

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Очевидно, что атрибут, идентифицирующий пациента, не будет высоко оценен критерием (6). Пусть имеется k классов, тогда числитель выражения максимально будет равен log2(k) и пусть n – количество примеров в обучающей выборке и одновременно количество значений атрибута, тогда знаменатель максимально равен log2(n). Если предположить, что количество примеров заведомо больше количества классов, то знаменатель растет быстрее, чем числитель, и, соответственно, выражение будет иметь небольшое значение. Таким образом, заменим базовый критерий на улучшенный, и опять же выберем атрибут, имеющий максимальное значение по новому критерию. Базовый критерий использовался в алгоритме ID3, а улучшенный введен в модифицированном алгоритме С4.5.
Несмотря на то, что мы улучшили критерий выбора атрибута для разбиения, алгоритм может создавать узлы и листья, содержащие незначительное количество примеров. Чтобы избежать этого, следует воспользоваться еще одним эвристическим правилом: при разбиении множества T, по крайней мере, два подмножества должны иметь не меньше заданного минимального количества примеров k (k>1); обычно оно равно 2. В случае невыполнения этого правила, дальнейшее разбиение этого множества прекращается, и соответствующий узел отмечается как лист.
Вероятно, что при таком ограничении может возникнуть ситуация когда примеры ассоциированные с узлом относятся к разным классам. В качестве решения листа выбирается класс, который наиболее часто встречается в узле, если же примеров равное количество из всех классов, то решение дает наиболее часто встречающийся класс у непосредственного предка данного листа.
Возвращаясь к вопросу о выборе порога для числовых атрибутов, можно ввести следующее дополнение: если минимальное число примеров в узле k тогда имеет смысл рассматривать только следующие значения TH1, TH2 … THn-1, так как при разбиении по первым и последним k – 1 порогам в узел попадает меньше k примеров.
Алгоритм построения деревьев решений, рассматриваемый нами, предполагает, что для атрибута, выбираемого в качестве проверки, существуют все значения, хотя явно это нигде не утверждалось. Т. е., для любого примера из обучающей выборки, существует значение по этому атрибуту.
Пока мы работаем с синтетическими данными, особых проблем не возникает, мы можем "сгенерировать" нужные данные. Но как только мы обратимся к практической стороне вопроса, то выясняется, что реальные данные далеки от идеальных, и что часто встречаются пропущенные, противоречащие и аномальные данные.
Остановимся на проблеме пропущенных данных. Первое решение, которое лежит на поверхности и – это не учитывать примеры с пропущенными значениями. Следует подчеркнуть, что крайне нежелательно отбрасывать весь пример только потому, что по одному из атрибутов пропущено значение, поскольку мы рискуем потерять много полезной информации. Тогда нам необходимо выработать процедуру работы с пропущенными данными.
Пусть вновь T – множество обучающих примеров и X – проверка по некоторому атрибуту A. Обозначим через U количество неопределенных значений атрибута A. Изменим формулы энтропии таким образом, чтобы учитывать только те примеры, у которых существуют значения по атрибуту A.
![]() ,
, ![]()
В этом случае при подсчете freq(Cj, T) учитываются только примеры с существующими значениями атрибута A.
Тогда базовый критерий можно модифицировать ![]() .
.
Подобным образом изменяется и улучшенный критерий. Если проверка имеет n выходных значений, то улучшенный критерий считается как в случае, когда исходное множество разделено на n+1 подмножеств.
Пусть теперь проверка X с выходными значениями O1, O2 … On и выбран на основе модифицированного критерия.
Надо решить, что делать с пропущенными данными. Если пример из множества T с известным выходом Oi ассоциирован с подмножеством Ti, вероятность того, что пример из множества Ti равна 1. Пусть тогда каждый пример из подмножества Ti имеет вес, указывающий вероятность того, что пример принадлежит Ti. Если пример имеет значение по атрибуту A, тогда вес равен 1, в противном случае пример ассоциируется со всеми множествами T1, T2 … Tn, с соответствующими весами![]() . Замкнутость дает
. Замкнутость дает 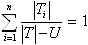 .
.
