


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
N=2k, где к — число разрядов.
Процесс получения двоичной информации об объектах исследования называют кодированием информации. Кодирование информации перечислением всех возможных событий очень трудоемко. Поэтому на практике кодирование осуществляется более простым способом. Он основан на том, что один разряд последовательности двоичных цифр имеет уже вдвое больше различных значений – 00, 01, 10, 11, – чем одноразрядная последовательность (0 и 1).
2.5. Кодирование целых и действительных чисел
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит).
0= 0
0= 1
………………
1= 254
1= 255.
Шестнадцать бит позволяют закодировать целые числа от 0 до, а 24 бита – уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0, · 101
= 0,3 · 106
= 0, · 109.
Первая часть числа называется мантиссой, а вторая – характеристикой (порядком). Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
2.6. Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского алфавитов как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§».
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера. Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI – American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования: базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
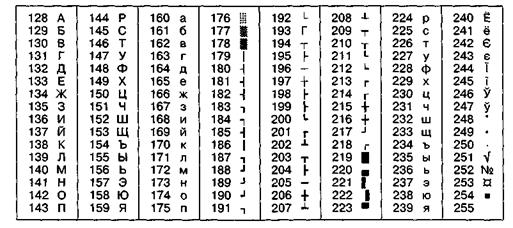
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица ASCII приведена в таблице 2.2.
Таблица 2.2
Базовая таблица кодирования ASCII
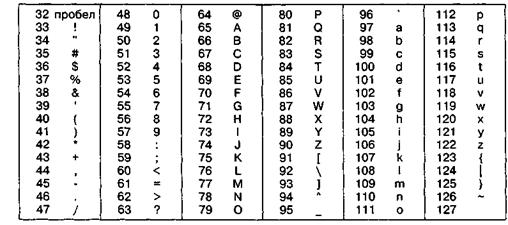
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» – компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 2.3). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows. Де-факто она стала стандартной в российском секторе World Wide Web.
Таблица 2.3
Кодировка Windows 1251
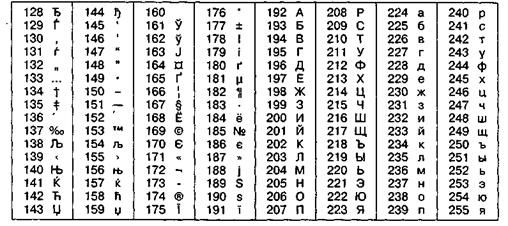
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) – ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 2.4). На базе этой кодировки ныне действуют кодировки КОИ8-Р (русская) и КОИ8-У (украинская). Сегодня кодировка КОИ8-Р имеет широкое распространение в компьютерных сетях на территории России и в некоторых службах российского сектора Интернета. В частности, в России она де-факто является стандартной в сообщениях электронной почты и телеконференций.
Таблица 2.4
Кодировка КОИ-8
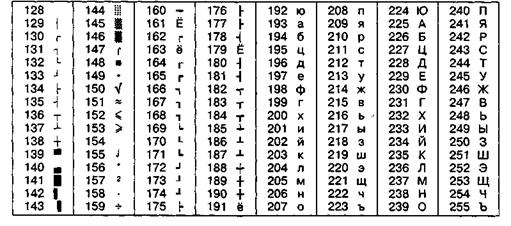
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки ISO (International Standard Organization – Международный институт стандартизации). На практике данная кодировка используется редко (таблица 2.5).
Таблица 2.5
Кодировка ISO
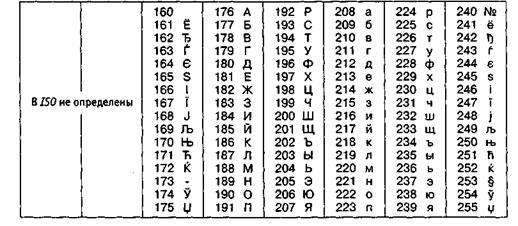
На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 2.6).
Таблица 2.6
ГОСТ-альтернативная кодировка
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных – это одна из распространенных задач информатики.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды дляразличных символов – этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
2.7. Кодирование графических данных
Существует два основных способа кодирования графической информации: растровый и векторный.
