
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
На рисунках використовуються наступні умовні позначення:
– прямокутник – виконання деякого оператору;
– (S) – виконання операторів поділу gsplit та split;
– (C) – виконання оператору обчислення compute;
– (M) – виконання оператору об’єднання merge;
– еліпс – дані:
– (R) – проміжок вхідних даних;
– (V) – частковий результат;
– кожній вершині присвоєна мітка виду .i. j.k ..., яка відповідає шляху поділу.
2.10.2. Поділ на підзадачі однакового порядку
Поділ на підзадачі однакового порядку характеризується параметром – числом k, яке показує, на скільки збільшується порядок підзадач. Цей параметр можна виразити через необхідну кількість під задач 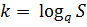 , де S – необхідна кількість підзадач, а q – кількість підзадач, на яку виконується поділ оператором поділу за один крок.
, де S – необхідна кількість підзадач, а q – кількість підзадач, на яку виконується поділ оператором поділу за один крок.
В роботі досліджується два способи вибору кількості підзадач:
– Поділ на підзадачі найбільшого розміру. Такий поділ досягається за рахунок поділу на мінімальне число підзадач S, таке, що ![]() , де N кількість ядер, які доступні задачі паралельній обчислювальній системі.
, де N кількість ядер, які доступні задачі паралельній обчислювальній системі.
В ідеальному випадку S = N і кожне ядро отримає тільки одну підзадачу. Приклад такого поділу для S = N = 8 зображено на рис. 2.8.
Гіпотеза 1. Поділ на підзадачі найбільшого розміру мінімізує кількість пересилок даних між ядрами, і тому мінімізує загальний час пересилок даних 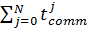 відповідно до умов оптимізації (2.6), що призведе до підвищення значень коефіцієнту ефективності.
відповідно до умов оптимізації (2.6), що призведе до підвищення значень коефіцієнту ефективності.
Тим не менше, у випадку неможливості поділу на необхідну кількість підзадач (тобто, якщо 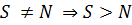 ), відповідно до принципу Діріхле відсутня можливість розподілити рівно по одній підзадачі на кожне ядро на наступних кроках. Тому при застосуванні такого способу можлива велика незбалансованість навантаження у випадку S ≠ N, що може значно знизити коефіцієнти прискорення КП та ефективності КЕ, за рахунок збільшення часу очікування в кінці обчислень tw, fin.
), відповідно до принципу Діріхле відсутня можливість розподілити рівно по одній підзадачі на кожне ядро на наступних кроках. Тому при застосуванні такого способу можлива велика незбалансованість навантаження у випадку S ≠ N, що може значно знизити коефіцієнти прискорення КП та ефективності КЕ, за рахунок збільшення часу очікування в кінці обчислень tw, fin.
– Поділ на підзадачі середнього розміру. Під цим ми розуміємо поділ на 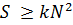 підзадач, де N – кількість ядер, які доступні задачі в паралельній обчислювальній системі, а k – коефіцієнт, який визначає розмір зерна паралелізму та впливає на кількість кроків основного циклу обчислень (один з наступних етапів). Для паралельних обчислювальних систем з невеликою кількістю ядер доцільно встановлювати
підзадач, де N – кількість ядер, які доступні задачі в паралельній обчислювальній системі, а k – коефіцієнт, який визначає розмір зерна паралелізму та впливає на кількість кроків основного циклу обчислень (один з наступних етапів). Для паралельних обчислювальних систем з невеликою кількістю ядер доцільно встановлювати ![]() для отримання більшої кількості підзадач; для паралельних систем з великою кількістю ядер зростання квадратичного множника звичайно є достатнім для поділу на достатню кількість підзадач, і тому
для отримання більшої кількості підзадач; для паралельних систем з великою кількістю ядер зростання квадратичного множника звичайно є достатнім для поділу на достатню кількість підзадач, і тому ![]() .
.
Цей спосіб має дві переваги над попереднім (поділ на підзадачі найбільшого розміру). По-перше, зазвичай підзадача, менша за обсягом обчислень, потребує меншої кількості вхідних даних; це дозволяє швидше передати менші підзадачі на інші ядра та почати обчислення раніше, тим самим мінімізуючи час очікування вхідних даних tw, in. По-друге, це створює передумови для забезпечення кращої збалансованості навантаження на наступних етапах. За умови прийняття найкращих рішень щодо балансування навантаження, в найгіршому випадку поділу незбалансованість навантаження не перевищить вдвічі час обчислення найбільшої підзадачі плюс час пересилки вхідних даних: це забезпечується вибором квадратичної залежності кількості задач від кількості процесорів.
Покажемо, що незбалансованість навантаження дійсно визначається найбільшою підзадачею. Після попереднього поділу та початкової розсилки кожне ядро буде мати N підзадач. Кожне ядро має можливість почати викопувати одну задачу, а всі інші N–1 підзадачі можуть бути рівномірно перерозподілені між іншими ядрами. Звичайно, першою може бути обрана для виконання не найбільша підзадача, але після виконання перебалансування N–1 підзадачі по іншим ядрам, деяке ядро почне виконувати найбільшу підзадачу.
