

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вектор предикатных переменных, подаваемый на вход дерева, может содержать как числовые (порядковые) так и категориальные переменные. В любом случае в каждом узле разбиение идет только по одной переменной. Если переменная числового типа, то в узле формируется правило вида xi <= c. Где с – некоторый порог, который чаще всего выбирается как среднее арифметическое двух соседних упорядоченных значений переменной xi обучающей выборки. Если переменная категориального типа, то в узле формируется правило xi V(xi), где V(xi) – некоторое непустое подмножество множества значений переменной xi в обучающей выборке. Следовательно, для n значений числового атрибута алгоритм сравнивает n-1 разбиений, а для категориального (2n-1 – 1). На каждом шаге построения дерева алгоритм последовательно сравнивает все возможные разбиения для всех атрибутов и выбирает наилучший атрибут и наилучшее разбиение для него.
Предлагаемое алгоритмическое решение. Пусть источник данных - плоская таблица. Каждая строка таблицы описывает один пример обучающей/тестовой выборки.
Каждый шаг построения дерева фактически состоит из совокупности трех операций.
– сортировка источника данных по столбцу. Необходимо для вычисления порога, когда рассматриваемый в текущий момент времени атрибут имеет числовой тип. На каждом шаге построения дерева число сортировок будет как минимум равно количеству атрибутов числового типа.
– разделение источника данных. После того, как найдено наилучшее разбиение, необходимо разделить данные в соответствии с правилом формируемого узла и рекурсивно вызвать процедуру построения для двух половинок источника данных. Обе этих операции связаны с перемещением значительных объемов памяти. Здесь намеренно источник данных не называется таблицей, так как можно существенно снизить временные затраты на построение дерева, если использовать индексированный источник данных. Обращение к данным в таком источнике происходит не напрямую, а посредством логических индексов строк данных. Сортировать и разделять такой источник можно с минимальной потерей производительности.
Третья операция, занимающая 60–80% времени выполнения программы – вычисление индексов для всех возможных разбиений. Если у Вас n – числовых атрибутов и m – примеров в выборке, то получается таблица n*(m-1) – индексов., которая занимает объем памяти. Этого можно избежать, если использовать один столбец для текущего атрибута и одну строку для лучших (максимальных) индексов для всех атрибутов. Можно и вовсе использовать только несколько числовых значений, получив быстрый, однако плохо читаемый код. Значительно увеличить производительность можно, если использовать, что L = N – R, li = "ni" – ri, а li и ri изменяются всегда и только на единицу при переходе на следующую строку для текущего атрибута. То есть подсчет числа классов будет выполняться быстро, если знать число экземпляров каждого класса всего в таблице и при переходе на новую строку таблицы изменять на единицу только число экземпляров одного класса – класса текущего примера.
Все возможные разбиения для категориальных атрибутов удобно представлять по аналогии с двоичным представлением числа. Если атрибут имеет n – уникальных значений. 2n – разбиений. Первое (где все нули) и последнее (все единицы) нас не интересуют, получаем 2n – 2. И так как порядок множеств тоже неважен, получаем (2n – 2)/2 или (2n-1 – 1) первых (с единицы) двоичных представлений. Если {A, B, C, D, E} – все возможные значения некоторого атрибута X, то для текущего разбиения, которое имеет представление, скажем {0, 0, 1, 0, 1} получаем правило X in {C, E} для правой ветви и [ not {0, 0, 1, 0, 1} = {1, 1, 0, 1, 0} = X in {A, B, D} ] для левой ветви.
Часто значения атрибута категориального типа представлены в базе как строковые значения. В таком случае быстрее и удобнее создать кэш всех значений атрибута и работать не со значениями, а с индексами в кэше.
Механизм отсечения дерева.
Механизм отсечения дерева, оригинальное название minimal cost-complexity tree pruning, – наиболее серьезное отличие алгоритма CART от других алгоритмов построения дерева. CART рассматривает отсечение как получение компромисса между двумя проблемами: получение дерева оптимального размера и получение точной оценки вероятности ошибочной классификации.
