
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис. 4.18. Залежнiсть KЕ від кулькості процесорів при балансуванні навантаження з перерозподілом між усіма процесами та додатковим поділом для задачі А.
В результатi аналiзу отриманих даних виявлено наступне:
• Для задачi А пiдхiд без додаткового подiлу показав найкращi результати. Це очiкуваний результат для задачi А, тому що попереднiй подiл на пiдзадачi рiзного порядку є близьким до оптимального, а будь-який додатковий подiл є надмiрним та тiльки призводить до додаткових накладних витрат, в тому числi, на об’єднання результатiв.
• Для задачi А попереднiй подiл на пiдзадачi середнього розмiру показав гiршi результати нiж iншi пiдходи, як i очiкувалось.
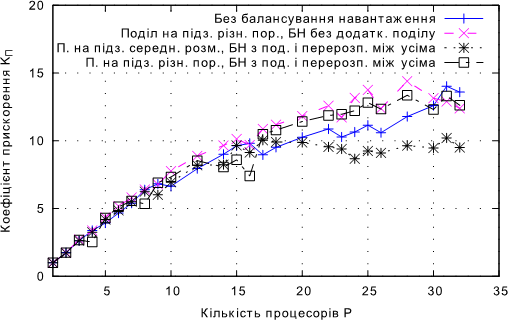
Рис. 4.19. Залежнiсть KП від кулькості процесорів при балансуванні навантаження з перерозподілом між усіма процесами та додатковим поділом для задачі А.
• Для задачi Б балансування навантаження з перерозподiлом мiж усiма процесами та додатковим подiлом є не гiршим за пiдходи без додаткового подiлу для менше, нiж 15 процесорiв, а для бiльшої кiлькостi процесорiв – демонструє пiдвищення коефiцiєнту ефективностi в середньому на 3,2% в порiвняннi з пiдходом без додаткового подiлу.
• Для задачi В балансування навантаження з перерозподiлом мiж усiма процесами та додатковим подiлом має перевагу над iншими пiдходами для P ≥ 14, демонструючи пiдвищення коефiцiєнту ефективностi в середньому на 6,3% в порiвняннi з пiдходом без додаткового подiлу.
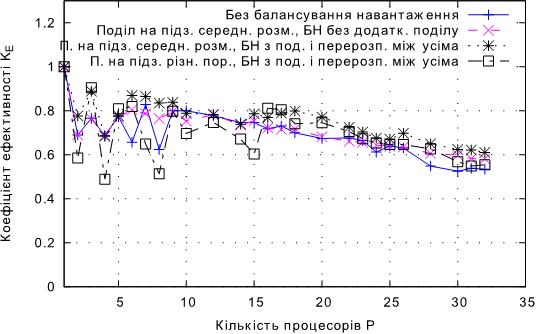
Рис. 4.20. Залежнiсть KЕ від кулькості процесорів при балансуванні навантаження з перерозподілом між усіма процесами та додатковим поділом для задачі Б.
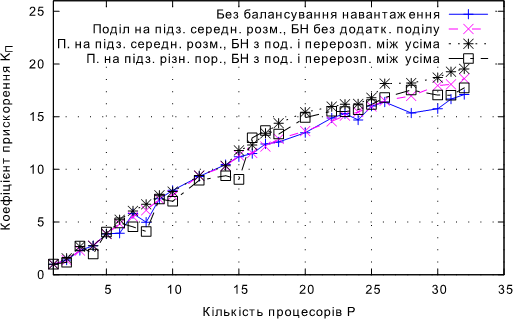
Рис. 4.21. Залежнiсть KП від кулькості процесорів при балансуванні навантаження з перерозподілом між усіма процесами та додатковим поділом для задачі Б.
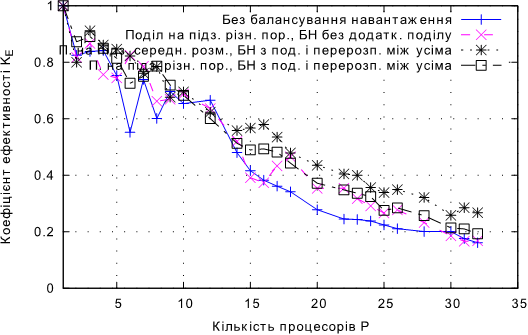
Рис. 4.22. Залежнiсть KЕ від кулькості процесорів при балансуванні навантаження з перерозподілом між усіма процесами та додатковим поділом для задачі В.
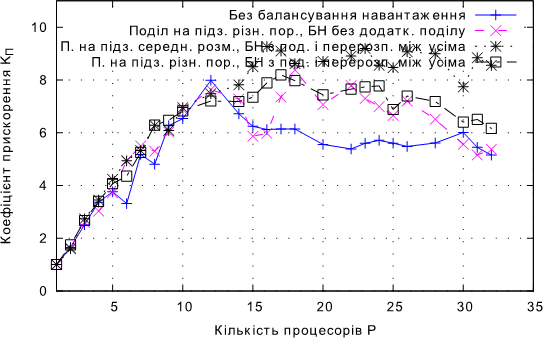
Рис. 4.23. Залежнiсть KП від кулькості процесорів при балансуванні навантаження з перерозподілом між усіма процесами та додатковим поділом для задачі В.