Растровый способ кодирования характеризуется тем, что все изображение по вертикали и горизонтали разбивается на достаточно мелкие прямоугольники – так называемые элементы изображения, или пиксели (от англ. pixel – picture element). Чем меньше прямоугольники, тем больше разрешение (resolution), т. е. тем более мелкие детали изображения можно закодировать. Этот параметр измеряется в dpi (dots per inch – точек на дюйм). В зависимости от того, на какое графическое разрешение экрана настроена операционная система компьютера, на экране могут размещаться изображения 640х480, 800х600, 1024х768 и более.
У растровых изображений два основных недостатка. Во-первых, очень большие объемы данных. Для активных работ с большеразмерными иллюстрациями типа журнальной полосы требуются компьютеры с большими размерами оперативной памяти (128 Мбайт и выше). Во-вторых, растровые изображения невозможно значительно увеличить без серьезных искажений. Эффект искажения при увеличении точек растра называется пикселизацией.
Для каждого пикселя хранится информация о его цвете и координатах. За цвет пикселя принимается некоторое усредненное значение цвета в прямоугольнике. Цвет пикселя кодируется определенным количеством битов. Глубина цвета (Color Depth) это - количество бит, приходящихся на один пиксель. В разных системах кодирования под цвет пикселя отводится от 1 до 24 бит. Нетрудно сообразить, что если под цвет отводится всего один бит, мы получим черно-белое изображение. При использовании 8 бит число возможных цветов достигает 256, 16 бит – 65 536 цветов, 24 бит – 16 777 216 цветов.
Способ разделения цвета на составляющие называется цветовой моделью. В настоящее время разработано множество цветовых моделей: RGB, CMYK, HSB, Lab и т. д., каждая из которых имеет свою область практического применения.
Рассмотрим более подробно RGB-модель, наиболее часто применяемую в компьютерной графике. При этом способе кодирования любой цвет представляется в виде комбинации трех цветов: красного (Red), зеленого (Green) и синего (Blue), взятых с разной интенсивностью. Интенсивность каждого цвета кодируется 8 битами. Таким образом, для каждого основного цвета существует 256 различных значений интенсивности.
Видимый человеком свет имеет длину волны в довольно узком диапазоне — от 0,38 мкм до 0,72 мкм. А человеческий глаз имеет специальные рецепторы (называемые колбочками), чувствительные именно к цвету. При этом каждая из колбочек «специализируется» уже на своем, совсем узком, диапазоне длин волн.
Природа распорядилась так, что в человеческом глазе оказались колбочки трех типов, чувствительные к цветам, которые мы называем красным, зеленым и синим. (Собаки, например, способны воспринимать цвета в диапазоне волн, начинающемся в светло-синем участке спектра и немного захватывающем невидимый человеку ультрафиолет. Поэтому долгое время считалось, что у собак восприятие цвета черно-белое.)
Количество различных цветов и количество бит, необходимых для их кодировки связаны между собой формулой:
N = 2I
Где N – количество цветов, I - число бит, отводимых в видеопамяти под каждый пиксель (глубина цвета).
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов или 28), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда (8 бит красного + 8 бит зеленого + 8 бит синего).
При этом система кодирования обеспечивает однозначное определение 16,5 млн. различных цветов (224), что близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называют полноцветным (True Color).
Графические файлы, в которых применяется цветовая система RGB, представляют каждый пиксель в виде цветового триплета – трех числовых величин (R, G, В), соответствующих интенсивностям красного, зеленого и синего цветов (рис. 1).
Конкретные цвета в RGB-модели получаются смешением основных цветов. Таким образом, для описания любого цвета достаточно 3 байт, которые часто записывают тремя парами 16-ричных чисел.
Так, например, белый цвет можно описать как FFFFFF, черный – желтый – FFFF00.
Метод получения нового оттенка суммированием яркостей составляющих компонент называется аддитивным. Он применяется всюду, где цвета изображения рассматриваются в проходящем цвете, т. е. на просвет: в мониторах, слайд-проекторах и т. п.
Кроме RGB, другими популярными системами кодирования цветных изображений являются CMY и HSB.