Основная проблема отсечения – большое количество всех возможных отсеченных поддеревьев для одного дерева. Более точно, если бинарное дерево имеет |T| – листов, тогда существует ~[1.5028369|T|] отсечённых поддеревьев. И если дерево имеет хотя бы 1000 листов, тогда число отсечённых поддеревьев становится просто огромным. Базовая идея метода – не рассматривать все возможные поддеревья, ограничившись только "лучшими представителями" согласно приведённой ниже оценке.
Обозначим |T| – число листьев дерева, R(T) – ошибка классификации дерева, равная отношению числа неправильно классифицированных примеров к числу примеров в обучающей выборке. Определим C![]() (T) – полную стоимость (оценку/показатель затраты/сложность) дерева Т как: Cα(T) = R(T) + α *|T|. Полная стоимость дерева состоит из двух компонент – ошибки классификации дерева и штрафа за его сложность. Если ошибка классификации дерева неизменна, тогда с увеличением сложности дерева полная стоимость дерева будет увеличиваться. Менее ветвистое дерево, дающее большую ошибку классификации, может стоить меньше, чем дающее меньшую ошибку, но более ветвистое.
(T) – полную стоимость (оценку/показатель затраты/сложность) дерева Т как: Cα(T) = R(T) + α *|T|. Полная стоимость дерева состоит из двух компонент – ошибки классификации дерева и штрафа за его сложность. Если ошибка классификации дерева неизменна, тогда с увеличением сложности дерева полная стоимость дерева будет увеличиваться. Менее ветвистое дерево, дающее большую ошибку классификации, может стоить меньше, чем дающее меньшую ошибку, но более ветвистое.
Определим Tmax – максимальное по размеру дерево, которое предстоит обрезать. Если мы зафиксируем значение α, тогда существует наименьшее поддерево T(α), которое выполняет следующие условия:
Сα(T(α)) = minT <= Tmax Cα(T) - не существует такого поддерева дерева Tmax, которое имело бы меньшую стоимость, чем Т(α) при том же значении α.
if Cα(T) = Cα(T (α)) then T(α) <= T если существует более одного поддерева, имеющего данную полную стоимость, выбирается наименьшее и оно существует.
Не может быть такого, что два дерева достигают минимума полной стоимости и они несравнимы, т. е. ни одно из них не является поддеревом другого. Хотя имеет бесконечное число значений, существует конечное число поддеревьев дерева Tmax. Можно построить последовательность уменьшающихся поддеревьев дерева Tmax: T1 > T2 > T3 >...> {t1} , (где t1 – корневой узел дерева) такую, что Tk – наименьшее поддерево для [α k, α k+1). Это важный результат, так как это означает, что мы можем получить следующее дерево в последовательности, применив отсечение к текущему дереву. Это позволяет разработать эффективный алгоритм поиска наименьшего поддерева при различных значениях α. Первое дерево в этой последовательности – наименьшее поддерево дерева Tmax имеющее такую же ошибку классификации, как и Tmax, т. е. T1 = T(α = 0). Пояснение: если разбиение идет до тех пор, пока в каждом узле останется только один класс, то T1 = Tmax, но так как часто применяются методы ранней остановки (prepruning), тогда может существовать поддерево дерева Tmax имеющее такую же ошибку классификации.
Алгоритм вычисления T1 из Tmax. Нужно найти любую пару листов с общим предком, которые могут быть объединены, т. е. отсечены в родительский узел без увеличения ошибки классификации. R(t) = R(l) + R(r), где r и l – листы узла t. Продолжать процедуры необходимо до тех пор, пока таких пар больше не останется. Так мы получим дерево, имеющее такую же стоимость как Tmax при α = 0, но менее ветвистое, чем Tmax.
Как мы получаем следующее дерево в последовательности и соответствующее значение α? Обозначим Tt – ветвь дерева Т с корневым узлом t. При каких значениях дерево T – Tt будет лучше, чем Т? Если мы отсечём в узле t, тогда его вклад в полную стоимость дерева T – Tt станет Cα({t}) = R(t) + α, где
R(t) = r(t)* p(t), r(t) – это ошибка классификации узла t и p(t) – пропорция случаев, которые "прошли" через узел t. Альтернативный вариант: R(t)= m/n, где m – число примеров классифицированных некорректно, а n – общее число классифицируемых примеров для всего дерева.
Вклад Tt в полную стоимость дерева Т составит Cα(Tt) = R(Tt) + α |Tt|, где
![]() .
