
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
4.5.2. Файли з нещільним індексом чи індексно-послідовні файли
Нещільний індекс використовується у файлах, у яких записи в основній області зберігаються в упорядкованому виді. Записи в індексній області мають наступну структуру:
Значення ключа (згортки) першого запису блоку | Номер блоку, у якому зберігається запис |
В індексній області записи містять ключі (згортки) перших записів із блоків основної області.
На Рис. 4.8 показаний приклад заповнення індексної й основної області при нещільному індексі.
Індексна область Основна область
2030 |
2031 |
… |
Вільна область |
3500 |
3501 |
… |
Вільна область |
4200 |
4201 |
… |
Вільна область |
|
2030 |
|
3500 |
|
4200 |
|
… | … |
 1
1 2
2
| |
| |
Рис. 4.8. Приклад індексної й основної області при нещільному індексі
В індексній і основній областях записи упорядковані. Пошук запису виконується наступним чином. В індексній області за заданим значенням ключа виконується пошук номера блоку, у якому знаходиться потрібний запис. Тому що всі записи в основній області упорядковані, знайдений блок буде завжди містити шуканий запис. Потім виконується зчитування блоку в оперативну пам'ять і там уже відбувається пошук і обробка потрібного запису. Після цього блок перезаписується на колишнє місце.
Звичайно, сортування даних в основній області вимагає значних витрат часу. Але оскільки один раз відсортовані файли при їхньому створенні потім тільки підтримуються у відсортованому виді, накладні витрати в процесі додавання нової інформації будуть значно менше.
Оцінимо довжину доступу до довільного запису для файлу з нещільним індексом. Як і раніше будемо думати, що у файлі зберігаються 100000 записів. Раніше ми уже визначили, що для їхнього збереження в основній області потрібно 25000 блоків. Для посилань на таку кількість блоків досить в індексному запису відвести 2 байти. Тоді довжина індексного запису дорівнює:
LI = LK + 2 = 4 + 2 = 6 байт.
Кількість індексних записів в одному блоці буде дорівнювати:
KIZB = LB/LI = 1024/6 =170,6 » 171 запис.
Визначимо кількість індексних блоків, яка необхідна для збереження індексних записів:
KIB = KBO/KIZB = 25000/171 = 146,2 » 147 блоків.
Тепер визначимо довжину доступу при звертанні до довільного запису:
Тпошуку = Log2KIB + 1 = Log2147 + 1 » 8 + 1 = 9.
Отже, ми бачимо, що у випадку нещільного індексу час доступу скоротилося до 9 у порівнянні з 11 при щільному індексі.
Додавання нового запису у випадку нещільного індексу виробляється так. Спочатку шукається необхідний блок в основній області, у якому потрібно помістити новий запис. Знайдений блок основної області зчитується в оперативну пам'ять і там дописується в нього новий запис. Змінений блок потім зберігається на колишнім місці. При додаванні нового запису індексна область не корегується.
Тут так само задається відсоток розширення, але вже стосовно до основної області.
Видалення запису виробляється шляхом її фізичного видалення з основної області. Корегування індексної області при цьому так само не потрібно.
4.5.3. Організація індексів у виді В-дерев
Ідея побудови В-дерев проста і полягає в наступному. Спочатку будується нещільний індекс, як це було описано вище. Потім індексна область розглядається як основний файл і для нього ще будується нещільний індекс. Потім знову над новим індексом будується індекс наступного рівня і так доти, поки не виявиться, що індексна область складається з одного блоку. У результаті одержуємо деяке дерево, у якому кожен батьківський блок зв'язаний з однаковою кількістю підлеглих блоків, число яких дорівнює числу індексних записів, розміщених в одному блоці. Кількість звертань до диска для пошуку довільного запису при використанні такого багаторівневого індексу буде завжди однаково (для будь-якого запису) і дорівнювати кількості рівнів в отриманому дереві. Такі дерева називають збалансованими (від англ.. balanced), звідси назва В-дерево. На Рис. 5.3 зображена схема, що пояснює організацію індексу у виді В-дерева.