| Рис. 2.8. Приклад поділу задачі на підзадачі третього порядку |
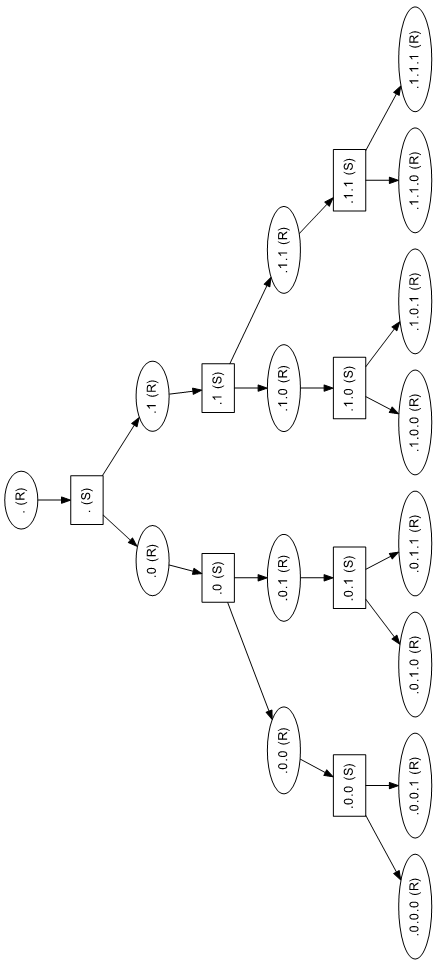
2.10.3. Поділ на підзадачі різного порядку
Спосіб поділу на підзадачі однакового порядку в деяких випадках може не дати досягти найбільших коефіцієнтів прискорення КП та ефективності КЕ. А саме, проблеми можуть виникати для паралельних реалізацій алгоритмів з регулярним паралелізмом, де для кожного елементу даних виконується однакова кількість операцій. Для такого випадку можна побудувати спосіб попереднього поділу, який гарантовано забезпечує найменшу незбалансованість навантаження, але в той же час не потребує точних апріорних даних про час виконання.
Поділ на підзадачі різного порядку проводиться наступним чином. Спочатку проводиться поділ підзадачі задачі нульового Т0 на мінімальне число підзадач ![]() , таке, що
, таке, що  , де N – кількість ядер, які доступні задачі в паралельній обчислювальній системі. В результаті отримаємо множину підзадач k-го порядку:
, де N – кількість ядер, які доступні задачі в паралельній обчислювальній системі. В результаті отримаємо множину підзадач k-го порядку:
![]()
З множини ![]() слід виключити N будь-яких підзадач (це навантаження сбалансовано), в результаті отримаємо множину
слід виключити N будь-яких підзадач (це навантаження сбалансовано), в результаті отримаємо множину ![]() . Підзадачі множини
. Підзадачі множини ![]() розбивають аналогічно на
розбивають аналогічно на ![]() підзадач, так що
підзадач, так що 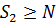 :
:
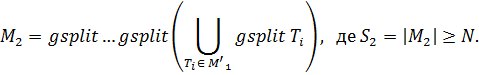
Даний процес повторюють доти, доки поділ на Si ≥ N можливий (поділ стає неможливим при отриманні неподільних задач), або доки не отримано 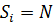 i в цьому випадку навантаження сбалансоване вже на i-му кроці. Приклад поділу на підзадачі різного порядку для
i в цьому випадку навантаження сбалансоване вже на i-му кроці. Приклад поділу на підзадачі різного порядку для 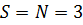 зображено на рис. 2.9.
зображено на рис. 2.9.
Виключення з розглянення N підздач однакового порядку на кожному кроці створює передумови для рівномірного розподілу навантаження на наступних кроках. Для паралельних реалізацій алгоритмів з регулярним паралелізмом, де для кожного елементу даних виконується однакова кількість операцій, нерівномірність в найгіршому випадку складе одну неподільну підзадачу, тому що всі під задачі нижчих порядків були згруповані по N та виключені з розгляду на попередніх кроках.
Рис. 2.9. Приклад поділу задачі на підзадачі різного порядку
Після попереднього поділу виконується початкова розсилка підзадач по обчислювальних ядрам. В результаті цього формується деякий початковий розподіл підзадач, який буде скоректовано в результаті динамічного балансування навантаження за рахунок перерозподілу підзадач. Так як апріорна оцінка часу виконання паралельних реалізацій алгоритмів з нерегулярним паралелізмом є складною задачею, яку в динаміці виконувати зазвичай недоцільно, то на даному етапі можна використовувати тільки найпростіші евристики.
Гіпотеза 2. Для задач, де для кожного елементу даних виконується однакова кількість операцій, найменша незбалансованість навантаження призведе до мінімізації часу очікування вхідних даних tw, in, а значить, і до збільшення коефіцієнтів прискорення КП та ефективності КЕ. Отже, поділ на підзадачі різного порядку для таких задач призведе до найбільших значень цих коефіцієнтів.
2.11. Способи початкової розсилки підзадач
2.11.1. Загальні зауваження
Пропонується три способи початкової розсилки:
– відсутність початкової розсилки, всі підзадачі після попереднього поділу залишаються на першому вузлі;
Гіпотеза 3. Початкова розсилка дублює функції динамічного балансування навантаження і тому не потрібна як окремий етап.
– початкова розсилка для підзадач однакового порядку – використовується якщо попередній поділ був виконаний на підзадачі однакового порядку;
– початкова розсилка для підзадач різного порядку – використовується якщо попередній поділ був виконаний на підзадачі різного порядку.
2.11.2. Розсилка підзадач однакового порядку
Вхідними даними для даного етапу є множина підзадач:
![]()
де ![]() – порядок підзадач,
– порядок підзадач, 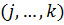 – відповідні шляхи поділу,
– відповідні шляхи поділу, ![]() – потужність множини результатів оператору gsplit.
– потужність множини результатів оператору gsplit.
Необхідно розбити множину M на множини Р0, Р1,..., PN-1 де N – кількість ядер, які доступні задачі в паралельній обчислювальній системі, так, щоб за можливістю мінімізувати незбалансованість початкового розподілу підзадач.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