.
Дерево T – Tt будет лучше, чем Т, когда Cα({t}) = Cα(Tt), потому что при этой величине они имеют одинаковую стоимость, но T – Tt наименьшее из двух. Когда Cα({t}) = Cα(Tt) мы получаем:
![]()
решая для α, получаем: 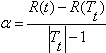 .
.
Так для любого узла t в Т1 ,если мы увеличиваем α, тогда когда
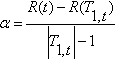 дерево, полученное отсечением в узле t, будет лучше, чем Т1.
дерево, полученное отсечением в узле t, будет лучше, чем Т1.
Основная идея состоит в следующем: вычислим это значение для каждого узла в дереве Т1, и затем выберем "слабые связи" (их может быть больше чем одна), т. е. узлы для которых величина 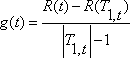 является наименьшей. Мы отсекаем Т1 в этих узлах, чтобы получить Т2 – следующее дерево в последовательности. Затем мы продолжаем этот процесс для полученного дерева и так пока мы не получим корневой узел (дерево в котором только один узел).
является наименьшей. Мы отсекаем Т1 в этих узлах, чтобы получить Т2 – следующее дерево в последовательности. Затем мы продолжаем этот процесс для полученного дерева и так пока мы не получим корневой узел (дерево в котором только один узел).
Алгоритм вычисления последовательности деревьев.
Т1 = Т(α=0)
α1 = 0
k = 1
while Tk > {root node} do begin
для всех нетерминальных узлов (!листов) в t Tk
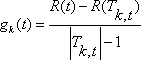
αk + 1 = mint gk(t)
Обойти сверху-вниз все узлы и обрезать те, где
gk(t) = αk + 1 чтобы получить Tk+1
k = k + 1
end
Узлы необходимо обходить сверху-вниз, чтобы не отсекать узлы, которые отсекутся сами собой, в результате отсечения n-го предка.
Рассмотрим метод подробнее на примере.
В качестве примера вычислим последовательность поддеревьев и соответствующих значений для дерева, изображенного на рис. 3.29.
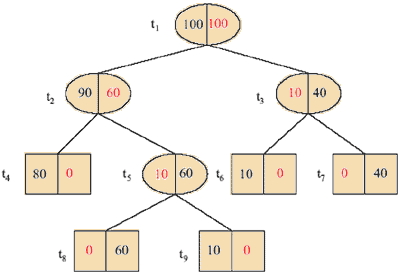
Рис.3.29. Дерево Тmax
Т1 = Тmax, так как все листы содержат примеры одного класса и отсечение любого узла (t3 или t5) приведёт к возрастанию ошибки классификации.
Затем мы вычисляем g1(t) для всех узлов t в Т1.
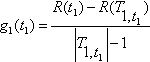
R(t1) – ошибка классификации. Если превратить t1 в лист, то следует сопоставить ему какой либо класс; так как число примеров обоих классов одинаково (равно 100), то класс выбираем наугад, в любом случае он неправильно классифицирует 100 примеров. Всего дерево обучалось на 200 примеров (100+100=200 для корневого узла). R(t1) = m/n. m=100, n=200. R(t1) = 1/2.
![]() – сумма ошибок всех листов поддерева. Считается как сумма по всем листам отношений количества неправильно классифицированных примеров в листе к общему числу примеров для дерева. В примере все делим на 200. Так как для поддерева с корнем в t1 оно же дерево Т1 все листы не имеют неправильно классифицированных примеров, поэтому
– сумма ошибок всех листов поддерева. Считается как сумма по всем листам отношений количества неправильно классифицированных примеров в листе к общему числу примеров для дерева. В примере все делим на 200. Так как для поддерева с корнем в t1 оно же дерево Т1 все листы не имеют неправильно классифицированных примеров, поэтому
![]() ,
, ![]() количество листов поддерева с корнем в узле t1. Итого их – 5.
количество листов поддерева с корнем в узле t1. Итого их – 5.
Получаем:
g1(t1) = (1/2 – 0)/(5 – 1) = 1/8.
g1(t2) = 3/20.
g1(t3) = 1/20.
g1(t5) = 1/20.
