

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Эффект изоляции - тенденция к упрощению выбора путем исключения общих компонент вариантов решения.
Методы ТП, также как и предыдущие методы, имеют аксиоматические основы. Недостатком является то, что данный метод не снимает все проблемы, возникающие при изучении поведения людей в задачах выбора решения.
Главным недостатком всех перечисленных аксиоматических теорий является непроверяемый характер аксиом, что означает на практике требование к человеку принимать на веру правила рационального поведения, вытекающие из той или иной теории.
Методы ELECTRE. Французской школой теории принятия решений, возглавляемой Б. Руа, был предложен подход к выработке решений, в рамках которого методы, модели и концепции рассматриваются как вспомогательные средства практического анализа ситуации. Эти средства позволяют, как уяснить цели принятия решения, так и лучше понять предпочтения принятия решений. Недостатком методов ELECTRE является то, что они являются вспомогательными средствами, а не способом выработки лучшего решения как при аксиоматическом подходе.
Метод анализа иерархий (МАИ). Часто используемый метод принятия решений - МАИ, опирающийся на многокритериальное описание проблемы, был предложен и детально описан в своей работе "Принятие решений: метод анализа иерархий". В методе используется дерево критериев, в котором общие критерии разделяются на критерии частного характера. Для каждой группы критериев определяются коэффициенты важности. Альтернативы также сравниваются между собой по отдельным критериям с целью определения каждой из них. Средством определения коэффициентов важности критериев либо критериальной ценности альтернатив является попарное сравнение. Результат сравнения оценивается по бальной шкале. На основе таких сравнений вычисляются коэффициенты важности критериев, оценки альтернатив и находится общая оценка как взвешенная сумма оценок критериев.
Не смотря на то, что МАИ не имеет строгого научного обоснования и больше примыкает к эвристическим методам, этот метод нашел широкое практическое применение из-за своей простоты и наглядности. В ходе детального исследования МАИ были выявлены следующие существенные недостатки, такие как:
Рассогласование оценок, связанное с трудностями оценки отношений сложных элементов - 1-й вид рассогласования.
Рассогласование 2-го вида, связанное с предложенной дискретной шкалой для оценки элементов.
Резкое увеличение количества оценок с увеличением набора элементов. Не рекомендуется набор элементов больше 9.
Пересчет отношений значимости элементов в их важность осуществляется приближенным методом.
Эвристические методы. К эвристическим методам относят следующие методы:
Метод взвешенной суммы оценок критериев.
Каждой альтернативе дается числовая (бальная) оценка по каждому из критериев. Критериям приписывается количественные веса, характеризующие их сравнительную важность. Веса умножаются на критериальные оценки, полученные числа суммируются - так определяется ценность альтернативы. Далее выбирается альтернатива с наибольшим показателем ценности.
Метод компенсации.
Данный метод используется при попарном сравнении альтернатив.
Достоинством всех эвристических методов является простота и удобство, а основным недостатком то, что все они не имеют научного обоснования.
Таким образом, проведенный анализ показал, что рассмотренные методы, положенные в основу теории принятия решения, носят аксиоматический и эвристический характер, т. е. не имеют строгого научного доказательства. Данные методы не позволяют автоматизировать процесс принятия решения, так как выработка окончательного решения всегда остается за командиром. Поэтому, предложен подход, ориентированный на методы интеллектуального анализа данных, необходимых ЛПР в процессе принятия решения. Данный подход основывается на методах машинного обучения, которые лежат в основе современных информационных технологий интеллектуальной обработки данных.
Метод опорных векторов (SVM — support vector machines) — это набор схожих алгоритмов вида «обучение с учителем», использующихся для задач классификации и регрессионного анализа. Этот метод принадлежит к семейству линейных классификаторов. Он может также рассматриваться как специальный случай регуляризации по А. Н. Тихонову. Особым свойством метода опорных векторов является непрерывное уменьшение эмпирической ошибки классификации и увеличение зазора. Поэтому этот метод также известен как метод классификатора с максимальным зазором.