Вкратце, этот подход можно сформулировать таким образом: предполагается, что пропущенные значения по атрибуту вероятностно распределены пропорционально частоте появления существующих значений.
Классификация новых примеров. Такая же методика применяется и при использовании дерева для классификации новых примеров. Если на каком-то узле при проверке выясняется, что значение соответствующего атрибута классифицируемого примера пропущено, то исследуют все возможные пути вниз по дереву и определяют с какой вероятностью пример относится к различным классам. В этом случае, "классификация" – это скорее распределение классов. Как только распределение классов установлено, то класс, имеющий наибольшую вероятность появления, выбирается в качестве ответа дерева решений.
На примере рекомендаций по дереву принятия решений в сетевых технологиях корпорации Майкрософт оценим основные моменты технологии (беглое чтение). Задача ориентируется на построение байесовской сети при сочетания априорного знания и статистических данных. Важной частью алгоритма является методология оценки информационного значения априорных вероятностей, необходимых для обучения. Этот подход базируется на предположении об эквивалентности правдоподобия, которое гласит, что данные не должны помогать различению сетевых структур, которые во всем остальном представляют собой одни и те же утверждения условной независимости.
Предполагается, что у каждого варианта имеется одна байесова априорная сеть и один показатель достоверности для этой сети. С помощью этих априорных сетей алгоритм вычисляет относительные апостериорные вероятности сетевых структур на основе текущих обучающих данных и выявляет сетевые структуры с наиболее высокими апостериорными вероятностями.
Стремятся применить различные методы для построения дерева и выбора наилучшего пути. Выбор метода зависит от задачи — это может быть линейная регрессия, классификация или анализ взаимосвязей. Единая модель может содержать несколько деревьев для различных прогнозируемых атрибутов. Более того, каждое дерево может содержать несколько ветвей в зависимости от того, сколько атрибутов и значений содержится в данных. Форма и глубина дерева, построенного на основе конкретной модели, зависит от метода количественной оценки и от других использованных параметров. Изменения в параметрах могут также влиять на разбиение узлов.
Построение дерева
Проведем селекцию с предсказанием для выявления атрибутов и значений, предоставляющих больше всего информации, и удалим из числа рассматриваемых слишком редкие значения. Этот алгоритм также группирует значения в корзины для создания группирований величин, которые можно обрабатывать вместе для оптимизации производительности.
Дерево строится посредством определения корреляции между входом и целевым выходом. После проведения корреляции для всех атрибутов алгоритм выявляет единственный атрибут, который лучше всего разделяет результирующие выходы. Эта точка наилучшего разделения измеряется с помощью уравнения, которое оценивает прирост информации. Атрибут, имеющий наилучшую оценку для прироста информации, используется для разбиения вариантов на подмножества, которые затем рекурсивно анализируются тем же алгоритмом, пока дальнейшие разбиения дерева не станут невозможными.
Точное уравнение для оценки прироста информации зависит от набора параметров, применявшихся при создании алгоритма, типа данных прогнозируемого столбца и типа входных данных.
Дискретные и непрерывные входные данные.
Если дискретны и прогнозируемый атрибут, и входные данные, подсчет количества результатов на каждый вход сводится к созданию матрицы и вычислению оценок для каждой ее ячейки. Если прогнозируемый атрибут дискретен, а входные данные непрерывны, вход непрерывных столбцов автоматически дискретизируется. Можно принять значения по умолчанию и предоставить службам Analysis Services возможность найти оптимальное количество корзин или управлять тем, каким образом дискретизируются непрерывные входы, путем настройки свойств DiscretizationMethod и DiscretizationBucketCount. Для непрерывных атрибутов алгоритм использует линейную регрессию для определения места разбиения дерева решений.
Если прогнозируемый атрибут относится к непрерывному числовому типу данных, выбор характеристик применяется также и к выходам для снижения возможного числа результатов и ускорения построения модели. Настроив параметр MAXIMUM_OUTPUT_ATTRIBUTES, можно изменить пороговое значение для выбора характеристик и таким образом увеличить или снизить число возможных величин.