Узлы t3 и t5 оба хранят минимальное значение g1, мы получаем новое дерево Т2, обрезая Т1 в обоих этих узлах. Мы получили дерево, изображенное на рис.2.
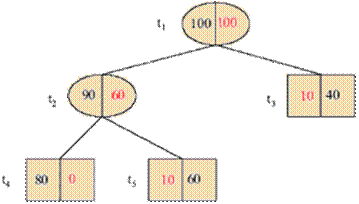
Рис.3.30. Дерево Т2
Далее мы продолжаем вычислять g-значение для Т2.
g2(t1) = (100/200 – (0/200 + 10/200 + 10/200)) / (3 – 1) = 2/10.
g2(t2) = (60/200 – (0/200 + 10/200)) / (2 – 1) = 1/4.
Минимум хранится в узле t1, поэтому мы обрезаемы в t1 и получаем корень дерева (T3 = {t1}). На этом процесс отсечения заканчивается.
Последовательность значений получается: α 1 = 0, α 2 = 1/20, α 3 = 2/10. Итак, Т1 является лучшим деревом для (0, 1/20), T2 – для (1/20, 2/10) и Т3 = {t1} для (2/10, ![]() ).
).
Выбор финального дерева.
Итак, мы имеем последовательность деревьев, нам необходимо выбрать лучшее дерево из неё. То, которое мы и будем использовать в дальнейшем. Наиболее очевидным является выбор финального дерева через тестирование на тестовой выборке. Дерево, давшее минимальную ошибку классификации, и будет лучшим. Однако, это не единственно возможный путь.
Итак, мы имеем последовательность деревьев, нам необходимо выбрать лучшее дерево из неё. То, которое мы и будем использовать в дальнейшем. Отметим, что отсечение дерева не использовало никаких других данных, кроме тех, на которых строилось первоначальное дерево. Даже не сами данные требовались, а количество примеров каждого класса, которое 'прошло' через узел.
Наиболее очевидным и возможно наиболее эффективным является выбор финального дерева посредством тестирования на тестовой выборке. Естественно, качество тестирования во многом зависит от объема тестовой выборки и 'равномерности' данных, которые попали в обучающую и тестовую выборки.
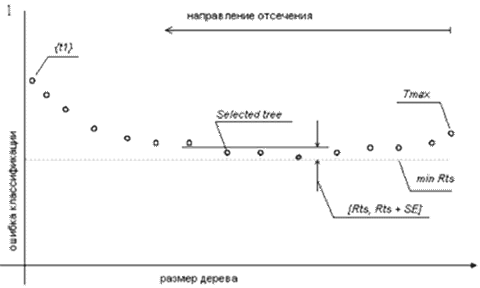
Рис.3.31. Зависимость ошибки от размера дерева
Часто можно наблюдать, что последовательность деревьев дает ошибки близкие друг к другу.
Эта длинная плоская последовательность очень чувствительна к данным, которые будут выбраны в качестве тестовой выборки. Чтобы уменьшить эту нестабильность CART использует 1-SE правило: выберите минимальное по размеру дерево с Rts в пределах интервала [min Rts, min min Rts + SE]. Rts – ошибка классификации дерева. SE – стандартная ошибка, являющаяся оценкой реальной ошибки.
![]() , где ntest – число примеров в тестовой выборке..
, где ntest – число примеров в тестовой выборке..
Перекрестная проверка.
Перекрестная проверка (V-fold cross-validation) – самая оригинальная и сложная часть алгоритма CART. Этот путь выбора финального дерева используется, когда набор данных для обучения мал или каждая запись в нем по своему 'уникальна' так, что мы не можем выделить выборку для обучения и выборку для тестирования.
В таком случае строим дерево на всех данных, вычисляем α 1, α 2, …, α k и T1 > T2 > … > TN. Обозначим Тk – наименьшее поддерево для (α k, α k+1).
Теперь мы хотим выбрать дерево из последовательности, но уже использовали все имеющиеся данные. Хитрость в том, что мы собираемся вычислить ошибку дерева Тk из последовательности косвенным путем.
Шаг 1.
Установим
![]()
Считается, что ![]() k будет типичным значением для (α k, α k+1) и, следовательно, как значение соответствует Tk.
k будет типичным значением для (α k, α k+1) и, следовательно, как значение соответствует Tk.
Шаг 2.