CMY (Cyan, Magenta, Yellow — голубой, пурпурный, желтый) — цветовая система, применяемая для получения цветных изображений на белой поверхности. Эта система используется в большинстве устройств вывода, таких как лазерные и струйные принтеры, Всегда для получения твердых копий краски наносятся на белую бумагу. При освещении каждый из трех основных цветов поглощают дополняющий его цвет; голубой цвет поглощает красный, пурпурный — зеленый, а желтый — синий. Например, если увеличить количество желтой краски, то интенсивность синего цвета в изображении уменьшится.
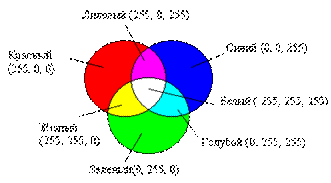
Рис. 2.3. Цветовая система RGB
Новые цвета в системе CMY получают вычитанием цветовых составляющих из белого цвета. Они имеют длину волны отраженного света, не поглощенного основными цветами CMY. Например, в результате поглощения голубого и пурпурного цветов образуется желтый, т. е. можно сказать, что желтый цвет является результатом «вычитания» из отраженного света голубой и пурпурной составляющих. Если все составляющие CMY будут вычтены (или поглощены), то результирующим цветом станет черный. На практике же получить идеальный черный цвет без дорогостоящих красителей в системе CMY весьма сложно.
Существует более практичный вариант CMY — система CMYK, в которой символ К означает черный цвет. Введение в эту цветовую систему черного цвета в качестве независимой основной цветовой переменной позволяет использовать недорогие красители. Систему CMYK часто называют четырехцветной, а результат ее применения — четырехцветной печатью. Во многих моделях точка, окрашенная в составной цвет, группируется из четырех точек, каждая из которых окрашена в один из основных цветов CMYK.
Данные в системе CMYK представляются либо цветовым триплетом, аналогичным RGB, либо четырьмя величинами. Если данные представлены цветовым триплетом, то отдельные цветовые величины противоположны величинам RGB. Так, для 24-битового пиксельного значения триплет (255,255,255) соответствует черному цвету, а триплет (0,0,0) — белому. Однако в большинстве случаев для представления цветов в системе CMYK используется последовательность четырех величин.
Как правило, четыре цветовые составляющие CMYK задаются в процентах в диапазоне от 0 до 100.
Модель HSB (Hue, Saturation, Brightness — оттенок, насыщенность, яркость цвета) — одна из многих цветовых систем, в которых при представлении новых цветов не смешивают основные цвета, а изменяют их свойства. Оттенок — это «цвет» в общеупотребительном смысле этого слова, например красный, оранжевый, синий и т. д. Насыщенность (также называемая цветностью) определяется количеством белого в оттенке. В полностью насыщенном (100%) оттенке не содержится белого, такой оттенок считается чистым. Частично насыщенный оттенок светлее по цвету. Красный оттенок с 50%-ной насыщенностью соответствует розовому. Яркость определяет интенсивность свечения цвета. Оттенок с высокой интенсивностью является очень ярким, а с низкой — темным.
Модель HSB напоминает принцип, используемый художниками для получения нужных цветов, — смешивание белой, черной и серой с чистыми красками для получения различных тонов и оттенков (tint, shade и tone). Оттенок tint является чистым, полностью насыщенным цветом, смешанным с белым, а оттенок shade — полностью насыщенным цветом, смешанным с черным. Тон (tone) — это полностью насыщенный цвет, к которому добавлены черный и белый цвета (серый). Если рассматривать систему HSB c точки зрения смеси этих цветов, то насыщенность будет представлять собой количество белого, яркость — количество черного, а оттенок — тот цвет, к которому добавляются белый и черный.
Режим, когда для кодирования цвета каждой точки используется 32 двоичных разряда, так же как и рассмотренный выше с использованием 24 разрядов; называют полноцветным (True Color). Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными чистками называют режимом High Color.
При векторном способе кодирования изображение представляется в виде комбинации простых геометрических фигур – точек, отрезков прямых и кривых (сплайнов), окружностей, прямоугольников и т. д.

Рис.2.4. Геометрические примитивы векторной графики
Для полного описания изображения необходимо знать вид и базовые координаты каждой фигуры. Например, для окружности такими координатами являются координаты центра и диаметр окружности, для сплайна – координаты точек, через которые проходит кривая. Кроме того, описываются цвета каждой фигуры, в том числе цвета границы и цвета внутренней области.