Методы количественной оценки и выбор характеристик
В алгоритме дерева принятия решений предусмотрены три формулы для вычисления прироста информации: энтропия Шеннона, метод Байеса с априорной оценкой K2 и байесовская сеть с однородной априорной оценкой Дирихле. Все три метода широко применяются для интеллектуального анализа данных. Рекомендуется поэкспериментировать с различными параметрами и методами количественной оценки, чтобы понять, какие из них дают наилучшие результаты.
Выбор компонентов автоматически применяется всеми алгоритмами интеллектуального анализа данных служб Службы Analysis Services для улучшения качества анализа и снижения вычислительной нагрузки. Метод, применяемый для выбора характеристик, зависит от алгоритма, который был использован при создании модели. Выбором характеристик в модели дерева решений управляют следующие параметры алгоритма: MAXIMUM_INPUT_ATTRIBUTES и MAXIMUM_OUTPUT.
Алгоритм | Метод анализа | Комментарии |
Деревья решений | Оценка интересности Энтропия Шеннона Алгоритм Байеса с априорной оценкой K2 Эквивалент Дирихле метода Байеса с однородной априорной оценкой (выбор по умолчанию) | Если какие-либо столбцы содержат недвоичные непрерывные значения, то оценка интересности используется для всех столбцов в целях обеспечения согласованности. В противном случае используется предусмотренный по умолчанию или указанный метод. |
Линейная регрессия | Оценка интересности | В алгоритме линейной регрессии применяется только оценка интересности, поскольку этот алгоритм поддерживает лишь непрерывные столбцы. |
Масштабируемость и производительность
Классификация является важной стратегией интеллектуального анализа данных. Обычно количество информации, нужное для классификации вариантов, растет прямо пропорционально количеству входных записей. Это ограничивает объем данных, поддающихся классификации. Алгоритм использует следующие методы для решения упомянутых выше проблем, улучшения производительности и устранения ограничений памяти.
Выбор характеристик для оптимизации выбора атрибутов.
Вычисление байесовских оценок для управления ростом дерева.
Оптимизация разделения на корзины для непрерывных атрибутов.
Динамическое группирование входных значений для определения самых важных данных.
Алгоритм дерева принятия решений — быстрый, хорошо масштабируемый алгоритм, созданный для удобства параллелизации, а это означает, что все процессоры системы могут работать вместе для создания единой согласованной модели. Сочетание этих характеристик делает классификатор на основе дерева принятия решений идеальным средством для интеллектуального анализа данных.
Если существуют жесткие ограничения на производительность, можно попробовать улучшить время обработки в процессе обучения модели дерева принятия решений с помощью следующих методов.
Увеличение параметра COMPLEXITY_PENALTY для ограничения роста дерева.
Ограничение количества элементов в модели взаимосвязей для ограничения количества создаваемых деревьев.
Увеличение параметра MINIMUM_SUPPORT во избежание создания лжевзаимосвязи.
Сокращение количества дискретных значений всех атрибутов до 10 или менее. Можно попробовать группировать значения по-разному в разных моделях.
 Настройка алгоритма дерева принятия решений
Настройка алгоритма дерева принятия решений
При наличии нескольких параметров, влияющих на производительность и точность получающейся в результате модели интеллектуального анализа данных, можно изменять способ обработки данных, устанавливая на столбцах модели интеллектуального анализа данных или структуры интеллектуального анализа данных флаги модели.
Задание параметров алгоритма
В следующей таблице описаны параметры, которые можно использовать с алгоритмом временных рядов.
COMPLEXITY_PENALTY - Управляет ростом дерева решений. Низкое значение увеличивает количество разбиений, а высокое количество — уменьшает. Значение по умолчанию основано на количестве атрибутов для конкретной модели, как описано в следующем списке.
Для атрибутов с 1 до 9 значением по умолчанию является 0,5.
Для атрибутов с 10 до 99 значением по умолчанию является 0,9.
Для 100 или более атрибутов по умолчанию 0,99.
FORCE_REGRESSOR - Вынуждает алгоритм использовать указанные столбцы в качестве регрессоров, не обращая внимания на важность столбцов, вычисленную алгоритмом. Этот параметр используется только для деревьев решений, прогнозирующих непрерывный атрибут.