Разделим весь набор данных на V групп одинакового размера G1, G2, …, GV.
Бриман рекомендует брать V = 10. Затем для каждой группы Gi:
Вычислить последовательность деревьев с помощью описанного выше механизма отсечения на всех данных, исключая Gi. И определить T(i)(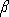 1), T(i)(
1), T(i)(![]() 2), …, T(i)(
2), …, T(i)(![]() N) для этой последовательности.
N) для этой последовательности.
Вычислить ошибку дерева T(i)<![]() k на Gi.
k на Gi.
Здесь T(i)(![]() k) означает наименьшее минимизированное поддерево из последовательности, построенное на всех данных, исключая Gi для T= k.
k) означает наименьшее минимизированное поддерево из последовательности, построенное на всех данных, исключая Gi для T= k.
Шаг 3.
Для каждого ![]() k суммировать ошибку T(i)(
k суммировать ошибку T(i)(![]() k) по всем Gi (i = 1, …, V). Пусть
k) по всем Gi (i = 1, …, V). Пусть ![]() h будет с наименьшей общей ошибкой. Так как h соответствует дереву Th, мы выбираем Th из последовательности, построенной на всех данных в качестве финального дерева. Показатель ошибки, вычисленный с помощью перекрестной проверки можно использовать как оценку ошибки дерева.
h будет с наименьшей общей ошибкой. Так как h соответствует дереву Th, мы выбираем Th из последовательности, построенной на всех данных в качестве финального дерева. Показатель ошибки, вычисленный с помощью перекрестной проверки можно использовать как оценку ошибки дерева.
Альтернативный путь –выбрать финальное дерево из последовательности и на последнем шаге можно опять использовать 1-SE правило.
Алгоритм обработки пропущенных значений.
Большинство алгоритмов Data Mining предполагает отсутствие пропущенных значений. В практическом анализе это предположение часто является неверным. Вот только некоторые из причин, которые могут привести к пропущенным данным:
Респондент не желает отвечать на некоторые из поставленных вопросов;
Ошибки при вводе данных;
Объединение не совсем эквивалентных наборов данных.
Наиболее общее решение – отбросить данные, которые содержат один или несколько пустых атрибутов. Однако это решение имеет свои недостатки:
Смещение данных. Если выброшенные данные лежат несколько 'в стороне' от оставленных, тогда анализ может дать предубеждённые результаты.
Убыток мощности. Может возникнуть ситуация, когда придется выбросить много данных. В таком случае точность прогноза сильно уменьшается.
Если мы хотим строить и использовать дерево на неполных данных нам необходимо решить следующие вопросы:
Как нам определить качество разбиения?
В какую ветвь нам необходимо послать наблюдение, если пропущена переменная, на которую приходится наилучшее разбиение (построение дерева и тренировка)?
Наблюдение с пропущенной меткой класса бесполезно для построения дерева и будет выброшено.
Чтобы определить качество разбиения CART просто игнорирует пропущенные значения. Это 'решает' первую проблему, но мы ещё должны решить, по какому пути посылать наблюдение с пропущенной переменной содержащей наилучшее разбиение. С этой целью CART вычисляет так называемое 'суррогатное' разбиение. Оно создает наиболее близкие к лучшему подмножества примеров в текущем узле. Чтобы определить значение альтернативного разбиения как суррогатного мы создаем кросс-таблицу.
p(l*, l') | p(l*, r') |
p(r*, l') | p(r*, r') |
В этой таблице p(l*,l') обозначает пропорцию случаев, которые будут посланы в левую ветвь при лучшем s* и альтернативном разбиении s' и аналогично для p(r*,r'), так p(l*,l') + p(r*,r') – пропорция случаев, которые посланы в одну и ту же ветвь для обоих разбиений. Это мера сходства разбиений или иначе: это говорит, насколько хорошо мы предсказываем путь, по которому послан случай наилучшим разбиением, смотря на альтернативное разбиение. Если p(l*,l') + p(r*,r') < 0.5, тогда мы можем получить лучший суррогат, поменяв левую и правую ветви для альтернативного разбиения. Кроме того, необходимо заметить, что пропорции в таблице 1 вычислены, когда обе переменные (суррогатная и альтернативная) наблюдаемы.
