрос модели дерева принятия решений (службы Analysis Services — интеллектуальный анализ данных).
Если модель дерева принятия решений используется для составления прогноза, модель берет атрибуты, передаваемые в качестве аргументов, и движется вдоль дерева по пути атрибутов. Как правило, все прогнозы выходят на конечный уровень, а внутренние узлы используются только для классификации.
Конечный узел всегда имеет тип NODE_TYPE 4 (распределение) и содержит гистограмму, которая показывает вероятность каждого результата с учетом заданных атрибутов. Если прогнозируемый атрибут является непрерывным числом, алгоритм пытается создать формулу регрессии, которая моделирует связь между прогнозируемым атрибутом и входными данными.
Во всех моделях выполняется небольшая поправка, учитывающая возможные отсутствующие значения. Для непрерывных атрибутов каждое значение или диапазон значений представляется в виде состояния (например: Age <30, Age = 30 и Age >30), а вероятности вычисляются следующим образом: состояние существует (значение = 1), существует другое состояние (значение = 0), состояние равно Missing. Дополнительные сведения о выражении отсутствующих значений с помощью вероятностей см. в разделе Отсутствующие значения (службы Analysis Services — интеллектуальный анализ данных).
Вероятности для каждого узла вычисляются почти непосредственно из распределения, по следующей формуле:
Вероятность = (несущее множество для состояния + несущее множество для предыдущего состояния) / (несущее множество узла + несущее множество для предыдущего состояния)
Службы Службы Analysis Services используют вероятности для каждого узла, чтобы сравнить сохраненное значение вероятности с предыдущей вероятностью и определить, является ли путь от родительского узла к дочернему строгим следствием.
При составлении прогнозов вероятность распределения необходимо уравновешивать с вероятностью узла, чтобы получить более гладкое распределение вероятности. Например, если в результате разбиения дерева варианты делятся в отношении 9000/1000, дерево оказывается сильно неуравновешенным. В результате прогноз, создаваемый малой ветвью, не будет иметь тот же вес, что и прогноз, создаваемый ветвью со множеством вариантов.
Дисперсия является показателем разброса значений в выборке при заданном ожидаемом распределении. Для дискретных значений дисперсия по определению равна 0.
Сведения о вычислении дисперсии для непрерывных значений см. в разделе Содержимое моделей интеллектуального анализа данных для моделей линейной регрессии (службы Analysis Services — интеллектуальный анализ данных).
В деревьях классификации используются следующие типы из перечисления MiningValueType.
Тип значения | Описание |
1 (отсутствует) | Указывает количество, вероятность и другую статистику, связанную с отсутствующим значениям. |
4 (дискретный) | Указывает количество, вероятность и другую статистику, связанную с дискретным или дискретизированным значением. |
Если модель содержит непрерывный прогнозируемый атрибут, дерево также может содержать типы значений, являющиеся уникальными для формул регрессии. Список типов значений, используемых в деревьях регрессии, см. в разделе Содержимое моделей интеллектуального анализа данных для моделей линейной регрессии (службы Analysis Services — интеллектуальный анализ данных).
Оценка узла на каждом уровне дерева представляет несколько отличающиеся сведения. В общем случае оценка представляет собой числовое значение, показывающее, насколько удачным было разбиение по условию. Значение имеет тип double, и чем больше значение, тем удачнее считается разбиение. Узел модели и все конечные узлы по определению имеют оценку узла 0. Для узла (Все), представляющего верхний уровень каждого дерева, столбец MSOLAP_NODE_SCORE содержит самый лучший коэффициент разбиения во всем дереве. Оценка для каждого из остальных узлов в дереве (за исключением конечных узлов) равна наилучшему коэффициенту разбиения для текущего узла минус оценка разбиения для родительского узла. Коэффициент разбиения для родительского узла обычно больше, чем оценка разбиения в любом из дочерних узлов. Это происходит потому, что в идеальном случае модель дерева принятия решений вначале выполняет разбиение по самым важным атрибутам. Оценку разбиения можно вычислить множеством способов в зависимости от выбранного параметра алгоритма. Обсуждение способов вычисления оценки для каждого из методов оценки выходит за рамки этого раздела. Дополнительные сведения см. в документе «Обучающиеся байесовы сети: сочетание знаний и статистических данных» (на английском языке) на веб-узле Microsoft Research.