Векторное кодирование чрезвычайно широко распространено. В частности, оно используется в современных шрифтах TrueType и PostScript, в системах автоматизированного проектирования.
2.8. Кодирование звука
С начала 90-х годов персональные компьютеры получили возможность работать со звуковой информацией. Каждый компьютер, имеющий звуковую плату, микрофон и колонки, может записывать, сохранять и воспроизводить звуковую информацию.
Звук, с точки зрения акустики, представляет собой продольные волны сжатия и разрежения, свободно распространяющиеся в воздухе или какой-либо другой среде с непрерывно меняющейся амплитудой и частотой. Чем больше амплитуда, тем он громче для человека, чем больше частота сигнала, тем выше тон. Поэтому звуковое давление (звуковой сигнал) непрерывно изменяется во времени и пространстве, т. е. является аналоговым сигналом. Запись звука – это сохранение информации о колебаниях звукового давления во время записи. При этом аналоговый звуковой сигнал преобразуется в аналоговый же электрический сигнал при помощи микрофона той или иной конструкции и может быть записан на магнитной ленте в магнитофоне или на аудио компакт-диске (Audio-CD).
Но компьютер воспринимает, хранит и обрабатывает информацию в цифровом виде. Поэтому, чтобы передать аудиоинформацию в компьютер необходимо этот полученный электрический сигнал о звуке преобразовать в цифровую форму. Это преобразование осуществляется в так называемых аналого-цифровых преобразователях (АЦП). Вывод же звуковой информации из компьютера должен быть представлен в виде аналогового электрического сигнала, который затем должен в динамиках преобразовываться в звуковой сигнал для восприятия пользователем. Преобразование электрических цифровых сигналов, с которыми оперирует компьютер, в аналоговые электрические сигналы, требующиеся для подачи на вход динамика, осуществляется цифро-аналоговыми преобразователями (ЦАП).
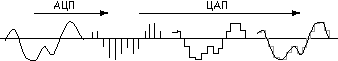
Рис.2.5. Преобразование электрических сигналов в цифровую форму и обратно
Для того, чтобы описать в цифровом виде аналоговый сигнал, являющейся функцией времени, необходимо определить (измерить, т. е. представить в цифровом виде) два параметра:
- моменты времени, в которые производились измерения сигнала;
- значения сигнала в данных точках измерения.
Определение первого параметра называется дискретизацией сигнала или выборкой отсчетов аналогового сигнала с заданной периодичностью. Периодичность отсчетов определяется частотой дискретизации. В свою очередь, частота дискретизации должна быть не менее удвоенной частоты наивысшей гармонической составляющей исходного звукового сигнала (в соответствии с теоремой Котельникова). Поскольку человек способен слышать звуки, частота которых находится в диапазоне от 16 Гц до 20 кГц, то максимальная частота дискретизации исходного звукового аналогового сигнала должна составлять не менее 40 кГц, т. е. отсчеты требуется проводить не менее 40.000 раз в секунду. Поэтому, в большинстве современных звуковых подсистем персональных компьютеров, максимальная частота дискретизации звукового сигнала составляет 44,1 или 48 кГц.
Одновременно с дискретизацией осуществляется так называемое квантование отсчетов по амплитуде (уровню), которое заключается в измерении мгновенных значений амплитуды в точках дискретизации и, следовательно, получении требуемого цифрового кода. При этом точность измерения зависит от количества разрядов кодового слова. Если значение амплитуды отсчета представлять 8-ми разрядным двоичным кодом, то можно закодировать и записать только градаций значения амплитуды. Если же значение амплитуды кодировать 16-ти разрядным двоичным кодом, то можно представить и закодировать 216 = 65.536 уровней отсчета, т. е. точность представления отсчета а, следовательно, и качество представления сигнала будет существенно выше.
Таким образом, звуковой процесс, подаваемый на вход звуковой системы компьютера, может быть полностью определен частотой его дискретизации по времени и множеством его значений по уровню, полученных в моменты снятия отсчетов. Моменты же времени снятия отсчетов полностью определяются начальным моментом получения отсчетов и расстоянием между отсчетами, т. е. периодом повторения отсчетов. Кодированные значения начала и периода повторения задаются обычно в виде 16-ти разрядных двоичных кодов электронными часами, управляемыми генератором тактовых импульсов (синхроимпульсов). Кодированные значения самих этих отсчетов в моменты их снятия получаются в цифровом виде с выхода АЦП.