Альтернативные разбиения с p(l*,l') + p(r*,r') > max(p(l*), p(r*)) отсортированы в нисходящем порядке сходства. Теперь если пропущена переменная лучшего разбиения, тогда используем первую из суррогатных в списке, если пропущена она, тогда следующую т. д. Если пропущены все суррогатные переменные, используем max(p(l*), p(r*)).
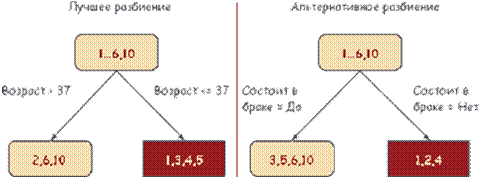
Рис.3.32. Лучшее и суррогатное разбиения.
На рис. 3.32 изображен пример лучшего и альтернативного разбиения. Каково значение альтернативного разбиения по супружескому статусу как суррогатного? Видно, что примеры 6 и 10 оба разбиения послали влево. Следовательно
p(l*,l') = 2/7. Оба разбиения послали примеры 1 и 4 направо – p(r*,r') = 2/7. Его значение как суррогатного есть
p(l*,l') + p(r*,r') = 2/7 + 2/7 = 4/7. Так как max(p(l*), p(r*)) = 4/7, поэтому разбиение по супружескому статусу не является хорошим суррогатным разбиением.
Регрессия. Построение дерева регрессии во многом схоже с деревом классификации. Сначала мы строим дерево максимального размера, затем обрезаем дерево до оптимального размера. Основное достоинство деревьев по сравнению с другими методами регрессии – возможность работать с многомерными задачами и задачами, в которых присутствует зависимость выходной переменной от переменной или переменных категориального типа.
Основная идея – разбиение всего пространства на прямоугольники, необязательного одинакового размера, в которых выходная переменная считается постоянной. Заметим, что существует сильная зависимость между объемом обучающей выборки и ошибкой ответа дерева.
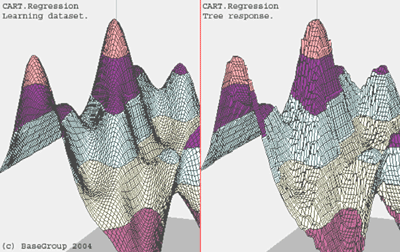
Рис.3.33. Пример двумерной задачи.
Процесс построения дерева происходит последовательно. На первом шаге мы получаем регрессионную оценку просто как константу по всему пространству примеров. Константу считаем просто как среднее арифметическое выходной переменной в обучающей выборке. Итак, если мы обозначим все значения выходной переменной как Y1, Y2, …, Yn, то регрессионная оценка получается:  , где R – пространство обучающих примеров, n – число примеров, Ir(x) – индикаторная функция пространства – фактически, набор правил, описывающих попадание переменной x в пространство. Мы рассматриваем пространство R как прямоугольник. На втором шаге мы делим пространство на две части. Выбирается некоторая переменная xi и если переменная числового типа, тогда мы определяем:
, где R – пространство обучающих примеров, n – число примеров, Ir(x) – индикаторная функция пространства – фактически, набор правил, описывающих попадание переменной x в пространство. Мы рассматриваем пространство R как прямоугольник. На втором шаге мы делим пространство на две части. Выбирается некоторая переменная xi и если переменная числового типа, тогда мы определяем:
![]() .
.
Если xi категориального типа с возможными значениями A1, A2, …, Aq, тогда выбирается некоторое подмножество I {A1, … An} и мы определяем
![]() .
.
Регрессионная оценка принимает вид:
![]() , где I1 = {i, xi R1} и |I1| – число элементов в I1.
, где I1 = {i, xi R1} и |I1| – число элементов в I1.
В качестве оценки предпочтения предлагается сумма квадратов разностей:
![]() .
.
Выбирается разбиение с минимальной суммой квадратов разностей.
Мы продолжаем разбиение до тех пор, пока в каждом подпространстве не останется малое число примеров или сумма квадратов разностей не станет меньше некоторого порога.
Отсечение, выбор финального дерева. Происходят аналогично дереву классификации. Единственное отличие – определение ошибки ответа дерева:
![]() , иначе говоря, среднеквадратичная ошибка ответа.
, иначе говоря, среднеквадратичная ошибка ответа.