[SQL Server Enterprise] MAXIMUM_INPUT_ATTRIBUTES - Определяет количество входных атрибутов, которые алгоритм может обработать перед вызовом выбора компонентов.
Значение по умолчанию равно 255.
Установите значение 0, чтобы отключить выбор характеристик.
[SQL Server Enterprise] MAXIMUM_OUTPUT_ATTRIBUTES
Определяет количество выходных атрибутов, которые алгоритм может обработать перед вызовом выбора характеристик. Значение по умолчанию равно 255.
Установите значение 0, чтобы отключить выбор характеристик.
[SQL Server Enterprise] MINIMUM_SUPPORT
Определяет минимальное количество конечных вариантов, необходимых для формирования разбиения в дереве решений. Значение по умолчанию равно 10.
Для очень больших наборов данных это значение, возможно, придется увеличить, чтобы избежать чрезмерно тщательного обучения.
SCORE_METHOD
Определяет метод, используемый для вычисления коэффициента разбиения. Доступны следующие параметры.
1 | Энтропия |
2 | Алгоритм Байеса с априорной оценкой K2 |
Идентификатор | Наименование |
3 | Эквивалент Дирихле метода Байеса (BDE) с априорной оценкой (по умолчанию) |
SPLIT_METHOD Определяет метод, используемый для разбиения узла. Доступны следующие параметры.
Идентификатор | Наименование |
1 | Binary: указывает, что независимо от реального числа значений атрибута дерево следует разбить на две ветви. |
2 | Complete: указывает, что в дереве можно создавать столько разбиений, сколько существует значений атрибута. |
3 | Both: указывает, что службы Analysis Services могут определять, какое разбиение лучше использовать — бинарное или полное (по умолчанию). |
Флаги моделирования
Алгоритм деревьев решений поддерживает следующие флаги модели. Чтобы задать порядок обработки в ходе анализа значений в каждом столбце, во время создания структуры или модели интеллектуального анализа данных определяются флаги модели. Дополнительные сведения см. в разделе Флаги моделирования (интеллектуальный анализ данных).
Флаг моделирования | Описание |
MODEL_EXISTENCE_ONLY | Столбец будет обрабатываться так, как будто у него два возможных состояния: Missing и Existing. NULL означает отсутствие значения. Применяется к столбцам модели интеллектуального анализа данных. |
NOT NULL | Указывает, что столбец не может принимать значение NULL. Если службы Analysis Services в ходе обучения модели обнаруживают NULL, возникает ошибка. Применяется к столбцам структуры интеллектуального анализа данных. |
Регрессоры в моделях дерева принятия решений.
Даже если не используется алгоритм линейной регрессии любая модель дерева решений, в которой есть непрерывные числовые входы и выходы, может содержать узлы, представляющие регрессию применительно к непрерывному атрибуту. Не обязательно указывать, что столбец непрерывных числовых данных представляет собой регрессор. Алгоритм дерева принятия решений автоматически использует этот столбец как потенциальный регрессор и секционирует набор данных на области со значимыми шаблонами, даже если для столбца не задан флаг REGRESSOR.
Можно, однако, применить параметр FORCED_REGRESSOR, чтобы гарантировать использование конкретного регрессора в алгоритме. Этот параметр может применяться только с алгоритмом дерева принятия решений и алгоритмом линейной регрессии. Если пользователем задан флаг модели, алгоритм попытается найти уравнения регрессии в форме a*C1 + b*C2 + ... для подгонки шаблонов к узлам дерева. Вычисляется сумма остатков, и, если отклонение слишком велико, принудительно выполняется разбиение дерева.
Требования к модели. Модель дерева решений должна содержать ключевой столбец, входные столбцы и по крайней мере один прогнозируемый столбец.
Входные и прогнозируемые столбцы
Алгоритм дерева решений поддерживает определенные входные столбцы данных и прогнозируемые столбцы, которые перечислены ниже в таблице. Дополнительные сведения о значении типов содержимого в применении к модели интеллектуального анализа данных см. в разделе Типы содержимого (интеллектуальный анализ данных).