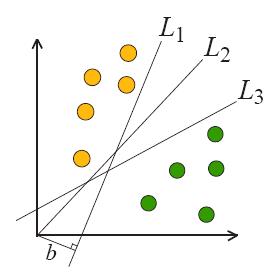
Рис.3.1. Прямые предпочтения
Несколько классифицирующих разделяющих прямых (гиперплоскостей). Но только одна достигает оптимального разделения.
Часто в алгоритмах машинного обучения возникает необходимость классифицировать данные. Каждый объект данных представлен как вектор (точка) в p-мерном пространстве (последовательность p чисел). Каждая из этих точек принадлежит только одному их двух классов. Нас интересует, можем ли мы разделить точки гиперплоскостью размерностью «p−1». Таких гиперплоскостей может быть много. Поэтому вполне естественно полагать, что максимизация зазора между классами способствует более уверенной классификации. То есть, можем ли мы найти такую гиперплоскость, чтобы расстояние от нее до ближайшей точки было максимальным. Это бы означало, что расстояние между двумя ближайшими точками, лежащими по разные стороны гиперплоскости, максимально. Если такая гиперплоскость существует, то она нас будет интересовать больше всего, она называется оптимальной разделяющей гиперплоскостью, а соответствующий ей линейный классификатор называется оптимально разделяющим классификатором.
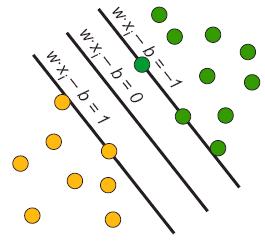
Рис. 3.2. Движение разделяющей полосы
Мы полагаем, что точки имеют вид:
![]() , где ci принимает значение 1 или −1, в зависимости от того, какому классу принадлежит точка
, где ci принимает значение 1 или −1, в зависимости от того, какому классу принадлежит точка ![]() . Каждое
. Каждое ![]() это p-мерный вещественный вектор, обычно нормализованный значениями [0,1] или [-1,1]. Если точки не будут нормализованы, то точка с большими отклонениями от средних значений координат точек слишком сильно повлияет на классификатор. Мы можем рассматривать это, как учебную коллекцию, в которой для каждого элемента уже задан класс, к которому он принадлежит. Мы хотим, чтобы алгоритм метода опорных векторов классифицировал их таким же образом. Для этого мы строим разделяющую гиперплоскость, которая имеет вид:
это p-мерный вещественный вектор, обычно нормализованный значениями [0,1] или [-1,1]. Если точки не будут нормализованы, то точка с большими отклонениями от средних значений координат точек слишком сильно повлияет на классификатор. Мы можем рассматривать это, как учебную коллекцию, в которой для каждого элемента уже задан класс, к которому он принадлежит. Мы хотим, чтобы алгоритм метода опорных векторов классифицировал их таким же образом. Для этого мы строим разделяющую гиперплоскость, которая имеет вид:
Рис. 3.3. Движение гиперплоскости
Оптимальная разделяющая гиперплоскость для метода опорных векторов, построенная на точках из двух классов. Ближайшие к параллельным гиперплоскостям точки называются опорными векторами.
![]()
Вектор ![]() — перпендикуляр к разделяющей гиперплоскости. Параметр b зависит от кратчайшего расстояния гиперплоскости до начала координат. Если параметр b равен нулю, гиперплоскость проходит через начало координат, что ограничивает решение.
— перпендикуляр к разделяющей гиперплоскости. Параметр b зависит от кратчайшего расстояния гиперплоскости до начала координат. Если параметр b равен нулю, гиперплоскость проходит через начало координат, что ограничивает решение.
Так как нас интересует оптимальное разделение, нас интересуют опорные вектора и гиперплоскости параллельные оптимальной и ближайшие к опорным векторам двух классов. Можно показать, что эти параллельные гиперплоскости могут быть описаны следующими уравнениям (с точностью до нормировки).
