

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Очистка данных связана с интеграцией данных из неоднородных источников, проблемой, которую изучают уже много лет. На сегодняшний день основные усилия концентрируются на проблемах несогласованности данных, а не на проблемах несогласованности схем. Хотя очистка данных в последнее время привлекает большое внимание исследователей, предстоит еще немало сделать для создания инструментальных средств, не зависящих от предметной области, которые решают разнообразные проблемы очистки данных, связанные с разработкой хранилищ.
Система поддержки принятия решений для предсказания катастрофических наводнений и оценки ущерба от них предложенная в БГУ базируется на персональных компьютерах.
В частности система поддержки принятия решений для предсказания катастрофических наводнений и оценки ущерба для поймы реки Припять создавалась усилиями 6 организаций на языке Avenue ГИС ArcView.
Выработка решения происходит в результате итерационного процесса, в котором участвуют:
- система поддержки принятия решений в роли вычислительного звена и объектов управления;
- человек как управляющее звено, задающее входные данные и оценивающее полученный результат вычислений на компьютере.
Дополнительно к этой особенности ИТ поддержки принятия решений можно указать ещё ряд её отличительных характеристик:
- ориентация на решение плохо структурированных (формализованных) задач;
- сочетание традиционных методов доступа и обработки компьютерных данных с возможностями математических моделей и методами решения задач на их основе;
- направленность на непрофессионального пользователя компьютера;
- высокая адаптивность, обеспечивающая возможность приспосабливаться к особенностям имеющегося технического и программного обеспечения, а также требованиям пользователя. Технология включает в себя взаимодействие моделей, данных и интерфейса с принимающим решение объектом.
В системах поддержки принятия решений база моделей состоит из стратегических, тактических и оперативных моделей, а также математических моделей в виде совокупности модельных блоков, модулей и процедур, используемых как элементы для их построения.
Стратегические модели используются на высших уровнях управления для установления целей организации, объёмов ресурсов, необходимых для их достижения, а также политики приобретения и использования этих ресурсов. Для этих моделей характерны значительная широта охвата, множество переменных, представления данных в сжатой агрегированной форме. Часто эти данные базируются на внешних источниках и могут иметь субъективный характер. Эти модели обычно детерминированные, описательные, специализированные для решения одной задачи.
Тактические модели применяются на промежуточных уровнях (распределение и контроль ресурсов, финансовое планирование, планирование требований к работникам, планирование увеличения продаж, построения схем компоновки предприятий). Здесь также могут потребоваться данные из внешних источников, но основное внимание при реализации данных моделей уделяется имеющимся данным. Обычно тактические модели реализуются как детерминированные, оптимизационные и универсальные.
Оперативные модели используются на низших уровнях управления для поддержки принятия оперативных решений с горизонтом, измеряемым днями и неделями. Оперативные модели обычно используют для расчётов внутрифирменные данные. Они, как правило, детерминированные, оптимизационные и универсальные.
Математические модели состоят из совокупности модельных блоков, модулей и процедур, реализующих математические методы. Сюда могут входить процедуры линейного программирования, статистического анализа временных рядов, регрессионного анализа и т. п. - от простейших до сложных процедур. Модельные блоки, модули и процедуры могут использоваться как поодиночке, так и комплексно для построения и поддержания моделей.
Система управления базой моделей должна обладать следующими возможностями: создавать новые модели или изменять существующие, поддерживать и обновлять параметры моделей, манипулировать моделями.
Интерфейс. В СППР необходимо должное внимание уделить и интерфейсному наполнению диалога: программа - специалист. Эффективность и гибкость ИТ во многом зависят от характеристики интерфейса системы поддержки принятия решений. Интерфейс определяет: язык пользователя; язык сообщений компьютера, организующий диалог на экране дисплея; знание пользователя.
Форма предоставления выходных данных все чаще использует 3D виртуальные модели процессов и объектов. Важным измерителем эффективности используемого интерфейса является выбранная форма диалога между пользователем и системой. В настоящее время наиболее распространены следующие формы диалога: запросно-ответный режим, командный режим, режим меню, режим заполнения пропусков в выражениях, предлагаемых компьютером.
Долгое время единственной реализацией языка сообщений был отпечатанный или выведенный на экран дисплея отчет или сообщение. Теперь появилась новая возможность представления выходных данных - машинная графика. Она дает возможность создавать на экране и бумаге цветные графические изображения в трехмерном виде. Использование машинной графики, значительно повышающее наглядность и интерпретируемость выходных данных, становится все более популярным в информационной технологии поддержки принятия решений.
