Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Однако на практике гетероскедастичность не так уж и редка. Зачастую есть основания считать, что вероятностные распределения случайных отклонений ![]() при различных наблюдениях будут различными. Это не означает, что случайные отклонения обязательно будут большими при определенных наблюдениях и малыми – при других, но это означает, что априорная вероятность этого велика. Поэтому важно понимать суть этого явления и его последствия.
при различных наблюдениях будут различными. Это не означает, что случайные отклонения обязательно будут большими при определенных наблюдениях и малыми – при других, но это означает, что априорная вероятность этого велика. Поэтому важно понимать суть этого явления и его последствия.
На рис. 2.9 приведены два примера линейной регрессии–зависи-мости потребления С от дохода I:
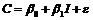 .
.
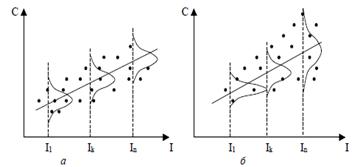
Рис. 2.9
В обоих случаях с ростом дохода растет среднее значение потребления. Но если на рис. 2.9, а дисперсия потребления остается одной и той же для различных уровней дохода, то на рис. 2.9,б при аналогичной зависимости среднего потребления от дохода дисперсия потребления не остается постоянной, а увеличивается с ростом дохода. Фактически это означает, что во втором случае субъекты с большим доходом в среднем потребляют больше, чем субъекты с меньшим доходом, и, кроме того, разброс в их потреблении более существенен для большего уровня дохода. Фактически люди с большими доходами имеют больший простор для распределения своего дохода. Реалистичность данной ситуации не вызывает сомнений. Разброс значений потребления вызывает разброс точек наблюдения относительно линии регрессии, что и определяет дисперсию случайных отклонений. Динамика изменения дисперсий (распределений) отклонений для данного примера проиллюстрирована на рис. 2.10. При гомоскедастичности (рис. 2.10, а) дисперсии ![]() постоянны, а при гетероскедастичности (рис. 2.10, б) дисперсии
постоянны, а при гетероскедастичности (рис. 2.10, б) дисперсии ![]() изменяются (в нашем примере – увеличиваются).
изменяются (в нашем примере – увеличиваются).
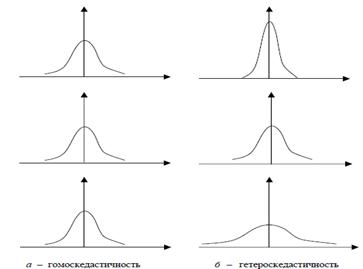
Рис. 2.10
Проблема гетероскедастичности в большей степени характерна для перекрестных данных и довольно редко встречается при рассмотрении временных рядов. Это можно объяснить следующим образом. При перекрестных данных учитываются экономические субъекты (потребители, домохозяйства, фирмы, отрасли, страны и т. п.), имеющие различные доходы, размеры, потребности и т. д. Но в этом случае возможны проблемы, связанные с эффектом масштаба. Во временных рядах обычно рассматриваются одни и те же показатели в различные моменты времени (например, ВНП, чистый экспорт, темпы инфляции и т. д. в определенном регионе за определенный период времени). Однако при увеличении (уменьшении) рассматриваемых показателей с течением времени может возникнуть проблема гетероскедастичности.
При гетероскедастичности последствия применения МНК будут следующими.
1. Оценки коэффициентов по-прежнему остаются несмещенными и линейными.
2. Оценки не будут эффективными (т. е. они не будут иметь наименьшую дисперсию по сравнению с другими оценками данного параметра). Они не будут даже асимптотически эффективными. Увеличение дисперсии оценок снижает вероятность получения максимально точных оценок.
3. Дисперсии оценок будут рассчитываться со смещением.
4. Вследствие вышесказанного все выводы, получаемые на основе соответствующих t- и F-статистик, а также интервальные оценки будут ненадежными. Следовательно, статистические выводы, получаемые при стандартных проверках качества оценок, могут быть ошибочными и приводить к неверным заключениям по построенной модели. Вполне вероятно, что стандартные ошибки коэффициентов будут занижены, а следовательно, t-статистики будут завышены. Это может привести к признанию статистически значимыми коэффициентов, которые таковыми на самом деле не являются.
Причину неэффективности оценок МНК при гетероскедастичности легко пояснить следующим примером парной регрессии (рис. 2.11).