![]()
![]()
Если учебная коллекция линейно разделима, то мы можем выбрать гиперплоскости таким образом, чтобы между ними не лежала ни одна точка обучающей выборки и затем максимизировать расстояние между гиперплоскостями. Ширину полосы между ними легко найти из соображений геометрии, она равна ![]() [1], таким образом наша задача минимизировать
[1], таким образом наша задача минимизировать ![]() . Чтобы исключить все точки из полосы, мы должны убедиться для всех i, что
. Чтобы исключить все точки из полосы, мы должны убедиться для всех i, что
![]()
Это может быть также записано в виде:
![]()
Проблема построения оптимальной разделяющей гиперплоскости сводится к минимизации ![]() , при указанном условии. Это задача квадратичной оптимизации, которая имеет вид:
, при указанном условии. Это задача квадратичной оптимизации, которая имеет вид:
![]()
По теореме Куна-Таккера эта задача эквивалентна двойственной задаче поиска седловой точки функции Лагранжа
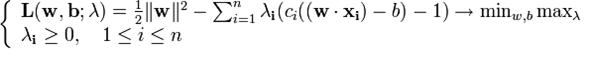
где ![]() — вектор двойственных переменных.
— вектор двойственных переменных.
Сведем эту задачу к эквивалентной задаче квадратичного программирования, содержащую только двойственные переменные:
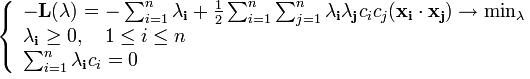
Допустим, мы решили данную задачу, тогда ![]() и
и ![]() можно найти по формулам:
можно найти по формулам:
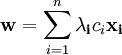
![]()
В итоге алгоритм классификации может быть записан в виде:
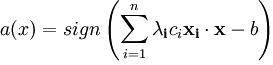
Обратим внимание, что суммирование идет не по всей выборке, а только по опорным векторам, для которых ![]() .
.
Для того, чтобы алгоритм мог работать в случае, если классы линейно неразделимы, позволим ему допускать ошибки на учебной коллекции. Введем набор дополнительных переменных ![]() , характеризующих величину ошибки на объектах
, характеризующих величину ошибки на объектах ![]() . Возьмем за отправную точку, смягчим ограничения неравенства, так же введем в минимизируемый функционал штраф за суммарную ошибку:
. Возьмем за отправную точку, смягчим ограничения неравенства, так же введем в минимизируемый функционал штраф за суммарную ошибку:
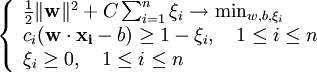
Коэффициент C — параметр настройки метода, который позволяет регулировать отношение между максимизацией ширины разделяющей полосы и минимизацией суммарной ошибки.
Аналогично, по теореме Куна-Таккера сводим задачу к поиску седловой точки функции Лагранжа:
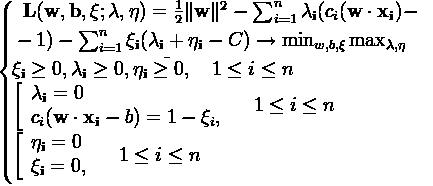
По аналогии сведем эту задачу к эквивалентной:
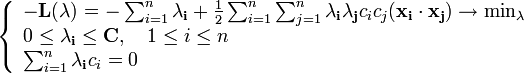
На практике для построения машины опорных векторов решают именно эту задачу, так как гарантировать линейную разделимость точек на два класса в общем случае не представляется возможным. Этот вариант алгоритма называют алгоритмом с мягким зазором (soft-margin SVM), тогда как в линейно разделимом случае говорят о жёстком зазоре (hard-margin SVM).
Для алгоритма классификации сохраняется формула (4), с той лишь разницей, что теперь ненулевыми ![]() обладают не только опорные объекты, но и объекты-нарушители. В определённом смысле это недостаток, поскольку нарушителями часто оказываются шумовые выбросы, и построенное на них решающее правило, по сути дела, опирается на шум.
обладают не только опорные объекты, но и объекты-нарушители. В определённом смысле это недостаток, поскольку нарушителями часто оказываются шумовые выбросы, и построенное на них решающее правило, по сути дела, опирается на шум.