Стоимость дерева равна:
![]() .
.
Остальные операции происходят аналогично, как и в деревьях классификации.
Алгоритм CART успешно сочетает в себе качество построенных моделей и, при удачной реализации, высокую скорость их построения. Включает в себя уникальные методики обработки пропущенных значений и построения оптимального дерева совокупностью алгоритмов cost-complexity pruning и V-fold cross-validation.
Метод построения деревьев решений C4.5 был предложен Р. Куинленом (R. Quinlan). Определим обязательные требования к структуре данных и непосредственно к самим данным, при выполнении которых алгоритм C4.5 будет работоспособен:
Описание атрибутов. Данные, необходимые для работы алгоритма, должны быть представлены в виде плоской таблицы. Вся информация об объектах (далее примеры) из предметной области должна описываться в виде конечного набора признаков (далее атрибуты). Каждый атрибут должен иметь дискретное или числовое значение. Сами атрибуты не должны меняться от примера к примеру, и количество атрибутов должно быть фиксированным для всех примеров.
Определенные классы. Каждый пример должен быть ассоциирован с конкретным классом, т. е. один из атрибутов должен быть выбран в качестве метки класса.
Дискретные классы. Классы должны быть дискретными, т. е. иметь конечное число значений. Каждый пример должен однозначно относиться к конкретному классу. Случаи, когда примеры принадлежат к классу с вероятностными оценками, исключаются. Количество классов должно быть значительно меньше количества примеров.
Алгоритм построения дерева.
Пусть нам задано множество примеров T, где каждый элемент этого множества описывается m атрибутами. Количество примеров в множестве T будем называть мощностью этого множества и будем обозначать |T|.
Пусть метка класса принимает следующие значения C1, C2 … Ck. Следует построить иерархическую классификационную модели в виде дерева из множества примеров T. Процесс построения дерева будет происходить сверху вниз. Сначала создается корень дерева, затем потомки корня и т. д.
На первом шаге - дерево пусто (имеется только корень) и исходное множество T (ассоциированное с корнем). Требуется разбить исходное множество на подмножества. Это можно сделать, выбрав один из атрибутов в качестве проверки. Тогда в результате разбиения получаются n (по числу значений атрибута) подмножеств и, соответственно, создаются n потомков корня, каждому из которых поставлено в соответствие свое подмножество, полученное при разбиении множества T. Затем эта процедура рекурсивно применяется ко всем подмножествам (потомкам корня) и т. д.
Рассмотрим подробнее критерий выбора атрибута, по которому должно пойти ветвление. Очевидно, что в нашем распоряжении m (по числу атрибутов) возможных вариантов, из которых мы должны выбрать самый подходящий. Любой из атрибутов можно использовать неограниченное количество раз при построении дерева.
Пусть проверка X (в качестве проверки может быть выбран любой атрибут) принимает n значений A1, A2 ... An. Тогда разбиение T по проверке X даст нам подмножества T1, T2 ... Tn, при X равном соответственно A1, A2… An. Априорная информация – то, каким образом классы распределены в множестве T и его подмножествах, получаемых при разбиении по X. Именно этим мы и воспользуемся при определении критерия.
Пусть ![]() – количество примеров из некоторого множества S, относящихся к одному и тому же классу Cj. Тогда вероятность того, что случайно выбранный пример из множества S будет принадлежать к классу Cj
– количество примеров из некоторого множества S, относящихся к одному и тому же классу Cj. Тогда вероятность того, что случайно выбранный пример из множества S будет принадлежать к классу Cj 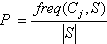 .
.
Количество содержащейся в сообщении информации 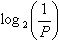 бит.
бит.
Выражение - 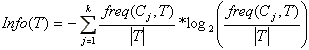 дает оценку среднего количества информации, необходимого для определения класса (энтропия множества).
дает оценку среднего количества информации, необходимого для определения класса (энтропия множества).
Ту же оценку, но только уже после разбиения множества T по X, дает следующее выражение: ![]() .
.
Тогда базовым критерием для выбора атрибута будет: 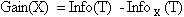
Он считается для всех атрибутов. Выбирается атрибут, максимизирующий данное выражение. Этот атрибут будет являться проверкой в текущем узле дерева, а затем по этому атрибуту производится дальнейшее построение дерева. В узле будет проверяться значение по этому атрибуту. Дальнейшее движение по дереву будет производиться в зависимости от полученного ответа.