Наметилось новое направление, развивающее машинную графику, - мультипликация 3D объектов и сцен. Мультипликация оказывается особенно эффективной для интерпретации выходных данных систем поддержки принятия решений, связанных с моделированием физических систем и объектов. Передача информации через форму, взаимное расположение, движение, цвет тесно связана с использованием основного биологического канала восприятия окружающего мира человека.
3.6. Методы теории игр в принятии решений
Состязательные задач при принятии решения это задачи маскировки, противодействия и т. п. В них решение принимает не одно лицо, а два или большее число лиц. При этом либо оба лица стремятся "выиграть" (максимизировать свои целевые функции), либо одно лицо не стремится этого сделать (игры с природой).
Решению подобных состязательных задач посвящена теория игр. Стороны или лица, принимающие решения в состязательных задачах, называются игроками.
Задача относится к теории игр, если:
а) результат решения задачи зависит от решения двух или более лиц, которые принимают эти решения независимо;
б) решения игроками принимаются в условиях неопределенности.
Постановка задачи. Пусть имеется два лица (первое и второе) и оба эти лица стремятся получить максимальную выгоду. Следовательно, имеется две целевые функции: Q1 (x, y) – функция выигрыша первого лица, Q2 (x, y) – функция выигрыша второго лица, где x, y – решения, принимаемые соответственно первым и вторым лицом.
Значение целевой функции первого игрока зависит не только от его решения x, которое он примет, но и от решения y, которое примет второй игрок. То же можно сказать и о целевой функции Q2 (x, y) второго.
Если бы решение у второго игрока было бы точно известно, то для первого игрока выбор оптимального решения х* был бы традиционным
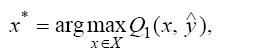
где ^y – известное решение второго лица, Х – множество возможных решений первого лица.
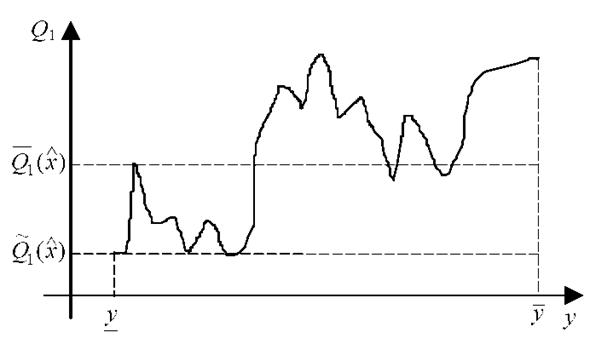
Рис. 3.21. Зависимость целевой функции первого игрока от решения второго игрока
Совсем иначе обстоит дело, если решение у второго лица неизвестно. В этом случае необходимо оценивать "удачность" выбора решения х, так как значение целевой функции Q1 (x, y) зависит не только от х, но и от у, что иллюстрируется, например, графиком рис. 3.21.
Новая оценочную функцию Q^1(x) позволит бы сравнивать какое из решений х1 или х2 первого лица "лучше".
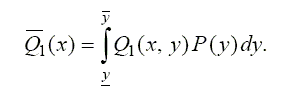
Эта оценка является хорошей, она учитывает вклад каждого решения второго лица и вероятность принятия таких решений. Однако, в этом случае необходимо знать вероятность принятия решения вторым лицом или плотность распределения вероятности, если множество Х является континуумом. То же самое относится, очевидно, и к функции Q2 ( y). Если Р(у) не известно, то вычислить Q1( y) или Q2 ( y) невозможно, следует выбрать новую оценку "хорошего " решения.
Естественной оценкой в этом случае является "наихудшее" (минимальное) значение целевой функции
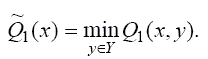
Чем больше минимальный выигрыш Q1 x, тем лучше х. Эта оценка слишком осторожна: на самом деле выигрыш получится больше, получиться меньше он уже не может. Такую оценку называют гарантированным выигрышем.
В теории игр принята следующая терминология.
Лица, принимающие решения, называются игроками.
Целевые функции называются платежными функциями, и считается, что они показывают выигрыш игрока. Так, платежная функция
Q1 (x1, …, xn) показывает выигрыш первого игрока. Множество возможных решений Хi каждого игрока называется множеством чистых стратегий i-го игрока, а решение хi из множества чистых стратегий Xi, называется чистой стратегией i-го игрока.