Константу C обычно выбирают по критерию скользящего контроля. Это трудоёмкий способ, так как задачу приходится решать заново при каждом значении C.
Если есть основания полагать, что выборка почти линейно разделима, и лишь объекты-выбросы классифицируются неверно, то можно применить фильтрацию выбросов. Сначала задача решается при некотором C, и из выборки удаляется небольшая доля объектов, имеющих наибольшую величину ошибки ![]() . После этого задача решается заново по усечённой выборке. Возможно, придётся проделать несколько таких итераций, пока оставшиеся объекты не окажутся линейно разделимыми.
. После этого задача решается заново по усечённой выборке. Возможно, придётся проделать несколько таких итераций, пока оставшиеся объекты не окажутся линейно разделимыми.
Алгоритм построения оптимальной разделяющей гиперплоскости, предложенный в 1963 году Владимиром Вапником — алгоритм линейной классификации. Однако в 1992 году Бернхард Босер, Изабель Гуйон и Вапник предложили способ создания нелинейного классификатора, в основе которого лежит переход от скалярных произведений к произвольным ядрам, так называемый kernel trick (предложенный впервые М. А. Айзерманом, Э. М. Броверманом и Л. В. Розоноером для метода потенциальных функций), позволяющий строить нелинейные разделители. Результирующий алгоритм крайне похож на алгоритм линейной классификации, с той лишь разницей, что каждое скалярное произведение в приведённых выше формулах заменяется нелинейной функцией ядра (скалярным произведением в пространстве с большей размерностью). В этом пространстве уже может существовать оптимальная разделяющая гиперплоскость. Так как размерность получаемого пространства может быть больше размерности исходного, то преобразование, сопоставляющее скалярные произведения, будет нелинейным, а значит функция, соответствующая в исходном пространстве оптимальной разделяющей гиперплоскости, будет также нелинейной.
Стоит отметить, что если исходное пространство имеет достаточно высокую размерность, то можно надеяться, что в нём выборка окажется линейно разделимой.
Наиболее распространённые ядра:
Полиномиальное (однородное): ![]()
Полиномиальное (неоднородное): ![]()
Радиальная базисная функция: 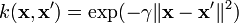 , для γ > 0
, для γ > 0
Радиальная базисная функция Гаусса: 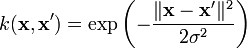
Сигмоид: ![]() , κ > 0 и c < 0
, κ > 0 и c < 0
С другой стороны в основе Метода опорных векторов лежит понятие плоскостей решений, определяющих границы принятия решения. Плоскость решения разделяет объекты с разной классовой принадлежностью. Ниже приведен схематичный пример, в котором участвуют объекты двух типов GREEN и RED. Разделяющая линия задает границу, справа от которой все объекты типа GREEN, а слева типа RED. Любой новый объект (белый кружок), попадающий направо, помечается (классифицирует) как объект класса GREEN (или помечается как объект класса RED, если он расположился по левую сторону от разделяющей прямой).
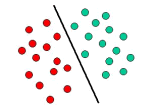
Рис. 3.4. Пример линейного классификатора
Выше приведен классический пример линейного классификатора, т. е. классификатора, который разделяет множество объектов на соответствующие группы (в нашем случае это GREEN и RED ) прямыми. Однако, большинство задач классификации не так просты, и часто необходимо строить оптимальные разбиения множеств объектов намного более сложной структуры. Другими словами, необходимо правильно классифицировать новые объекты (тестовые наблюдения) на основе имеющегося опыта (учебных наблюдений). В сравнении с предыдущим примером видно, что для полного отделения объектов типа GREEN от объектов типа RED потребуется кривая, т. е. более сложный разделитель, чем прямая. Методы решения классификационных задач, в которых дифференциация объектов с разной классовой принадлежностью осуществляется построением разделяющих прямых, называют гиперплоскостными классификаторами. Метод опорных векторов специально предназначен для решения такого типа задач.