 Узлы регрессии в модели дерева принятия решений
Узлы регрессии в модели дерева принятия решений
Если модель дерева принятия решений содержит прогнозируемый атрибут с непрерывными числовыми данными, алгоритм дерева принятия решений пытается найти в данных области, где связь между прогнозируемым состоянием и входными переменными является линейной. Если алгоритму удается обнаружить линейную связь, он создает специальное дерево (NODE_TYPE = 25), представляющее линейную регрессию. Узлы этого дерева регрессии являются более сложным, чем узлы, представляющие дискретные значения.
В общем случае регрессия представляет изменения в непрерывном зависимом аргументе (прогнозируемой переменной) как функцию изменений во входных данных. Если для зависимой переменной существуют непрерывные входные параметры, а связь между входными данными и прогнозируемым значением достаточно устойчива, чтобы вычисляться как реберный граф, то узел для регрессии содержит формулу. Например, пусть А является прогнозируемым атрибутом, а Б и В являются входными параметрами, причем В имеет непрерывный тип значения. Тогда если связь между А и В является вполне устойчивой в некоторых областях данных, но неустойчивой в других областях, то алгоритм создаст разбиения, представляющие различные области данных.
Условие разбиения | Результат в узле |
Если n < 5 | Связь можно выразить формулой 1 |
Если n лежит между 5 и 10 | Нет формулы |
Если n > 10 | Связь можно выразить формулой 2 |
4. Выбор решения в различных внешних условиях
В 4 главе остановимся на решении локальных задач, выборе решения в ветвях деревьев, выборе обобщенных решений и т. п.
Как в практически каждой науке, в ТПР формируется свой подход к формализации проблем, свой язык, аппарат выводов и методы исследования. На сегодня эти процессы развиваются и имеется еще ряд вопросов, которые можно выделить как ведущие.
Ÿ Строгое определение области явлений, о которых можно говорить, как о принятии решений.
Ÿ Познание механизмов ТПР в деятельности человека и в биологических системах.
Ÿ Изучение поведения биологических систем и целенаправленной деятельности.
Ÿ Формализация процесса ТПР.
Ÿ Взаимодействие человека и технических средств процессе ПР.
Ÿ Принятие решений в условиях неопределенности
Элементарная теория принятия решений рассматривается в условиях неопределенности и риска.
Расширяется роль ТПР и в теории автоматического управления. В теории робототехнических систем как базовые анализируются три вида условных предложений:
P1: если x есть A то y есть B.
P2: если x есть A то y есть B иначе C.
P3: если ![]() есть
есть ![]() и
и ![]() есть
есть ![]() и...
и... ![]() есть
есть ![]() то y есть B
то y есть B
Не четкость определений множеств и их связей существенно усложняет принятие решений даже в простых одноступенчатых схемах.
Например, для условного предложения P1 ряд авторов рекомендуют решения по схемам.
Пусть ![]() ,
, ![]() , не четкие концепции в универсуме U; B,
, не четкие концепции в универсуме U; B, ![]() , не четкие концепции в универсуме V.
, не четкие концепции в универсуме V.
1. Предпосылка 1: если x есть A, то y есть B.
Предпосылка 2: ![]() есть
есть ![]() .
.
Вывод: ![]() есть
есть ![]() .
.
2. Предпосылка 1: если x есть A то y есть B.
Предпосылка 2: ![]() есть очень
есть очень ![]() .
.
Вывод: ![]() есть очень
есть очень ![]() .
.
3. Предпосылка 1: если x есть A то y есть B.
Предпосылка 2: ![]() есть более или менее
есть более или менее ![]() .
.
Вывод: ![]() есть более или менее
есть более или менее ![]() .
.
4. Предпосылка 1: если x есть A то y есть B.
Предпосылка 2: ![]() не есть
не есть ![]() .
.
Вывод: ![]() не есть
не есть ![]() .
.