Таким образом, чистой стратегией является то, что раньше называлось решением (управлением).
Отрицательное значение платежной функции означает "проигрыш" игрока. Целью первого игрока является максимизация выигрыша. Очевидно, что целью первого игрока могла бы быть минимизация функции проигрыша Q1 (x, y), которая равна функции выигрыша, взятой с обратным знаком
Q1 (x, y) = –Q1 (x, y).
Следовательно, Q1 (x, y) = 5 означает, что первый игрок проиграл 5 единиц, а Q1 (x, y) = –5 означает, что первый игрок выиграл 5 единиц.
Эти две задачи имеют, очевидно, право на существование, однако, в теории игр первый игрок всегда полагается выигрывающим, и платежная функция Q1 (x, y) определяет его выигрыш. Проигрышу соответствует отрицательное значение Q1 (x, y).
Аналогичные замечания могут быть отнесены к платежной матрице Qi любого i-го игрока.
В теории игр используется такое понятие как смешанная стратегия, являющаяся более сложной конструкцией, использующая понятие чистой стратегии. Пусть Х – множество чистых стратегий, а х1, х2, …, хn – n чистых стратегий из этого множества. Пусть игрок принимает решение использовать все эти чистые стратегии с разными вероятностями
ξ1, ξ2, …, ξn. При этом игрок выбирает (варьирует) не чистые стратегии х1, х2, …, хn – они всегда заданы (одинаковые), а частоту (вероятность) использования каждой из них.
В этом случае стратегией будет вектор вероятностей ξ = (ξ1, ξ2, …, ξn), игрок должен пытаться найти такую стратегию (такое значение) ξ, при которой он получит максимальный успех.
Стратегия выбора вероятности ξ называется смешанной стратегией.
Рассмотрим следующий пример. Так, чистыми стратегиями является установка орудия на север, юг, запад, восток. Смешанная стратегия ξ = (0,1; 0,5; 0,2; 0,2) означает, что 10 % времени орудие смотрит на север,
50 % на юг и по 20 % времени оно повернуто на запад и восток.
Принятие чистой стратегии означает, что игрок принял решение истратить все ресурсы на одно решение.
Более сложные стратегии бывают в пошаговых (динамических играх), когда на каждом шаге оценивается ситуация предыдущих решений.
В общем случае стратегией называется набор правил, определяющих ход игры.
Если каждый из игроков выбрал стратегию, то совокупность этих стратегий называется ситуацией.
Пусть в игре двух игроков первый игрок выбрал чистую стратегию х, а второй – чистую стратегию у, тогда ситуацией будет вектор (х, у).
Ситуацией в смешанных стратегиях будет вектор (ξ, η), где ξ = (ξ1, …, ξn) – смешанная стратегия первого игрока, η = (η1, …, ηm) – смешанная стратегия второго игрока, ξi – вероятность использования чистой стратегии xi первым игроком, ηi – вероятность использования чистой стратегии yi вторым игроком.
Если ситуация сформулирована, то говорят, что игра состоялась.
Оценка стратегии игрока проводится по гарантированному выигрышу, т. е. по значению минимального выигрыша для данной стратегии. Так, для первого игрока оценка стратегии х проводится по функции
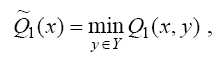
в случае применения чистой стратегии или по функции
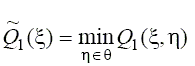
в случае применения смешанной стратегии, где θ – множество значений вектора вероятности η = (η1, …, ηm) второго игрока.
Очевидно, первому игроку хотелось бы выбрать такое х* или такой вектор ξ*, при котором гарантированный выигрыш Q1 x принял бы максимальное значение
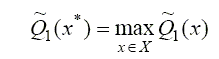 ,
,
или
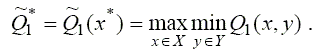
Стратегия х*, доставляющая максимум гарантированному выигрышу Q~ первого игрока, называется максиминной
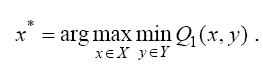
Второму игроку также хотелось бы получить максимальное значение своего гарантированного выигрыша, который определяется аналогичным образом
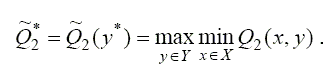
Однако ситуация (х*, у*) не всегда может считаться наилучшей. Действительно, х* – наилучшая стратегия, если у любая, а если у принимает конкретное значение у*, то, очевидно, что в общем случае можно найти другое х**, при котором Q1 (x**, y**) будет больше, чем Q1 (x*, y*).