Такие же рассуждения можно применить к полученным подмножествам T1, T2 … Tn и продолжить рекурсивно процесс построения дерева, до тех пор, пока в узле не окажутся примеры из одного класса.
Одно важное замечание: если в процессе работы алгоритма получен узел, ассоциированный с пустым множеством (т. е. ни один пример не попал в данный узел), то он помечается как лист, и в качестве решения листа выбирается наиболее часто встречающийся класс у непосредственного предка данного листа.
Критерий должен максимален. Из свойств энтропии нам известно, что максимально возможное значение энтропии достигается в том случае, когда все его сообщения равновероятны. В нашем случае, энтропия достигает своего максимума, когда частота появления классов в примерах множества T равновероятна. Нам же необходимо выбрать такой атрибут, чтобы при разбиении по нему один из классов имел наибольшую вероятность появления. Это возможно в том случае, когда энтропия будет иметь минимальное значение и, соответственно, критерий достигнет своего максимума.
В случае числовых атрибутов следует выбрать некий порог, с которым должны сравниваться все значения атрибута. Пусть числовой атрибут имеет конечное число значений. Обозначим их {v1, v2 … vn}. Предварительно отсортируем все значения. Тогда любое значение, лежащее между vi и vi+1, делит все примеры на два множества: те, которые лежат слева от этого значения {v1, v2 … vi}, и те, что справа {vi+1, vi+2 … vn}. В качестве порога можно выбрать среднее между значениями vi и vi+1![]() .
.
Таким образом, задача нахождения порога упростилась, и требует только n-1 потенциальных пороговых значений TH1, TH2 … THn-1.
Последовательно вычисляя энтропию по всем потенциальным пороговым значениям и выбирая среди них то, которое дает максимальное значение по критерию. Далее это значение сравнивается со значениями критерия, подсчитанными для остальных атрибутов. Если выяснится, что среди всех атрибутов данный числовой атрибут имеет максимальное значение по критерию, то в качестве проверки выбирается именно он. Следует отметить, что все числовые тесты являются бинарными, т. е. делят узел дерева на две ветви.
Классификация новых примеров. При применении построенного дерева решений для распознавания нового объекта обход дерева решений начнем с корня дерева. На каждом внутреннем узле проверяется значение объекта Y по атрибуту, который соответствует проверке в данном узле, и, в зависимости от полученного ответа, находится соответствующее ветвление, и по этой дуге двигаемся к узлу, находящему на уровень ниже и т. д. Обход дерева заканчивается как только встретится узел решения, который и дает название класса объекта Y.
Улучшенный критерий разбиения. Рассмотренный критерий имеет один недостаток – он "предпочитает" атрибуты, которые имеют много значений. Рассмотрим гипотетическую задачу медицинской диагностики, в котором один из атрибутов идентифицирует личность пациента. Поскольку здесь каждое значение атрибута уникальное, то при разбиении множества примеров по этому атрибуту получаются подмножества, содержащие только по одному примеру. Так как все эти множества "с одним примером", то и пример относится, соответственно, к одному единственному классу, тогда и 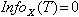 . Значит, рассмотренный критерий принимает свое максимальное значение, и несомненно, что именно этот атрибут будет выбран алгоритмом.
. Значит, рассмотренный критерий принимает свое максимальное значение, и несомненно, что именно этот атрибут будет выбран алгоритмом.
Однако, очевидна и вся бесполезность такой модели. Хотя на практике, не так часто встречаются подобные задачи, но, тем не менее, необходимо предусмотреть и такие случаи.
Проблема решается введением некоторой нормализации. Пусть суть информации сообщения, относящегося, к примеру, указывает не на класс, к которому пример принадлежит, а на выход. Тогда, по аналогии с определением Info(T), мы имеем![]() . Выражение оценивает потенциальную информацию, получаемую при разбиении множества T на n подмножеств.
. Выражение оценивает потенциальную информацию, получаемую при разбиении множества T на n подмножеств.
Рассмотрим следующее выражение: 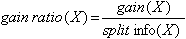 и примем его за критерий выбора атрибута.
и примем его за критерий выбора атрибута.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