По сути это ситуации частично рассмотренные в разделе 2.1. Предложение №1 – детерминированный случай. Зоны, в которой действительны утверждения №2 и №4, четко определены (рис. 2). Зона действия утверждения №3 – нечеткая область.
Пусть E - универсальное множество, х - элемент Е, а G - некоторое свойство. Обычное (четкое) подмножество А универсального множества Е, элементы которого удовлетворяют свойству G, определяется как множество упорядоченных пар:
![]() ,
,
где ![]() - характеристическая функция, принимающая значение 1, если х удовлетворяет свойству G, и 0 - в противном случае.
- характеристическая функция, принимающая значение 1, если х удовлетворяет свойству G, и 0 - в противном случае.
При задании нечеткого подмножества для элементов х из Е нет однозначного ответа «да или нет» относительно свойства G. И хотя нечеткое подмножество А универсального множества Е определяется также, как множество упорядоченных пар:
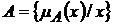 ,
,
где ![]() - характеристическая функция принадлежности (или просто функция принадлежности), принимающая значения уже в некотором упорядоченном множестве М (например, М = [0,...,1]). Функция принадлежности указывает степень (или уровень) принадлежности элемента х подмножеству А. Множество М называют множеством принадлежностей.
- характеристическая функция принадлежности (или просто функция принадлежности), принимающая значения уже в некотором упорядоченном множестве М (например, М = [0,...,1]). Функция принадлежности указывает степень (или уровень) принадлежности элемента х подмножеству А. Множество М называют множеством принадлежностей.
Если М = {0, 1}, то нечеткое подмножество А может рассматриваться как обычное или четкое множество.
Ниже приведен пример результирующей матрицы для операции сложения в условиях, когда функция принадлежности 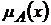 представлена
представлена ![]() нечеткими величинами вида:
нечеткими величинами вида:
![]() ,
, ![]() , ...,
, ..., ![]() ,
,
где ![]() 1...
1...![]() .
.
Исходные функции принадлежности располагаются в левом столбце и верхней строке матрицы. Элементами этой матрицы являются дискретные нечеткие величины
![]() ,
,
где ![]() 1...
1...![]() ,
, ![]() 1...
1...![]() и
и
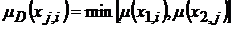 ,
,
и 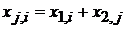 .
.
4.1. Общие положения
Аналитически формально задача принятия решения описывается как упорядочная четверка. Кортеж ![]() определяет класс схем принятия решений
определяет класс схем принятия решений
 ,
,
где ![]() - множество возможных значений не наблюдаемого параметра;
- множество возможных значений не наблюдаемого параметра;
![]() - множество всех возможных решений (альтернатив);
- множество всех возможных решений (альтернатив);
![]() - функция потерь, заданная на
- функция потерь, заданная на ![]() ,
, ![]() ;
;
![]() - статистическая закономерность на
- статистическая закономерность на ![]() .
.
Практически все величины, входящие в кортеж определены не четко.
Пусть имеется совокупность действий, операций, решений
а1, а2, ..., аm, m ³ 2,
которые может совершить система для достижения поставленной цели, причем одну и только одну операцию аi, iÎ{1, 2, ..., m}, выбирает алгоритм, принимающий решение.
Кроме того, представлен перечень объективных условий (ситуаций), F1, F2, ..., Fn,
одно из которых Fj, jÎ{1, 2, ..., n}, будет иметь место в действительности.
Для каждой операции аi, i = 1, 2, ..., m, при каждом условии Fj, задан риск в некоторых единицах ![]() .
.
Величины ![]() , играющие роль платежей в теории игр, получаются расчетным или оценочным путем. Они могут быть объективны или субъективны. Возникают определенные трудности при их числовой оценке, обусловленные многими факторами. Величины
, играющие роль платежей в теории игр, получаются расчетным или оценочным путем. Они могут быть объективны или субъективны. Возникают определенные трудности при их числовой оценке, обусловленные многими факторами. Величины ![]() можно задавать относительно, поэтому нередко их называют показателями предпочтительности.
можно задавать относительно, поэтому нередко их называют показателями предпочтительности.