Наилучшей ситуацией будет такая ситуация, при которой ни первому, ни второму игроку не выгодно от нее отклоняться. В теории игр такая ситуация носит название равновесной
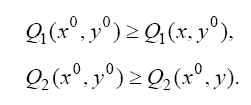
Решением игровой задачи является нахождение наилучшей равновесной ситуации. Эта ситуация называется оптимальной.
Задачей теории игр является разработка алгоритмов нахождения равновесной (оптимальной) ситуации.
Классификация игровых задач. Классификация игр, используемых в игровых задачах, представлена ниже.
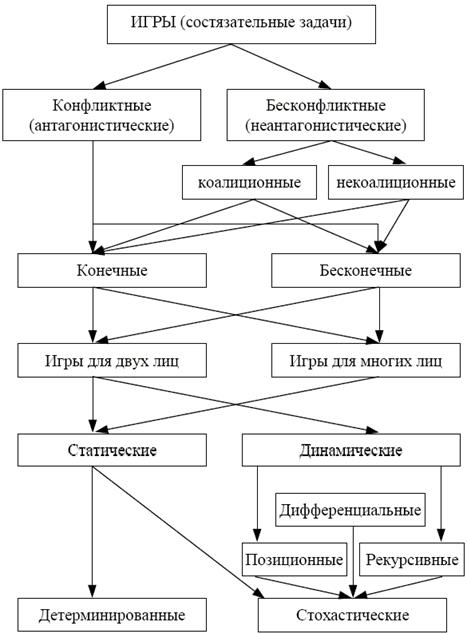
Рис.3.22. Виды моделей игры
Антагонистические игры моделируют конфликтные ситуации двух или многих лиц, интересы которых противоположны. Например, в случае двух игроков выигрыш одного равен проигрышу другого.
Неантагонистические игры (бесконфликтные) – это игры, в которых интересы сторон частично могут совпадать, они не являются диаметрально противоположными. Неантагонистические игры делятся на коалиционные и некоалиционные.
В коалиционных играх игроки могут договориться о целях, составить договор, объединиться.
Все игры делятся на конечные и бесконечные.
Конечными играми называются игры, имеющие конечное или счетное множество стратегий. В таких играх стратегии можно пометить цифрами i = 1, 2, …, n. Таким образом, вместо множества Х имеем множество (конечное или счетное) стратегий I = { i / 1, 2, …, n} – первого игрока и J = { j / 1, 2, …, m} – второго игрока.
Бесконечными называются игры, в которых множество стратегий хотя бы одного игрока – континуум, т. е. непрерывно.
Статическая игра – это игра, в которой игроки выбирают свои стратегии только один раз, и эти стратегии сохраняются во всех играх.
В динамической игре стратегия меняется во времени, при этом используется информация о развитии игры в прошлом. Динамические игры – многодневные.
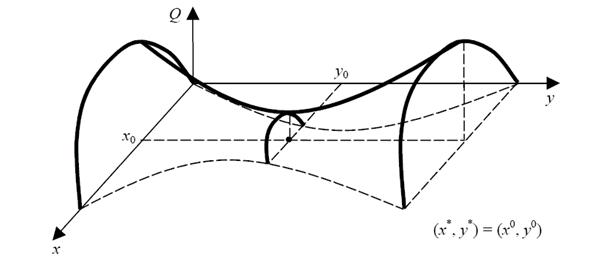
Рис. Графическая иллюстрация оптимального решения в антагонистической игре с седловой точкой
При анализе игровых задач широко используются и графические 3D образы результатов анализа. Например, ситуация с минимаксной и максиминной стратегиями двух игроков является оптимальной и является решением игры при наличии седловой точки, т. е. ν = ν .
Для расшифровки термина "седловая точка" рассмотрим непрерывную задачу.
Итак, х ![]() Х, у
Х, у ![]() Y, х и у непрерывны, вместо платежной матрицы имеется платежная функция для первого игрока Q (x, y). При этом, как и раньше выигрыш одного игрока равен проигрышу другого.
Y, х и у непрерывны, вместо платежной матрицы имеется платежная функция для первого игрока Q (x, y). При этом, как и раньше выигрыш одного игрока равен проигрышу другого.
Максиминная стратегия первого игрока и минимаксная стратегия второго игрока находятся аналогичным образом дискретному случаю, т. е.