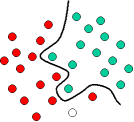
Рис. 3.5. Пример нелинейного классификатора
Нижеприведенная иллюстрация демонстрирует основную идею Метода опорных векторов. На ней представлены исходные объекты (в левой части схемы), которые далее преобразуются или, по-другому, переупорядочиваются при помощи специального класса математических функций, называемых ядрами. Этот процесс переупорядочивания называют еще преобразованием объектов (перегруппировкой). Отметим, что новый набор преобразованных объектов (в правой части схемы) уже линейно разделим. Таким образом, вместо построения сложной кривой (как показано в левой части схемы) требуется лишь провести оптимальную прямую, которая отделит объекты типа GREEN от объектов типа RED.
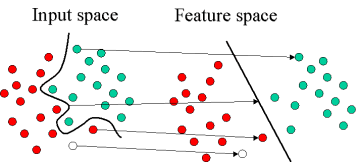
Рис. 3.6. Преобразование исходных объектов
STATISTICA Метод опорных векторов (МОВ) - метод первоначальной классификации, который решает задачу построением гиперплоскостей в многомерном пространстве, разделяющих группы наблюдений с разными классовыми метками. STATISTICA МОВ применяется как для регрессионных, так и для классификационных задач с несколькими непрерывными и категориальными переменными. Для категориальных переменных создается фиктивная двоичная переменная, принимающая значения 0 или 1. Таким образом, категориальная зависимая переменная, с тремя различными значениями (например, A, B,C), представляется набором фиктивных двоичных переменных:
A: {1 0 0}, B: {0 1 0}, C: {0 0 1}
Для построения оптимальных гиперплоскостей МОВ использует итеративный минимизирующий ошибку алгоритм обучения. По типу функции ошибки МОВ модели делятся на несколько групп:
Классификация МОВ Типа 1 (по - другому, С - МОВ классификация)
Классификация МОВ Типа 2 (по - другому, ню - МОВ классификация)
Регрессия МОВ Типа 1 (по - другому, эпсилон - МОВ регрессия)
Регрессия МОВ Типа 2 (по - другому, ню - МОВ регрессия)
Кратко опишем каждую группу моделей.
Классификация МОВ
Классификация МОВ Типа 1
Для этой группы МОВ обучение связано с минимизацией функции ошибки вида:
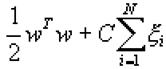
с ограничениями:![]()
где C - константа емкости, w - вектор коэффициентов, b - константа, и ![]() - параметры для обработки неразделимых наблюдений (входов), i индексирует N учебных наблюдений. Отметим, что
- параметры для обработки неразделимых наблюдений (входов), i индексирует N учебных наблюдений. Отметим, что ![]() - метка класса, x - независимая переменная. Ядро
- метка класса, x - независимая переменная. Ядро 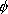 преобразует данные из входного (независимого) пространства в пространство признаков. Обратим внимание на то, что чем больше значение C, тем выше штраф ошибки.
преобразует данные из входного (независимого) пространства в пространство признаков. Обратим внимание на то, что чем больше значение C, тем выше штраф ошибки.