Рис. 2.11
Из рис. 2.11 видно, что для каждого конкретного значения ![]() переменная Y принимает значение
переменная Y принимает значение ![]() из некоторого множества, имеющего свое распределение, отличное одно от другого в силу непостоянства дисперсий (сравните распределения для значений
из некоторого множества, имеющего свое распределение, отличное одно от другого в силу непостоянства дисперсий (сравните распределения для значений ![]() и
и ![]() ). По МНК минимизируется сумма квадратов отклонений
). По МНК минимизируется сумма квадратов отклонений 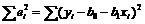 .
.
Но в этом случае каждое конкретное значение ![]() в данной сумме имеет одинаковый «вес» вне зависимости от того, получено оно из распределения с маленькой дисперсией (например,
в данной сумме имеет одинаковый «вес» вне зависимости от того, получено оно из распределения с маленькой дисперсией (например, ![]() ) или с большой (например,
) или с большой (например, ![]() ). Но это противоречит логике, так как точка, полученная из распределения с меньшей дисперсией, более точно определяет направление линии регрессии. Поэтому она должна иметь больший «вес», чем точка из распределения с большей дисперсией. Следовательно, методы оценивания, учитывающие «веса» точек наблюдений, позволяют получать более точные (эффективные) оценки.
). Но это противоречит логике, так как точка, полученная из распределения с меньшей дисперсией, более точно определяет направление линии регрессии. Поэтому она должна иметь больший «вес», чем точка из распределения с большей дисперсией. Следовательно, методы оценивания, учитывающие «веса» точек наблюдений, позволяют получать более точные (эффективные) оценки.
В ряде случаев на базе знаний характера данных появление проблемы гетероскедастичности можно предвидеть и попытаться устранить этот недостаток еще на этапе спецификации. Однако значительно чаще эту проблему приходится решать после построения уравнения регрессии.
Обнаружение гетероскедастичности в каждом конкретном случае является довольно сложной задачей, так как для знания дисперсий отклонений ![]() необходимо знать распределение Y, соответствующее выбранному значению
необходимо знать распределение Y, соответствующее выбранному значению ![]() . На практике зачастую для каждого конкретного значения
. На практике зачастую для каждого конкретного значения ![]() определяется единственное значение
определяется единственное значение ![]() , что не позволяет оценить дисперсию Y для данного
, что не позволяет оценить дисперсию Y для данного ![]() .
.
Естественно, не существует какого-либо однозначного метода определения гетероскедастичности. Однако к настоящему времени для такой проверки разработано довольно большое число тестов и критериев для них.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений ![]() от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями
от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями ![]() при i≠j) и, в частности, между соседними отклонениями
при i≠j) и, в частности, между соседними отклонениями 
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные данные). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов. При использовании перекрестных данных наличие автокорреляции (пространственной корреляции) крайне редко. В силу этого в дальнейших выкладках вместо символа i, обозначающего порядковый номер наблюдения, будем использовать символ t, отражающий момент наблюдения. Объем выборки при этом будем обозначать символом Т вместо n. В экономических задачах значительно чаще встречается так называемая положительная автокорреляция ![]() , нежели отрицательная автокорреляция
, нежели отрицательная автокорреляция![]() .
.
Чаще всего положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов. Суть автокорреляции поясним следующим примером. Пусть исследуется спрос Y на прохладительные напитки от дохода Х по ежемесячным данным. Трендовая зависимость, отражающая увеличение спроса с ростом дохода, может быть представлена линейной функцией ![]() , изображенной на рис. 2.12.
, изображенной на рис. 2.12.
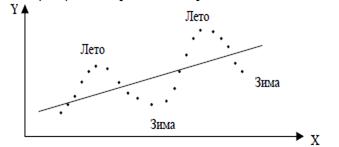
Рис. 2.12
Однако фактические точки наблюдений обычно будут превышать трендовую линию в летние периоды и будут ниже ее в зимние.
Аналогичная картина может иметь место в макроэкономическом анализе с учетом циклов деловой активности. Отрицательная автокорреляция фактически означает, что на положительном отклонении имеет место отрицательное и наоборот. Возможная схема рассеивания точек в этом случае представлена на рис. 2.13.
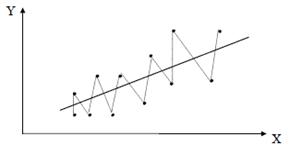
Рис. 2.13
Такая ситуация может иметь место, например, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима – лето).
Среди основных причин, вызывающих появление автокорреляции, можно выделить ошибки спецификации, инерцию в изменении экономических показателей, эффект паутины, сглаживание данных.
Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдений от линии регрессии, а также к автокорреляции.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
 Основные порталы (построено редакторами)
Основные порталы (построено редакторами)