
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Двi останнi особливостi прямо випливають з орiєнтацiї технологiї OpenMP на роботу в обчислювальних системах зi спiльною пам’яттю. Це дозволяє органiзувати спiльний доступ до даних, оскiльки будь-який потiк виконується в тому ж самому адресному просторi та може звернутися до будь-якої адреси безпосередньо. При органiзацiї копiювання даних заданим чином для кожного потоку, вважається, що швидкiсть копiювання даних в адресному просторi та швидкiсть доступу до будь-якої адреси з кожного потоку, що виконується паралельно, однакова. Хоча технологiя i може бути застосована в системах з неоднорiдним доступом до пам’ятi (так званих NUMA-системах), органiзацiя копiювання та доступу до даних не враховує особливостi обчислювальної системи.
Технологiя OpenMP розрахована для використання на обчислювальних системах зi спiльною пам’яттю, її внутрiшня пiдсистема керування ресурсами використовує пiдхiд роздiлення робiт (або викрадення робiт, англ. work-stealing), єдину чергу готових до виконання пiдзадач основної задачi, та має ряд оптимiзованих режимiв роботи, якi використовують особливостi систем зi спiльною пам’яттю. [74] Вона дозволяє користувачу такої системи забезпечити паралельне обчислення його задачi шляхом анотування вихiдних кодiв вiдповiдної програми, при чому не вимагає значної їх модифiкацiї. Завдяки цьому, дана технологiя використовується для швидкого розпаралелювання iснуючих обсягiв вихiдних кодiв, зокрема математичних та обчислювальних бiблiотек. Однак, ця технологiя може бути застосована лише в системах зi спiльною пам’яттю. Хоча це й дозволяє працювати на обчислювальних системах з неоднорiдним доступом до пам’ятi, що мають спiльний адресний простiр, однак перешкоджає її використанню в системах з локальною пам’яттю або розподiлених системах, якi, на даний час, вважаються найбiльш продуктивними для виконання обчислень.
Щоб розв’язати проблему застосування технологiї розпаралелювання, заснованої на вказiвках компiлятору, в обчислювальних системах з локальною пам’яттю було запропоновано наступних два пiдходи.
Перший з них полягає у використаннi низькорiвневого iнтерфейсу передачi повiдомлень для органiзацiї доступу до даних у вiдповiдностi до способу органiзацiї, вказаного у вiдповiдних вказiвках компiлятору. [75] Такий спосiб передбачає, насамперед, забезпечення перетворень вихiдного коду з використанням вказiвок OpenMP у вихiдний код з використанням iнтерфейсу передачi повiдомлень MPI, що вимагає значної пiдтримки з боку транслятора вiдповiдної мови програмування. За вiдсутностi вказiвки про заборону доступу за замовчуванням, необхiдно забезпечити копiювання всiх даних у локальну пам’ять кожного вузла. Оскiльки у великiй кiлькостi задач, розв’язання яких виконується паралельно, кожний паралельно виконуваний потiк звертається лише до частини даних, такий пiдхiд може призвести до копiювання непотрiбних даних та внести додатковi затримки в процес обчислення через необхiднiсть забезпечення їх несуперечливостi. Оскiльки OpenMP не допускає змiни змiсту виконуваних операцiй, необхiдно забезпечувати найбiльш строгий рiвень несуперечливостi – послiдовну несуперечливiсть. При цьому значно зростають накладнi витрати на органiзацiю взаємодiї мiж потоками та очiкування передачi даних, що знижує ефективнiсть системи в цiлому. [11] Незважаючи на те, що даний пiдхiд дозволяє застосовувати технологiї розпаралелювання з використанням директив компiлятора, зокрема OpenMP, для програмування систем з локальною пам’яттю, вiн також не враховує гетерогеннiсть таких систем, оскiльки використовує блокуючi колективнi операцiї iнтерфейсу передачi повiдомлень, якi виконуються стiльки часу, скiльки необхiдно для передачi даних найбiльш повiльним каналом, пiд час чого ряд обчислювальних вузлiв може простоювати.
Другий пiдхiд, на вiдмiну вiд першого, не виконує перетворень на рiвнi вихiдних кодiв, а використовує розширення трансляторiв мов С та С++ для спецiалiзовану реалiзацiю бiблiотеки часу виконання для iнтерфейсу передачi повiдомлень. [76,77] Цей пiдхiд реалiзовано у наборi програмного забезпечення для кластерних систем компанiї Intel. Його особливiстю є орiєнтацiя на гомогеннi кластернi обчислювальнi системи, що складається з однакових обчислювальних вузлiв та однаковими симетричними каналами мережевого зв’язку мiж ними. Цей пiдхiд використовує розширення транслятора для виконання аналiзу доступу до певної частини даних, та може органiзовувати передачу в локальну пам’ять вузла лише тих даних, звернення до яких необхiдне в потоках, що виконується на цьому вузлi, таким чином зменшуючи обсяги даних, що мають бути переданi, i час, необхiдний для їх передачi. Такий аналiз, однак, не завжди повнiстю можливий, наприклад пiд час застосування арифметики покажчикiв неможливо точно визначити частину даних, яку необхiдно передати, пiд час трансляцiї, тому певна частина переданих даних може в результатi залишитися невикористаною. Разом з тим, потенцiйна неоднорiднiсть вузлiв та зв’язкiв мiж ними також не береться до уваги в реалiзацiї даного пiдходу.