Классификация МОВ Типа 2
В отличие от модели Классификации МОВ Типа 1, в модели Классификации МОВ Типа 2 минимизируется функция ошибки:
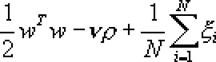
ограничения:
![]()
При построении регрессии МОВ оценивается функциональная зависимость переменной y от набора независимых переменных x. Как и во всех регрессионных задачах, здесь предполагается, что связь между зависимыми и независимыми переменными задается детерминированной функцией f и аддитивным шумом:
y = f(x) + noise
Задача состоит в том, чтобы найти функциональное представление для f, которое бы правильно предсказывало новые наблюдения. Цель достигается обучением МОВ модели на образцовой выборке (на учебных наблюдениях). Процесс обучения, как и в случае классификационных задач, связан с последовательной оптимизацией функции ошибки. В зависимости от вида функции ошибки различают две типа МОВ моделей:
Регрессия МОВ Типа 1
Для этого типа МОВ моделей функция ошибки имеет вид:
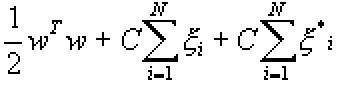
Функция минимизируется с условиями:
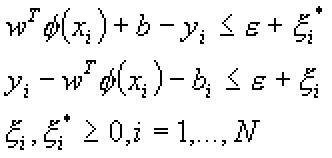
Регрессия МОВ Типа 2
Для этого типа МОВ моделей функция ошибки имеет вид:
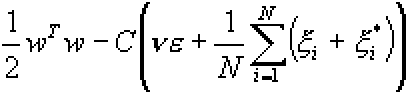
Функция минимизируется с условиями:
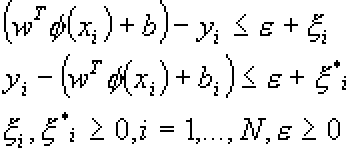
Ядро
STATISTICA МОВ для построения различных моделей методом опорных векторов использует набор из нескольких ядер. Он включает: линейное, полиномиальное ядро, радиальную базисную функцию (РБФ) и сигмоидное ядро:
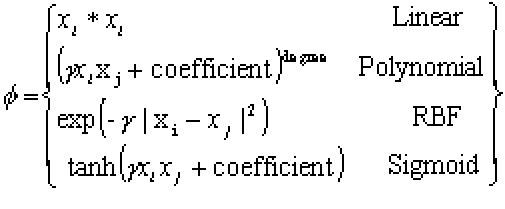
3.2. Классификация СППР
Существуют различные варианты классификации.
На уровне пользователя Haettenschwiler (1999) делит СППР на пассивные, активные и кооперативные СППР.
Пассивной СППР называется система, которая помогает процессу принятия решения, но не может вынести предложение, какое решение принять.
Активная СППР может сделать предложение, какое решение следует выбрать.
Кооперативная позволяет ЛПР изменять, пополнять или улучшать решения, предлагаемые системой, посылая затем эти изменения в систему для проверки. Система изменяет, пополняет или улучшает эти решения и посылает их опять пользователю. Процесс продолжается до получения согласованного решения.
На концептуальном уровне отличает СППР, управляемые сообщениями (Communication-Driven DSS), СППР, управляемые данными (Data-Driven DSS), СППР, управляемые документами (Document-Driven DSS), СППР, управляемые знаниями (Knowledge-Driven DSS) и СППР, управляемые моделями (Model-Driven DSS). СППР, управляемые моделями, характеризуются в основном доступ и манипуляции с математическими моделями (статистическими, финансовыми, оптимизационными, имитационными). Отдельные системы, позволяющие осуществлять сложный анализ данных, могут быть отнесены к гибридным СППР, которые обеспечивают моделирование, поиск и обработку данных.
Управляемая сообщениями (Communication-Driven DSS) (ранее групповая СППР — GDSS) СППР поддерживает группу пользователей, работающих над выполнением общей задачи.
СППР, управляемые данными (Data-Driven DSS) или СППР, ориентированные на работу с данными (Data-oriented DSS) (также известные как Business Intelligence) в основном ориентируются на доступ и манипуляции с данными. СППР, управляемые документами (Document-Driven DSS), управляют, осуществляют поиск и манипулируют неструктурированной информацией, заданной в различных форматах. Наконец, СППР, управляемые знаниями (Knowledge-Driven DSS) обеспечивают решение задач в виде фактов, правил, процедур.
На техническом уровне различает СППР всего предприятия и индивидуальные СППР. СППР всего предприятия подключена к большим хранилищам информации и обслуживает многих менеджеров предприятия. Настольная СППР — это малая система, обслуживающая лишь один компьютер пользователя. Существуют и другие классификации (Alter, Holsapple и Whinston, Golden, Hevner и Power).