На рис. 114 представлены виды двух типов функций рисков. Многоэкстремальной (а) и гладкой (б). Каждое значение функции рисков может быть нечетко заданным и многокомпонентным. Так как ![]() представляет собой основное наполнение матрицы решений, то рис. 114 можно определить как графическое представление матрицы решений.
представляет собой основное наполнение матрицы решений, то рис. 114 можно определить как графическое представление матрицы решений.
| |
а | б |
Рис. 114. Вид различных типов функций риска |
Табличное представление матрицы решений в различных областях применения ТПР имеет свою специфику. Рассмотрим ее вид наиболее часто встречающийся в технических приложениях. В таблице 10 представлены по строкам:
Ÿ Вторая строка – символьное определение типа ситуации. В отдельных источниках можно встретить название явление природы или состояние природы. Все это говорит о желании авторов представить некоторый, не управляемый системой параметр внешней среды, от которого зависит эффективность возможных действий системы. Практическое решение в расчетах имеет только индекс ситуации ![]() .
.
Ÿ Первая строка – характеристическая функция принадлежности ![]() . Как правило определяется в виде вероятности возникновения ситуации
. Как правило определяется в виде вероятности возникновения ситуации ![]() . Но это не ограничивает жестко ее суть. Данная величина чаще всего используется в расчетах в виде сомножителя
. Но это не ограничивает жестко ее суть. Данная величина чаще всего используется в расчетах в виде сомножителя ![]() , поэтому имеет вид весовой функции
, поэтому имеет вид весовой функции ![]() ситуации, ее дополнительного влияния на исход решения.
ситуации, ее дополнительного влияния на исход решения.
Ÿ Второй столбец – символьные обозначения возможных решений. Практическое значение имеет только индекс решения. Именно поиск данного индекса является базовой целью анализа. Его значение определяет оптимальное решение, дающее наибольший выигрыш или наименьшие потери при заданном уровне возможного проигрыша, который может случится, если возникнет одна из не запланированных ситуаций.
Ÿ Первый столбец – характеристическая функция принадлежности ![]() . Определяет обычно вероятность осуществления решения
. Определяет обычно вероятность осуществления решения ![]() . В ряде случаев по объективным или субъективным причинам запланированное решение не реализуется полностью и реально осуществляется другое учтенное или неучтенное решение (параметры реализованного решения не позволяют говорить о том, что выполнено запланированное решение).
. В ряде случаев по объективным или субъективным причинам запланированное решение не реализуется полностью и реально осуществляется другое учтенное или неучтенное решение (параметры реализованного решения не позволяют говорить о том, что выполнено запланированное решение).
Поле таблицы заполняется оценками риска или выигрыша ![]() от принятия решения
от принятия решения ![]() , при его реализации в условии
, при его реализации в условии ![]() .
.
Таблица 10
| ... |
| ... |
| ||
| ... |
| ... |
| ||
|
|
| ... |
| ... |
|
... | ... | ... | ... | ... | ... | ... |
|
|
| ... |
| ... |
|
... | ... | ... | ... | ... | ... | |
|
|
| ... |
| ... |
|
При последующем анализе таблица видоизменяется. В нее вводятся новые строки и столбцы. Они уменьшают объем вычислительных операций, так как из рассмотрения удаляются отдельные, слабые по мнению авторов зависимости.
Добавляемый столбец получил название оценочной функции ![]() , которая отражает установленный по выбранной схеме принятия решений (критерию) выигрыш или потери от решения с номером
, которая отражает установленный по выбранной схеме принятия решений (критерию) выигрыш или потери от решения с номером ![]() .
.
Добавляемая строка ![]() обычно используется, как уменьшаемое в пересчетах таблицы принятия решений. В ряде преобразований она представляет максимально возможный выигрыш в ситуации
обычно используется, как уменьшаемое в пересчетах таблицы принятия решений. В ряде преобразований она представляет максимально возможный выигрыш в ситуации ![]() . Тогда таблица превращается в таблицу потерь от не оптимальных для данной ситуации решений. После добавления строк и столбцов таблица принимает новый вид (таблица 11).
. Тогда таблица превращается в таблицу потерь от не оптимальных для данной ситуации решений. После добавления строк и столбцов таблица принимает новый вид (таблица 11).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