Таким чином, технологiя розпаралелювання з використанням директив компiлятора була розширена для можливостi її застосування в системах з локальною пам’яттю, однак iснуючi пiдходи не враховують потенцiйну гетерогеннiсть цiльової системи. З iншого боку, детальний аналiз на можливiсть зменшення обсягiв даних, що передаються мiж обчислювальними вузлами системи з локальною пам’яттю, неможливий для певного ряду задач, що у загальному випадку унеможливлює використання бiльшого обсягу пам’ятi, анiж наявний в одному обчислювальному вузлi. Однак розподiлення всього обсягу даних мiж обчислювальними вузлами є однiєю з переваг систем з локальною пам’яттю [10], яка не може бути досягнута при використаннi даної технологiї.
1.14. Низькорiвневий iнтерфейс передачi повідомлень
Для органiзацiї доступу до даних, якi необхiднi для виконання певних обчислень, а також для передачi результатiв обчислень потокам, якi виконують їх подальшу обробку або виведення, в обчислювальних системах з локальною пам’яттю застосовують модель програмування, що базується на передачi повiдомлень мiж вузлами обчислювальної системи. Така модель програмування включає декiлька процесiв, що виконуються в рiзних адресних просторах та не мають безпосереднього доступу до даних, збережених iншими процесами, що дозволяє виконувати такi процеси на обчислювальних вузлах, що мають фiзично рiзну пам’ять, а також i в обчислювальних системах зi спiльною пам’яттю з використанням програмного контролю незалежностi адресних просторiв з боку операцiйної системи. [78]
Модель програмування, що базується на передачi повiдомлень, була розширена таким чином, щоб врахувати сучаснi гiбриднi обчислювальнi системи, якi включають в себе обчислювальнi вузли з локальною пам’яттю, зв’язанi мережею, кожен з яких є багатопроцесорним та використовує спiльну для всiх процесорiв в рамках одного вузла пам’ять. Таким чином, реалiзацiї даної моделi програмування можуть використовувати взаємодiю, що базується на спiльних даних, при роботi в рамках одного обчислювального вузла та не виконувати передачу даних та управляючої iнформацiї, зменшуючи подiбним образом затримки, що виникають пiд час передачi даних.
Найбiльш поширеною реалiзацiєю моделi програмування, що базується на передачi повiдомлень, є низькорiвневий iнтерфейс передачi повiдомлень MPI [79]. Цей iнтерфейс специфiкує набiр функцiй, якi можуть бути використанi для надiйної передачi абстрактних повiдомлень, що мiстять данi, мiж вузлами обчислювальної системи, що не мають спiльної пам’ятi, та передбачає наявнiсть бiблiотеки часу виконання, яка вiдповiдає за безпосередню передачу даних мiж вузлами з використанням засобiв операцiйної системи. Цей iнтерфейс є низькорiвневим, оскiльки вимагає вiд користувача оперувати в рамках абстракцiй повiдомлення та самостiйно визначати набiр даних, який має бути переданий в кожний з процесiв, а також розташування процесу, в якому мiстяться вихiднi данi.
В iнтерфейсi передачi повiдомлень визначено наступнi види органiзацiї передачi даних мiж процесами, що виконуються паралельно:
– блокуюча передача даних з одного процесу в iнший;
– неблокуюча передача даних з одного процесу в iнший;
– буферизована передача даних з одного процесу в iнший;
– буферизований обмiн даними мiж парою процесiв;
– блокуюча колективна передача даних вiд одного процесу до всiх;
– блокуюча колективна передача даних вiд всiх процесiв до одного;
– блокуюча колективна передача даних мiж всiма процесами попарно.
В цiй класифiкацiї видiляють наступнi особливостi. Блокуючi передачi, звiдки походить їх назва, блокують подальше виконання процесiв, якi приймають участь в цiй передачi, до того часу що данi будуть остаточно переданi процесу-приймачу та можуть бути безпечно використанi. Неблокуючi передачi дозволяють iнiцiювати передачу даних одночасно з продовженням виконання обчислень в процесi, що iнiцiював таку передачу, використовуючи концепцiю мультипрограмування. Для перевiрки чи були данi дiйсно переданi та чи можна їх використовувати застосовуються спецiальнi елементи iнтерфейсу передачi повiдомлень MPI. Неблокуюче вiдправлення може бути зв’язано з блокуючим прийманням та навпаки. Перша комбiнацiя є найбiльш поширеною, оскiльки як правило процес-джерело не змiнює тi даних, якi вiдправляються. З iншого боку, неблокуюче приймання дозволяють органiзувати довiльний порядок повiдомлень за умови наявностi очiкування, на вiдмiну вiд блокуючих, де порядок отримання строго визначений та вiдповiдає порядковi звернення до вiдповiдних елементiв iнтерфейсу передачi повiдомлень. Останнє може призвести до небажаного очiкування певних даних.
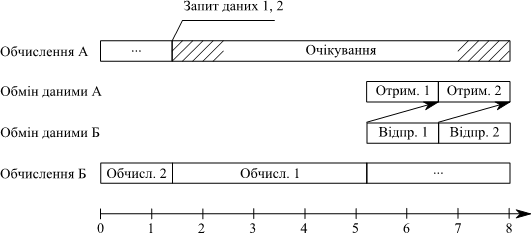
Наприклад, в системi виконуються два процеси А та Б. Процесу А необхiдно виконати розрахунки над даними 1 та 2, що мають бути обчисленi в процесi Б. Данi 2 вже обчисленi на момент запиту. За умови строгого порядку передач зумовленого використанням блокуючих операцiй (рис. 1.8) час очiкування даних в процесi А бiльший анiж за використання неблокуючих передач (рис. 1.9), якi дозволяють визначити довiльний порядок отримання даних за умови наявностi мультипрограмування, що вiрно для бiльшостi сучасних обчислювальних систем.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