Столбец | Типы содержимого |
Входной атрибут | Continuous, Cyclical, Discrete, Discretized, Key, Ordered, Table |
Прогнозируемый атрибут | Continuous, Cyclical, Discrete, Discretized, Ordered, Table |
В этом разделе описано содержимое модели интеллектуального анализа данных, характерное для моделей, в которых используется алгоритм дерева принятия решений. Общее описание содержимого модели интеллектуального анализа данных для всех типов моделей см. в разделе Содержимое модели интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных). Важно помнить. что алгоритм дерева принятия решений является гибридным и может создавать модели с весьма различными функциями: дерево принятия решений может представлять взаимосвязи, правила и даже линейную регрессию. Структура дерева остается в целом неизменной, но способ интерпретации данных будет зависеть от задачи, для которой создавалась модель.
Основные сведения о структуре модели деревьев.
Модель дерева принятия решений содержит один родительский узел, представляющий модель и ее метаданные. Под родительским узлом находятся независимые деревья, представляющие выбранные прогнозируемые атрибуты. Например, если настроить модель дерева принятия решений для прогнозирования покупок, совершаемых клиентами, и задать входные значения пола и дохода, то модель создаст одно дерево для атрибута покупки со множеством ветвей, разделяющихся по условиям, связанных с полом и доходом.
Однако если затем добавить отдельный прогнозируемый атрибут для участия в поощрительной программе, алгоритм создаст два отдельных дерева под родительским узлом. Одно дерево содержит анализ для совершения покупки, а второе — анализ для участия в поощрительной программе. Если использовать алгоритм деревьев принятия решений для создания модели взаимосвязей, алгоритм создает отдельное дерево для каждого прогнозируемого товара, и это дерево содержит все сочетания других товаров, отвечающие выбору целевого атрибута.
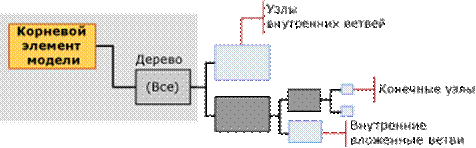
Рис. Пример простейшего дерева
Дерево для каждого прогнозируемого атрибута содержит сведения, описывающие, как выбранные входные столбцы влияют на выходные данные этого прогнозируемого атрибута. Вверху каждого дерева находится узел (NODE_TYPE = 9), содержащий прогнозируемый атрибут, а затем следует ряд узлов (NODE_TYPE = 10), которые представляют входные атрибуты. Атрибут соответствует столбцу уровня вариантов или значениям столбцов вложенной таблицы, которые обычно находятся в столбце Key вложенной таблицы.
Внутренние и конечные узлы представляют условия разбиения. Дерево может разбиваться несколько раз по одному атрибуту. Например, модель TM_DecisionTree может разбиваться по атрибутам [Yearly Income] и [Number of Children], а на следующем участке дерева вновь разбиваться по атрибуту [Yearly Income].
Алгоритм дерева принятия решений также может содержать линейные регрессии во всем дереве или в его части. Если моделируемый атрибут имеет непрерывный числовой тип данных, модель может создать узел дерева регрессии (NODE_TYPE = 25) там, где связь между атрибутами может моделироваться линейно. В этом случае узел содержит формулу регрессии.
Однако если прогнозируемый атрибут имеет дискретные значения, а также если его числовые значения сегментированы или дискретизированы, то модель всегда создает дерево классификации (NODE_TYPE =2). Дерево классификации может иметь несколько ветвей или внутренних узлов дерева (NODE_TYPE =3) для каждого значения атрибута, однако не для каждого значения атрибута выполняется разбиение.
Алгоритм дерева принятия решений не допускает входные данные непрерывных типов. Поэтому, если какие-либо столбцы имеют непрерывный числовой тип данных, их значения дискретизируются. Для всех непрерывных атрибутов алгоритм самостоятельно выполняет дискретизацию в момент разбиения.
Содержимое для модели дерева принятия решений.
В этом разделе представлено подробное описание с примерами только для тех столбцов модели интеллектуального анализа данных, которые имеют отношение к моделям дерева принятия решений. Сведения о столбцах общего назначения в наборе строк схемы, а также объяснение терминологии моделей интеллектуального анализа данных см. в разделе Содержимое модели интеллектуального анализа данных (службы Analysis Services — интеллектуальный анализ данных).