Если ν = ν , то имеется седловая точка (она же оптимум) . Графическая иллюстрация рассматриваемого непрерывного случая представлена выше.
3.7. Анализ ситуаций в системах защиты информации. Деревья принятия решений
Специфика оценки ситуации при защите информации в ее сопровождающем характере основного программного продукта, базы данных, знаний, основной архитектуры проекта. Часто это выглядит как построение и анализ дерева принятия решений.
Дерево напоминает граф. Узлы дерева (листья так же узлы) содержат атрибуты, по которым различаются ситуации. В листьях находятся значения целевой функции. На ветвях (ребрах) значения атрибутов. Чтобы классифицировать новый случай нужно по дереву дойти до листа и получить нужное значение.
Это графическая структура, являющаяся результатом анализа рекомендуемых целесообразных последовательностей решений. Введем условности (они не устоялись и имеют различия в исходных источниках). Структура состоит из множества узлов, листов и указателей. Узел прямоугольник – анализ в старшей системе принятия решения (лицо принимающее решение (ЛПР) или программный агент старшего уровня). Узел круг - автоматическая проверка. Лист – решение. Стрелка (указатель) - результат проверки признака, выполнения теста.
Один из вариантов построения дерева решений в предварительном анализе возможных состояний по графам. На рис. 3.26 приведен граф состояний системы из двух устройств, дублирующих работу друг друга.
Отказ системы возможен только в одном узле. Он принесет определенные потери. Но каждый узел это состояние системы (внешние условия) предоставляет различные варианты u1, u2, …
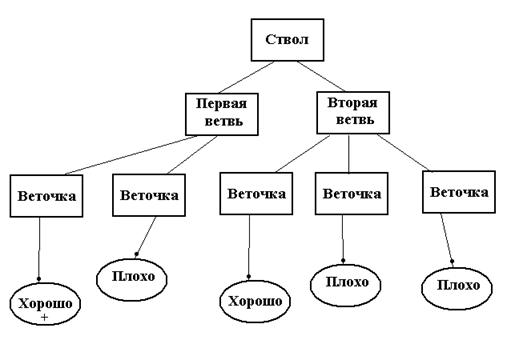
Рис. Дерево с двумя вариантами выбора и различными обстоятельствами в реализации альтернатив
Построение дерева процесс итерационный. В данном случае часть множества решений будет выглядеть:
− Не проводить тестирование.
− Тестировать устройство b1.
− Ремонтировать устройство b1.
− Тестировать устройство b2.
− Ремонтировать устройство b2.
− Тестировать и ремонтировать устройство b1 и далее устройство b2.
− Тестировать и ремонтировать устройство b2 и далее устройство b1.
Каждый вид работы имеет свою стоимость и может изменять состояние системы.
Методология деревьев решений является важным инструментом в работе специалистов, занимающихся анализом данных. Деревья решений являются инструментом в системах поддержки принятия решений, интеллектуального анализа данных.
В состав многих пакетов, предназначенных для интеллектуального анализа данных, уже включены методы построения деревьев решений.
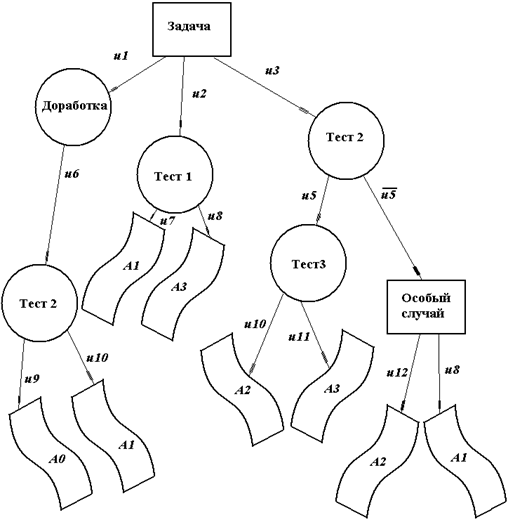
Рис. 3.25. Вид дерева принятия решений с листьями четырех решений
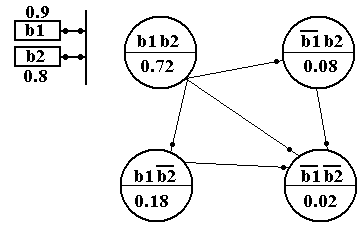
Рис. 3.26. Граф состояний системы с элементами дублирования
Фактически деревья классификации являются и инструментом распознавания образов.