Следовательно, чтобы запомнить в памяти компьютера в цифровом виде некоторый звуковой процесс, надо запомнить 16-ти разрядный код, представляющий период дискретизации по времени данного цифрового процесса, а также некоторый массив кодов, представляющий значения отсчетов (в большинстве случаев, также 16-ти разрядных).
Например, стереофонический звуковой сигнал длительностью 60 секунд, оцифрованный с частотой дискретизации 44,1 кГц, при 16-ти разрядном квантовании по уровню, для хранения потребует около 16 Мбайт. Этот объем может быть уменьшен путем компрессии (сжатия) данных по тем или иным алгоритмам (естественно с некоторыми потерями). Методы кодирования при сжатии позволяют сократить требуемый объем памяти до 20% от первоначального.
Цифро-аналоговое преобразование, т. е. преобразование цифровой информации, формируемой компьютером, в аналоговый электрический сигнал, подаваемый на динамики для преобразования в звуковые колебания воздуха, в общем случае происходит в два этапа. На первом этапе из потока цифровых данных с помощью ЦАП получают значения электрического сигнала, соответствующие их цифровым значениям в каждый момент времени дискретизации. В результате получают дискретный, ступенчато изменяющийся электрический сигнал. На втором этапе, из этого ступенчатого сигнала, путем сглаживания (интерполяции-фильтрации), формируется результирующий электрический аналоговый сигнал, который подается непосредственно на динамики. Сглаживание обычно осуществляется фильтром низкой частоты, который подавляет высшие периодические составляющие спектра дискретного сигнала.
8-ми разрядные АЦП и ЦАП обеспечивают качество звука, близкое к качеству звука в телефонной линии и в современных компьютерах не используются. Большинство мультимедийных компьютеров оснащено 16-разрядными АЦП и ЦАП, которые обеспечивают студийное качество звучания и относятся к классу Hi-Fi. А некоторые современные звуковые карты оснащаются 20 и даже 24-разрядными АЦП, что существенно повышает качество записи/воспроизведения звука.
Модульная единица 3. Математические и логические основы ЭВМ
3.1. Системы счисления и их разновидности
Система счисления – способ изображения чисел с помощью ограниченного набора символов, имеющих определенные количественные значения. Систему счисления образует совокупность правил и приемов представления чисел с помощью набора знаков (цифр).
Классификация систем счисления (СС) имеет следующий вид:
1) по анатомическому происхождению (десятичная, пятеричная, двенадцатеричная, двадцатеричная);
2) алфавитные (славянская, древнеармянская, древнегрузинская, древнегреческая);
3) исторические (унарная, вавилонская, римская);
4) машинные (двоичная, восьмеричная, десятичная, шестнадцатеричная).
Унарная СС. Унарная система – система счисления, в которой для записи чисел используется только один знак – I («палочка»). Следующее число получается из предыдущего добавлением новой I; их количество (сумма) равно самому числу.
Десятичная СС. Важнейшей среди СС считается десятичная система. Ее название связывают с числом пальцев на руках человека. В древности ее изображали так, чтобы значение каждой цифры соответствовало у нее числу углов. Современная форма написания цифр установилась в XVI веке. Исторически десятичная СС сложилась и развивалась в Индии. Европейцы заимствовали ее у арабов и назвали арабской, что исторически неверно. Возникновение и развитие десятичной СС наряду с появлением письменности является величайшим достижением человеческой мысли.
Среди других систем анатомического происхождения выделяют пятеричную, двенадцатеричную и двадцатеричную.
Пятеричная СС. Название связано со строением человеческой руки. Была распространена у африканских племен и в Китае.
Двенадцатеричная СС. Имела довольно широкое распространение. Название связано с числом фаланг на четырех пальцах руки. Элементы данной СС сохранились в Англии в системе мер (1 фут = 12 дюймам), в денежной системе (1 шиллинг = 12 пенсам), а также в быту (сервиз на 12 персон, комплект носовых платков – 12 штук).
Двадцатеричная СС. Основу для счета в данной системе составляли пальцы рук и ног. Была распространена у племен ацтеков и майя, у древних кельтов в Западной Европе. Следы этой СС сохранились в денежной системе Франции (1 франк = 20 су).