MODEL_CATALOG
Имя базы данных, в которой хранится модель.
MODEL_NAME
Имя модели.
ATTRIBUTE_NAME
Имя атрибута, отвечающего этому узлу.
NODE_NAME
Всегда совпадает с NODE_UNIQUE_NAME.
NODE_UNIQUE_NAME
Уникальный идентификатор узла в модели. Это значение невозможно изменить.
Для моделей дерева принятия решений уникальные имена подчиняются следующим правилам, которые не применяются ко всем алгоритмам.
Все потомки любого узла имеют одинаковый шестнадцатеричный префикс, за которым следует другое шестнадцатеричное число, представляющее порядковый номер узла среди потомков данного родителя. С помощью префиксов можно получить путь.
NODE_TYPE
В моделях дерева принятия решений создаются следующие типы узлов.
Тип узла | Описание |
1 (модель) | Корневой узел для модели. |
2 (дерево) | Родительский узел для деревьев классификации в модели. Помечается "Все". |
3 (внутренний) | Начальный элемент внутренней ветви, находящейся в пределах дерева классификации или дерева регрессии. |
4 (распределение) | Конечный узел, находящийся внутри дерева классификации или дерева регрессии. |
25 (дерево регрессии) | Родительский узел для деревьев регрессии в модели. Помечается "Все". |
NODE_CAPTION Понятное имя, применяемое для отображения.
При создании модели в качестве заголовка автоматически используется значение NODE_UNIQUE_NAME. При этом предусмотрена возможность изменить значение NODE_CAPTION для обновления отображаемого имени кластера либо программным путем, либо с использованием средства просмотра. Заголовок автоматически создается моделью. Содержимое заголовка зависит от типа модели и типа узла.
В модели дерева принятия решений элементы NODE_CAPTION и NODE_DESCRIPTION имеют различное содержание в зависимости от уровня в дереве. Дополнительные сведения и примеры см. в разделе Заголовок узла и описание узла.
CHILDREN_CARDINALITY
Оценка количества дочерних узлов, которые имеет данный узел.
Родительский узел Указывает количество смоделированных прогнозируемых атрибутов. Для каждого прогнозируемого атрибута создается дерево.
Узел дерева Узел Все для каждого дерева показывает, сколько значений было использовано для целевого атрибута.
Если целевой атрибут является дискретным, это значение равно количеству уникальных значений плюс 1 для состояния Missing.
Если прогнозируемый атрибут является непрерывным, это значение показывает, сколько сегментов было использовано для моделирования непрерывного атрибута.
Конечные узлы Значение всегда равно 0.
PARENT_UNIQUE_NAME
Уникальное имя родителя узла. Для любых узлов на корневом уровне возвращается значение NULL.
NODE_DESCRIPTION
Описание узла.
В модели дерева принятия решений элементы NODE_CAPTION и NODE_DESCRIPTION имеют различное содержание в зависимости от уровня в дереве.
Дополнительные сведения и примеры см. в разделе Заголовок узла и описание узла.
NODE_RULE
XML-описание правила, которое описывает путь к текущему узлу от его непосредственного родителя.
Дополнительные сведения и примеры см. в разделе Правило узла и граничное правило.
MARGINAL_RULE
XML-описание правила, которое описывает путь от родительского узла модели к текущему узлу.
Дополнительные сведения см. в разделе Правило узла и граничное правило.
NODE_PROBABILITY
Вероятность, связанная с этим узлом.
Дополнительные сведения см. в разделе Вероятность.
MARGINAL_PROBABILITY
Вероятность доступа к узлу от родительского узла.
Дополнительные сведения см. в разделе Вероятность.
NODE_DISTRIBUTION
Таблица, содержащая гистограмму вероятности узла. Данные в этой таблице различаются в зависимости от того, является ли прогнозируемый атрибут непрерывной или дискретной переменной.
Коневой узел модели Эта таблица пуста.
Узел (Все) Содержит сводку по модели в целом.
Внутренний узел Содержит статистические данные по конечным узлам.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