В областях, где высока цена ошибки, они служат подспорьем аналитика. Ниже, почти без искажений, приведены работы [52].
Деревья решений широко применяются для решения практических задач в следующих областях:
1. Банковское дело. Оценка кредитоспособности клиентов банка при выдаче кредитов.
2. Промышленность. Контроль за качеством продукции (выявление дефектов), испытания без разрушений (например, проверка качества сварки) и т. д.
3. Медицина. Диагностика различных заболеваний.
4. Молекулярная биология. Анализ строения аминокислот.
Первые идеи создания деревьев решений восходят к работам Ховленда (Hoveland) и Ханта(Hunt) конца 50-х годов XX века. Однако, основополагающей работой, давшей импульс для развития этого направления, явилась книга Ханта (Hunt, E. B.), Мэрина (Marin J.) и Стоуна (Stone, P. J) "Experiments in Induction", увидевшая свет в 1966г.
Деревья решений – это прием представления последовательностей выборов в иерархической, последовательной структуре узлов, где каждому объекту (действию) соответствует единственный узел,
конечный узел дерева - узел решения это лист. Дерево начинается с исходного узла (постановочного). Постановочный узел и некоторые другие, требующие действий человека (лицо принимающее решение (ЛПР)) часто обозначают прямоугольником, остальные узлы как правило схожи по начертанию с узлами графов.
Под правилом понимается логическая конструкция, представленная в виде "если... то ...".
Деревья в определенном смысле специфичны. Например, дерево сортировки (выбора) можно представить как последовательность выбора по условиям (тестам):
Область применения деревья решений в настоящее время расширяется, охватывая в системном анализе три большие группы задач:
Описание данных: Деревья решений позволяют хранить информацию о данных и содержат описание объектов (прошедших сортировку по условиям).
Классификация: Деревья решений в задачах классификации относят объекты к одному из заранее известных классов.
Регрессия: Если целевая переменная имеет непрерывные значения, деревья решений позволяют установить зависимость целевой переменной от независимых (входных) переменных. Например, к этому классу относятся задачи численного прогнозирования(предсказания значений целевой переменной).
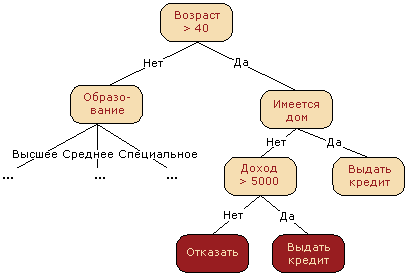
Рис. 3.27. Дерево решений при выдаче кредита
Пусть нам задано некоторое обучающее множество T, содержащее объекты (примеры), каждый из которых характеризуется m атрибутами, причем хотя бы один из них указывает на принадлежность объекта к определенному классу. Идею построения деревьев решений из множества T, впервые высказанную Хантом, приведем по Р. Куинлену (R. Quinlan). Пусть через {C1, C2, ... Ck} - классы и возможны ситуации:
множество T содержит один или более объектов, относящихся к одному классу Ck. Тогда дерево решений для Т – это лист, определяющий класс Ck;
множество T не содержит ни одного объекта, т. е. пустое множество. Тогда это снова лист, и класс, ассоциированный с листом, выбирается из другого множества отличного от T, скажем, из множества, ассоциированного с родителем;
множество T содержит объекты, относящиеся к разным классам. В этом случае следует разбить множество T на некоторые подмножества. Для этого выбирается один из признаков, имеющий два и более отличных друг от друга значений O1, O2, ... On. T разбивается на подмножества T1, T2, ... Tn, где каждое подмножество Ti содержит все объекты, имеющие значение Oi для выбранного признака. Это процедура будет рекурсивно продолжаться до тех пор, пока конечное множество не будет состоять из объектов, относящихся к одному и тому же классу.
Вышеописанная процедура лежит в основе многих современных алгоритмов построения деревьев решений, этот метод известен еще под названием разделения и захвата (divide and conquer). При использовании данной методики, построение дерева решений происходит сверху вниз.
Поскольку все объекты были заранее отнесены к известным нам классам, такой процесс построения дерева решений называется обучением с учителем. Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction). На сегодняшний день существует значительное число алгоритмов, реализующих деревья решений: CART, C4.5, NewId, ITrule, CHAID, CN2 и т. д. Но наибольшее распространение получили следующие два:
CART (Classification and Regression Tree) – это алгоритм построения бинарного дерева решений – дихотомической классификационной модели. Каждый узел дерева при разбиении имеет только двух потомков. Как видно из названия алгоритма, решает задачи классификации и регрессии.