В зависимости от данных, с которыми эти системы работают, СППР условно можно разделить на оперативные и стратегические. Оперативные СППР предназначены для немедленного реагирования на изменения текущей ситуации в управлении финансово-хозяйственными процессами компании. Стратегические СППР ориентированы на анализ значительных объемов разнородной информации, собираемых из различных источников. Важнейшей целью этих СППР является поиск наиболее рациональных вариантов с учетом влияния факторов, таких как конъюнктура целевых для компании рынков, изменения финансовых рынков и рынков капиталов, изменения в законодательстве и др. СППР первого типа получили название Информационных Систем Руководства (Executive Information Systems, ИСР). По сути, они представляют собой конечные наборы отчетов, построенные на основании данных из транзакционной информационной системы предприятия, в идеале адекватно отражающей в режиме реального времени основные аспекты производственной и финансовой деятельности. Для ИСР характерны следующие основные черты:
отчеты, как правило, базируются на стандартных для организации запросах; число последних относительно невелико;
ИСР представляет отчеты в максимально удобном виде, включающем, наряду с таблицами, деловую графику, мультимедийные возможности и т. п.;
как правило, ИСР ориентированы на конкретный вертикальный рынок, например финансы, маркетинг, управление ресурсами.
СППР второго типа предполагают достаточно глубокую проработку данных, специально преобразованных так, чтобы их было удобно использовать в ходе процесса принятия решений. Неотъемлемым компонентом СППР этого уровня являются правила принятия решений, которые на основе агрегированных данных дают возможность менеджерам компании обосновывать свои решения, использовать факторы устойчивого роста бизнеса компании и снижать риски. СППР второго типа в последнее время активно развиваются. Технологии этого типа строятся на принципах многомерного представления и анализа данных (OLAP).
В настоящее время СППР на основе Web-технологий для ряда компаний являются синонимами СППР предприятия.
Архитектура СППР представляется разными авторами по-разному.
Marakas (1999) предложил обобщенную архитектуру, состоящую из 5 различных частей: (a) система управления данными (the data management system — DBMS), (b) система управления моделями (the model management system — MBMS), (c) машина знаний (the knowledge engine (KE)), (d) интерфейс пользователя (the user interface) и (e) пользователи (the user(s)).
Аналоги систем принятия решений ищут и в биологических моделях. Но это трудно сделать по причине сверхвысокой сложности человеческого мозга.
В общей схеме принятия решений (рис. 3.7) преобладающей по трудовым затратам является операция преобразования пространства наблюдений с целью получения компактного описания ситуации.
Системы поддержки принятия решений – сложные динамические системы с элементами искусственного интеллекта. Эти системы могут включать и подготовленных специалистов, экспертов т. е. быть комплексными человеко-машинными системами. Сегодня они в основном специализированны.

Рис.3.7. Обобщенная схема принятия решений
В процессе разработки таких систем формируются описания физико-математических, химических, биологических, социальных моделей характеризующих объекты исследования.
Для формирования зон описаний ситуаций, характеристики и параметры которых носят случайный характер, используют методы математической статистики.
Наиболее часто - это определение законов распределения и их параметров по имеющимся выборкам.
По результатам наблюдений проявлений признаков в различных случаях, ситуаций формируется статистическая гипотеза о виде и параметрах закона распределения.
Классификация на основе анализа структуры альтернатив.
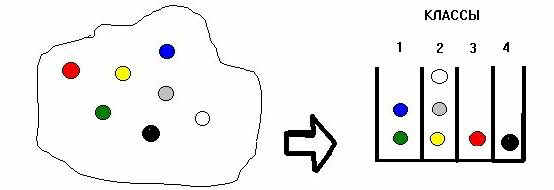
Рис.3.8. Классификация
Слева изображено неструктурированное множество альтернатив. Справа показано разбиение исходного множества на 4 класса. Можно считать, что каждый класс есть подмножество исходного множества альтернатив. Здесь важно отметить, что классы НЕУПОРЯДОЧЕНЫ друг относительно друга. Т. е. нельзя сказать, что какой-то класс "важнее (лучше, старше, дороже и п. т.)" другого. Например, людей можно классифицировать по полу или национальности. Правильная постановка диагноза - также пример классификации. Компьютерные системы, помогающие врачу ставить диагноз, существуют. И решают они именно задачу классификации, т. е. отнесения больного к нужному классу, который эквивалентен названию болезни. (А как же быть с легкими и тяжелыми заболеваниями? Ведь по определению классы НЕ упорядочены. Действительно, заболевания можно упорядочивать по тяжести, но здесь мы договоримся не принимать это в расчет.)