Побудуємо В-дерево для умов нашого приклада. На першому рівні число блоків дорівнює числу блоків основної області, тобто дорівнює 25000 блоків. Другий рівень утвориться як нещільний індекс над основною областю. Його ми вже будували, кількість блоків у ньому – 147. Тепер над цим другим рівнем знову побудуємо нещільний індекс.
Довжину індексного запису будемо вважати колишньою і рівною 6 байтам. Кількість індексних записів в одному блоці ми також уже визначали, вона дорівнює - 171 запис. Визначимо, скільки потрібно блоків, що необхідні для індексної області наступного 3-го рівня. Оскільки індексна область попереднього рівня містить 147 блоків, а в одному блоці можна розмістити посилання на 171 блок, то ясно, що на 3 рівні досить одного блоку.
Отже, ми одержали для розглянутого приклада дерево, що складається з 3 рівнів (Рис. 4.9). Це значить, що для доступу до довільного запису у випадку індексу у виді В-дерева буде необхідно лише 3 звертання до диска. Причому це не максимальна кількість звертань, а завжди та сама, однакова для доступу до будь-якого запису.
Нещільний Основна
 індекс область
індекс область
 |
![]()
 |  |
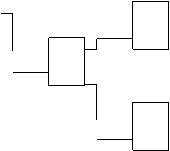 |
3 2 1
рівень рівень рівень
(1 блок) (147 блоків) (25000 блоків)
Рис. 4.9. Приклад організації індексу у вигляді В-дерева
Механізм додавання і видалення записів при організації індексу у виді В-дерева аналогічний розглянутому вище механізму для нещільного індексу.
4.6. Первинні і вторинні індекси
Для первинного ключа індекс створюється автоматично практично у всіх СУБД. Але при роботі з БД доводиться робити пошук по будь-якому полю, не тільки по первинному ключу. Тому у всіх СУБД передбачається можливість створення вторинних (чи користувальницьких) індексів, що можуть створюватися для не ключових полів. Оскільки створення кожного нового індексу завжди вимагає додаткових витрат дискової пам'яті, рекомендується вторинні індекси створювати тільки для тих полів, по яких передбачається найчастіше робити пошук даних.
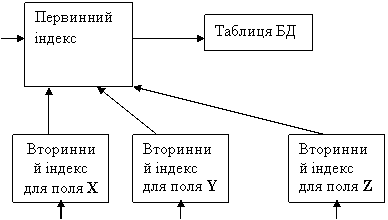
Створення вторинних індексів, як правило, засноване на використанні первинного індексу. В індексній області вторинного індексу містяться у відсортованому виді хеш-коди (згортки) значень індексованого поля з відповідними посиланнями на первинний індекс. При пошуку по вторинному індексі спочатку визначається відповідний потрібному запису первинний ключ, а потім через цей ключ і первинний індекс здійснюється доступ до потрібного запису в основній області файлу. На Рис. 5.4 приведена узагальнена схема, що пояснює механізм використання вторинних індексів.
 |
Пошук по
первинному
ключу
Пошук по Пошук по Пошук по
полю Х полю Y полю Z
Рис. 4.10. Схема використання вторинних індексів
У деяких СУБД, наприклад, у Access, розподіл індексів на первинні і вторинні не виконується. Вторинні індекси можуть знищуватися, чи змінюватися, створюватися заново.
Контрольні запитання
1. Для чого потрібна нормалізація відношень?
2. Загальні властивості нормальних форм.
3. Поясніть поняття функціонально-повної, часткової і транзитивної залежностей між атрибутами відношень. Наведіть приклади.
4. Вимоги до 1 НФ і 2 НФ.
5. Правило перетворення відношень в 2 НФ.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