C4.5 – алгоритм построения дерева решений, количество потомков у узла не ограничено. Не умеет работать с непрерывным целевым полем, поэтому решает только задачи классификации.
Большинство из известных алгоритмов после выбора атрибута и разбиения по нему на подмножества, не могут вернуться назад и выбрать другой атрибут, который дал бы лучшее разбиение. И поэтому на этапе построения нельзя сказать даст ли выбранный атрибут, в конечном итоге, оптимальное разбиение.
Этапы построения деревьев решений: Выбор критерия атрибута, по которому пойдет разбиение, остановка обучения и отсечение ветвей.
Для построения дерева на каждом внутреннем узле необходимо найти такой признак, который бы разбивал множество, ассоциированное с этим узлом на подмножества. В качестве такого условия должен быть выбран один из атрибутов. Общее правило для выбора атрибута можно сформулировать следующим образом: выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т. е. количество объектов из других классов ("примесей") в каждом из этих множеств было как можно меньше.
Рассмотрим некоторые из известных критериев разбиения:
Теоретико-информационный критерий.
Алгоритм C4.5, усовершенствованная версия алгоритма ID3 (Iterative Dichotomizer), использует теоретико-информационный подход. Для выбора наиболее подходящего атрибута, предлагается следующий критерий:
![]() , где Info(T) – энтропия множества T, и
, где Info(T) – энтропия множества T, и 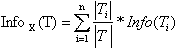 . Множества T1, T2, ... Tn получены при разбиении исходного множества T по проверке X. Последнее выражение учитывает и удельный вес подмножеств. Выбирается атрибут, дающий максимальное значение по предложенному критерию. Впервые эта мера была предложена Р. Куинленом в разработанном им алгоритме ID3. Кроме C4.5, есть еще целый класс алгоритмов, которые используют этот же критерий выбора атрибута.
. Множества T1, T2, ... Tn получены при разбиении исходного множества T по проверке X. Последнее выражение учитывает и удельный вес подмножеств. Выбирается атрибут, дающий максимальное значение по предложенному критерию. Впервые эта мера была предложена Р. Куинленом в разработанном им алгоритме ID3. Кроме C4.5, есть еще целый класс алгоритмов, которые используют этот же критерий выбора атрибута.
Статистический критерий
Алгоритм CART использует так называемый индекс Gini (в честь итальянского экономиста Corrado Gini), который оценивает "расстояние" между распределениями классов. ![]() , где c – текущий узел, а pj – вероятность класса j в узле c. CART был предложен Л. Брейманом (L. Breiman) и др.
, где c – текущий узел, а pj – вероятность класса j в узле c. CART был предложен Л. Брейманом (L. Breiman) и др.
При построении деревьев решений были предложены следующие правила:
Использование статистических методов для оценки целесообразности дальнейшего разбиения, так называемая "ранняя остановка" (prepruning). Для осторожности Л. Брейман и Р. Куинлен советуют буквально следующее: "Вместо остановки используйте отсечение".
Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение.
Разбиение должно быть нетривиальным, т. е. получившиеся в результате узлы должны содержать количества примеров превышающее пороговое.
Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые "переполнены данными", имеют много узлов и ветвей. Такие "ветвистые" деревья трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств.
Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое количество объектов из обучающей выборки.
Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей (pruning).
Пусть под “точностью” дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой – количество неправильно классифицированных, так же к общему. Если известен способ оценки ошибки дерева, ветвей и листьев, можно использовать и следующее простое правило: построить дерево и отсечь или заменить поддеревом те ветви, без существенного возрастания ошибки.
В отличии от процесса построения, отсечение ветвей происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом.
Хотя отсечение не является панацеей, но в большинстве практических задач дает хорошие результаты, что позволяет говорить о правомерности использования подобной методики.
Иногда даже усеченные деревья могут быть все еще сложны для восприятия. В таком случае, можно прибегнуть к методике извлечения правил из дерева с последующим созданием наборов правил, описывающих классы. Для извлечения правил необходимо исследовать все пути от корня до каждого листа дерева. Каждый такой путь даст правило. Условиями будут являться результаты проверок в узлах, встретившихся на пути.