Второй способ структурирования называется СТРАТИФИКАЦИЯ. Это название произошло от английского термина "страта", (strata) что означает "слой", "пласт". Иными словами, стратификация есть разбиение множества на ряд уровней или слоев. В отличие от классов, страты упорядочены.
Серая и зеленая альтернативы помещены на верхнюю страту. Это означает, что они одинаковы по значимости (для ЛПР) и, одновременно, важнее (лучше) остальных альтернатив. В примере с обменом квартиры, если удалось стратифицировать варианты, то окончательный выбор, естественно, будет сделан среди вариантов, занимающих верхнюю страту. Удобно считать, что страты выражают некоторые уровни "качества". Несколько примеров классических стратификаций: Оценки уровня знаний; Уровни тренажеров.
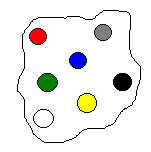


Рис.3.9. Стратификация
Связь страт с неким абстрактным "качеством" крайне важна для понимания идеи стратификации. Комплексный тренажер не просто лучше настольной игры, а можно говорить на сколько он лучше.
Следующий способ структурирования называется РАНЖИРОВАНИЕ. Внешне он напоминает стратификацию. Упорядочение называется ранжировкой, если указан только номер места объекта в упорядочении.
Места в ранжировке называются "рангами". Ранг 1 принято присваивать наилучшему объекту. (Вспомним "капитан 1-го ранга"). Итак, в отличие от стратификации, здесь играет роль только номер "полочки", на которую кладут альтернативы. Один и тот же ранг может быть присвоен нескольким объектам. Тогда ранжировка называется нестрогой.
Структура предполагает и ВЫБОР в том числе и между объектами одного класса. Методы структуризации отдельные исследователи относят к сердцевине процедуры поддержки принятия решений.
Методы разделим на критериальные и некритериальные. Иногда встречаются такие синонимы термина критерий, как "фактор", "показатель". Термин фактор чаще всего употребляют, когда говорят о влиянии. Например, "нужно учесть влияние этого фактора". Словом показатель чаще всего описывают разные стороны некоторого объекта. Например, говорят о "показателях деятельности предприятия". Термин критерий чаще всего применяют для описания ситуации выбора.
Критериальное структурирование основано на сопоставлении альтернатив по некоторому набору критериев. Что же такое некритериальные методы структурирования? Предположим у нас есть множество альтернатив. Будем выбирать из него пары, предъявлять их экспертам или ЛПР и просить их сравнить членов пары "в целом" (предполагается, что все альтернативы попарно сравнимы). В психологии и, затем, в кибернетике такое общее представление обозначают термином "гештальт" (ударение на букве "а"). Это - целостный образ объекта, лишенный какой бы то ни было детализации. Когда сравниваются качественные определения, не уточняя меру различия то это сравнение гештальтов.
Следующий по важности способ классификации методов структурирования связан с количеством ЛПР или экспертов, участвующих в процессе выбора. Говорят об индивидуальных, групповых решениях. Возникает и задача построения обобщенной (синонимы: интегральной, результирующей, компромиссной) ранжировки.
3.3. Некритериальное структурирование множества альтернатив
Возьмем две альтернативы А и Б. При их парном сравнении возможны только 3 варианта результата: А лучше Б (обозначим А > Б); А хуже Б (А < Б); А и Б равноценны (А = Б).
Если сравнить попарно все альтернативы исходного множества, то часто можно получить нестрогую ранжировку. Например, для множества {a, b,c, d,e} можно получить: c > d > a = e > b, или тот же результат с номерами рангов

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
