


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Алгоритмы и структуры данных для морфологического машинного анализа текстов
ФГБОУ ВПО «Российский университет дружбы народов», *****@***ru
Работа посвящена проблеме морфологического анализа слов на русском языке, приведен краткий обзор существующих методов и описание конкретной модели.
Ключевые слова: машинный морфологический анализ, бор, префиксное дерево.
Введение
Задача автоматического анализа текстов на естественном языке актуальна во многих направлениях исследований, таких как поиск информации, машинный перевод, извлечение данных из текстов, аналитическая обработка, а так же локализация и интернационализация. Одним из основных этапов в анализе текстовой информации является морфологический анализ. Морфологический анализатор требуется в системах самого различного уровня и назначения.
Обзор методов морфологического анализа
Большинство современных морфологических анализаторов работают с грамматическим словарем [1]. Этот словарь позволяет для каждого слова, содержащегося в словаре, определить, изменяемо ли оно, и если это так, то каким образом оно может изменяться.
При точном морфологическом анализе при поиске словоформы слово в инверсионном порядке с конца сравнивается с деревом окончаний. Если окончание совпало, оставшаяся часть слова сопоставляется с деревом основ. При полном совпадении слова без окончания и основы сравниваются коды парадигм. Если есть одинаковые коды, то данная словоформа считается возможной и из вершины дерева извлекаются ее морфологические признаки. Поскольку возможно несколько вариантов разбора слова с разными окончаниями и основами, то поиск продолжается в дереве окончаний.
В том случае, если определить характеристики того или иного слова с помощью метода точной морфологии не удалось, но у слова можно выделить составные части (морфемы), прибегают к анализу на основе правил или «нечеткому» анализу. По наличию определенной морфемы (суффикс, приставка и т. д.) можно судить о том, какой частью речи является слово. Таким образом, можно построить систему правил, которая на основе наличия или отсутствия каких-либо частей слова, будет выдавать предположения о его морфологических характеристиках. [2]
В случаях морфологической омонимии применяется вероятностный подход. На определенном размеченном наборе документов, в которых для каждого слова известен его морфологический класс, вычисляются вероятности того, что некоторые слова некоторых классов стоят рядом (два слова, три слова и т. д.). На основе этих вероятностей в зависимости от контекста и строиться анализ слов. [3]
Модель морфологического машинного анализатора текста с использованием бора
В настоящей работе исследуется модель морфологического машинного текстового анализатора, работающего с префиксным деревом [4].
Словарь словоформ в этой модели для удобства загружен в структуру префиксное дерево или бор, в вершинах которого хранятся буквы слов. Слова получаются путем конкатенации символов, хранящихся в вершинах дерева. Для того, чтобы отличить промежуточные вершины от вершин, соответствующих ключам, каждой вершине добавляется булева характеристика.
Над деревом производятся три основные операции: поиск, добавление и удаление слова.
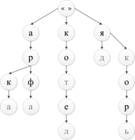
Рис. 1. Бор, содержащий слова арка, арфа, кот, котел, яд, як, якорь.
Поиск слова в дереве осуществляется просто. Будем спускаться последовательно от корня дерева, переходя к той вершине, в которой хранится символ, совпадающий с очередным символом ключа. Если такой вершины не нашлось или процесс закончился на той вершине, у которой нет метки конца слова, то данного ключа в дереве нет.
Алгоритм добавления слова в дерево почти аналогичен поиску. Начиная с корня дерева, будем последовательно переходить от одной вершины с совпавшим символом к другой. Если вершины с таким символом не обнаруживается, то создается новая вершина, в которую записывается следующий символ ключа, причем эта вершина становится потомком последней вершины с совпавшим символом.
Для того, чтобы удалить слово из дерева, находим вершину с последней буквой нужного нам слова и делаем эту вершину промежуточной. Если у этой вершины есть потомки, т. е. она не является листом, то на этом заканчиваем. Если же вершина – лист, то последовательно переходим от нее вверх от потомка к родителю, удаляя пройденные вершины, до тех пор, пока не придем в корень либо в вершину, которая не является промежуточной.
Выполнена программная реализация морфологического анализатора. Программа производит морфологический анализ слова путем его поиска в боре. Если слово в боре найдено, то выдаются его морфологические характеристики и его нормальная форма.
Выводы
В результате работы разработан и программно реализован морфологический текстовый анализатор, использующий словарный подход. Программа работает с грамматическим словарем , который хранится в структуре префиксное дерево. В будущем планируется дальнейшие доработка данной модели, ее расширение до синтаксического анализа.
Литература
1. Грамматический словарь русского языка: Словоизменение. / , 3-е изд. - М.: Рус. яз., 1987.
2. Семантические словари в автоматической обработке текста (по материалам системы ДИАЛИНГ) / http://www. aot. ru/docs/sokirko/sokirko-candid-1.html.
3. Manning C. Foundations of Statistical Language processing. / C. Manning, H. Schutze, The MIT Press, 1999.
4. Искусство программирования / Т.3, Вильямс, 2004.
Algorithms and data strucrtures for automatic morPHological analYsIs of texts
Shakurova J. R.
Russian People Friendship University, *****@***ru
This paper is dedicated to a problem of morphological analysis. I give a review of some methods and a description of my model.
Кеу words: morphological analysis of texts, text analysis, trie, prefix tree.