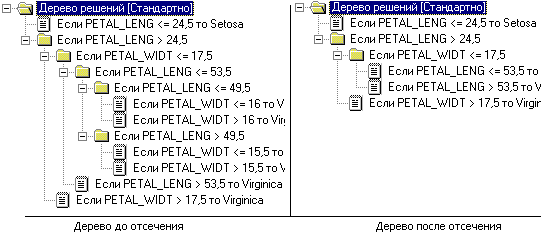
Рис.3.28. Дерево решений при отсечении
Деревья принятия решений имеют ряд преимуществ:
1. быстрый процесс обучения;
2. генерация правил в областях, где эксперту трудно формализовать свои знания;
3. извлечение правил на естественном языке;
4. интуитивно понятная классификационная модель;
5. высокая точность прогноза, сопоставимая с другими методами (статистика, нейронные сети);
6. построение непараметрических моделей.
7. Рассмотрим подробнее возможности и особенности популярных алгоритмов.
Деревья решений CART (Classification And Regression Tree) переводится как "Дерево Классификации и регрессии" – алгоритм бинарного дерева решений, впервые опубликованный Бриманом и др. в 1984 году.
Существует также несколько модифицированных версий – алгоритмы IndCART и DB-CART. Алгоритм IndCART, является частью пакета Ind и отличается от CART использованием иного способа обработки пропущенных значений, не осуществляет регрессионную часть алгоритма CART и имеет иные параметры отсечения.
Алгоритм DB-CART базируется на следующей идее: вместо того чтобы использовать обучающий набор данных для определения разбиений, используем его для оценки распределения входных и выходных значений и затем используем эту оценку, чтобы определить разбиения. DB, соответственно означает – "distribution based". Основными отличиями алгоритма CART от алгоритмов семейства ID3 являются:
− бинарное представление дерева решений;
− функция оценки качества разбиения;
− механизм отсечения дерева;
− алгоритм обработки пропущенных значений;
− построение деревьев регрессии.
− Бинарное представление дерева решений.
В алгоритме CART каждый узел дерева решений имеет двух потомков. На каждом шаге построения дерева правило, формируемое в узле, делит заданное множество примеров (обучающую выборку) на две части – часть, в которой выполняется правило (потомок – right) и часть, в которой правило не выполняется (потомок – left). Каждый узел (структура или класс) должен иметь ссылки на двух потомков Left и Right – аналогичные структуры. Также узел должен содержать идентификатор правила, описывающий правую часть правила, содержать информацию о количестве или отношении примеров каждого класса обучающей выборки "прошедшей" через узел и иметь признак терминального узла – листа. Таковы минимальные требования к структуре (классу) узла дерева.
Функция оценки качества разбиения.
Обучение дерева решений относится к классу обучения с учителем, то есть обучающая и тестовая выборки содержат классифицированный набор примеров. Оценочная функция, используемая алгоритмом CART, базируется на интуитивной идее уменьшения неопределённости в узле. Рассмотрим задачу с двумя классами и узлом, имеющим по 50 примеров одного класса. Узел имеет максимальную "нечистоту". Если будет найдено разбиение, которое разбивает данные на две подгруппы 40:5 примеров в одной и 10:45 в другой, то интуитивно "нечистота" уменьшится. Она полностью исчезнет, когда будет найдено разбиение, которое создаст подгруппы 50:0 и 0:50. В алгоритме CART идея "нечистоты" формализована в индексе Gini. Если набор данных Т содержит данные n классов, тогда индекс Gini определяется как:
![]() , где pi – вероятность класса i в T.
, где pi – вероятность класса i в T.
Если набор Т разбивается на две части Т1 и Т2 с числом примеров в каждом N1 и N2 соответственно, тогда показатель качества разбиения будет равен:
![]() .
.
Наилучшим считается то разбиение, для которого Ginisplit(T) минимально.
Обозначим N – число примеров в узле – предке, L, R – число примеров соответственно в левом и правом потомке, li и ri – число экземпляров i-го класса в левом/правом потомке. Тогда качество разбиения оценивается по следующей формуле:
![]()
Чтобы уменьшить объем вычислений формулу можно преобразовать:
![]()
Так как умножение на константу не играет роли при минимизации:
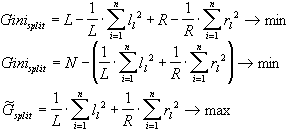
В итоге, лучшим будет то разбиение, для которого величина максимальна.
Правила разбиения.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