Алфавитные СС. Для записи в этой СС использовался буквенный алфавит. У русских в славянской СС роль цифр играли не все буквы, а только те, которые имеются в греческом алфавите. Над буквой, обозначающей цифру, ставился специальный знак – «титло». Была распространена у древних армян, грузин и греков.
Вавилонская (шестидесятеричная) СС. Существует две гипотезы о возникновении ее названия. Первая исходит из того, что произошло слияние двух племен, одно из которых пользовалось шестеричной СС, а другое – десятичной. Суть второй гипотезы в том, что древние вавилоняне считали продолжительность года равной 360 суткам, что связано с числом 60. система весьма сложная. Запись чисел в ней громоздка и неудобна.
Отголоски использования этой СС дошли до наших дней. Например, 1 час = 60 минут.
Римская СС. Эта система появилась в древнем Риме. Ее алфавит имеет следующий вид: I – 1, V – 5, X – 10, L – 50, С – 100, D – 500, M – 1000. Первые 12 натуральных чисел в римской СС записываются следующим образом: I, II, III, IV, V, VI, VII, VIII, IX, X, XI, XII.
В римской СС трудно выполнять арифметические операции. В настоящее время она используется в литературе (нумерация глав), при оформлении документов (серия паспорта), в декоративных целях (циферблат часов).
3.2. Позиционные и непозиционные системы счисления
Системы счисления принято делить на два класса: непозиционные и позиционные.
В непозиционных СС от положения (позиции) цифры в записи не зависит величина, которую она обозначает. Характерным примером такой системы счисления является римская СС.
Например, в римской СС число CCXXXII складывается из двух сотен, трех десятков и двух единиц и равно двумстам тридцати двум.
В римских числах цифры записываются слева направо в порядке убывания. В таком случае их значения складываются. Если же слева записана меньшая цифра, а справа – большая, то их значения вычитаются.
Например:
VI = 5 + 1 = 6, а IV = 5 – 1 = 4.
MCMXCVIII = 1000 + (-100 + 1000) + (-10 + 100) + 5 + 1 + 1 + 1 = 1998.
Такие системы счисления используются редко, т. к. не приспособлены для вычислений.
На практике наибольшее распространение получили позиционные системы счисления.
Позиционная система счисления – система счисления, в которой значение каждой цифры в изображении числа определяется ее положением (позицией) в ряду других цифр. В каждой позиционной системе счисления имеется основание. Любое число записывается в виде последовательности из цифр основания. Количество цифр основания равно самому основанию. Основание показывает, во сколько раз вес каждой цифры меньше веса цифры, стоящей в старшем соседнем разряде.
Некоторые позиционные системы счисления
Таблица 3.1
Основание | Система счисления | Знаки |
2 | Двоичная | 0,1 |
3 | Троичная | 0,1,2 |
4 | Четвертичная | 0,1,2,3 |
5 | Пятиричная | 0,1,2,3,4 |
8 | Восьмиричная | 0,1,2,3,4,5,6,7 |
10 | Десятиричная | 0,1,2,3,4,5,6,7,8,9 |
12 | Двенадцатиричная | 0,1,2,3,4,5,6,7,8,9,А, В |
16 | Шестнадцатиричная | 0,1,2,3,4,5,6,7,8,9,А, В,D, E,F |
Числа, которыми мы привыкли пользоваться, называются десятичными и арифметика, которой мы пользуемся, также называется десятичной. Называются они так потому, что каждое число можно составить из набора цифр содержащего 10 символов (цифр) –.
Возьмём, к примеру, число 246. Его запись означает, что в числе две сотни, четыре десятка и шесть единиц. Следовательно, можно записать следующее равенство:
246 = 200 + 40 + 6 = 2 * 102 + 4 * 101 + 6 * 100
Здесь знаками равенства отделены три способа записи одного и того же числа. Для нас наиболее интересна третья форма записи: 2 * 102 + 4 * 101 + 6 * 100 . Она построена следующим образом:
В нашем числе три цифры. Старшая цифра "2" имеет номер 3. Так вот она умножается на 10 во второй степени. Следующая цифра "4" имеет порядковый номер 2 и умножается на 10 в первой степени. Уже видно, что цифры умножаются на десять в степени на единицу меньше порядкового номера цифры.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