4.8. Балансування навантаження з врахуванням топології
Пiд час експериментiв з пiдходами до балансування навантаження з врахуванням топологiї на кластернiй системi Центру суперкомп’ютерних обчислень НТУУ «КПI» [57] було виявлено, що результати повнiстю спiвпадають з тими, якi були отриманi без врахування топологiї. Цей результат є очiкуваним через особливiсть топологiї кластеру: використовується топологiя «зірка», в якiй всi обчислювальнi вузли пiд’єднанi до одного InfiniBand комутатора, який реалiзує повнiстю неблокуючу комутацiю. 4.24 В такiй топологiї вiдстанi мiж будь-якими двома вузлами є однаковими, i тому врахування топологiї не дає переваг.
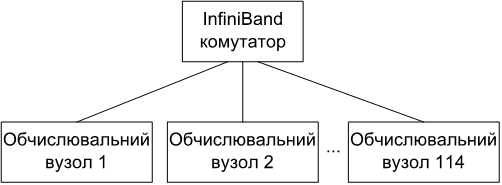
Рис. 4.24. Топологiя InfiniBand мережi, що використовується в кластернiй системi Центру суперкомп’ютерних обчислень НТУУ «КПI»
4.9. Особливостi реалiзацiї моделі системи пакетної обробки задач
Запропонованi пiдходи до динамiчної змiни зернистостi навантаження в теорiї виконують оптимiзацiю, що призводить до пiдвищення коефiцiєнта ефективностi KЕ, однак цi твердження потребують експериментальної перевiрки. Для експериментальної перевiрки доцiльно реалiзувати модель пакетної системи обробки задач та виконати експериментальнi запуски на кластернiй системi. До реалiзацiї висуваються наступнi вимоги:
- необхiдно, щоб тривалiсть додаткових дiй, якi пов’язанi з динамiчною змiною зернистостi, була значно менше, нiж виконання обчислень, безпосередньо пов’язаних з розв’язанням задачi;
- необхiдно, щоб обраний спосiб реалiзацiї не був специфiчним для певного апаратного забезпечення i пiдходив для великої кiлькостi кластерних систем.
Основну масу високопродуктивних систем на сьогоднiшнiй день складають кластернi системи, одиничним елементом яких є паралельна комп’ютерна система зi спiльною пам’яттю (обчислювальний вузол), що мiстить n ядер, а базовим елементом є комп’ютерна мережа. Таким чином, хоча окремi ядра i мають спiльну пам’ять, в цiлому кластерна система вiдноситься до систем з локальною пам’яттю. Для передачi даних зазвичай використовують двi мережi – високопродуктивна мережа, наприклад Infiniband, для передачi даних мiж вузлами та звичайний 100 Mb/ 1Gb Ethernet для зв’язку з зовнiшнiми обчислювальними системами та сховищами даних. Переважна бiльшiсть кластерних систем має реалiзацiю iнтерфейсу передачi повiдомлень MPI в якостi основного програмного iнтерфейсу передачi даних в рамках обчислювальної системи. Введення унiфiкованого iнтерфейсу передачi повiдомлень дозволяє абстрагувати апаратнi особливостi рiзних паралельних систем, зокрема особливостi системи зв’язкiв та способiв її використання. MPI дозволяє виконувати обчислення на будь-якому вузлi та органiзовувати передачу даних мiж будь-якою парою вузлiв в певних режимах. Другою частиною iнтерфейсу передачi даних зазвичай є паралельнi файловi системи, такi як Lustre, якi дозволяють працювати з локальними мережевими сховищами в рамках кластеру через стандартнi засоби роботи з файлами мов програмування, якi використовую користувач.
Таким чином, цi двi технологiї є де-юре i де-факто стандартним iнтерфейсом до бiльшостi кластерних систем. Тому доцiльно виконувати реалiзацiю пiдсистеми динамiчного балансування навантаження як окремого рiвня абстракцiї над MPI. Змiна набору абстракцiй або поведiнки безпосередньо технологiй слiд недоцiльна, оскiльки це радикальне рiшення буде мати вплив на вже iснуючi програми з його використанням, якi розраховують на вiдому поведiнку.
Реалiзацiя запропонованих пiдходiв виконана з метою демонстрацiї запропонованих принципiв на практицi, пiдтвердження можливостi досягнення заявлених характеристик та перевiрки висунутих гiпотез, створення можливостi проведення експериментiв. Через те, що дана реалiзацiя в першу чергу орiєнтована на дослiдження, вона не є оптимiзованою та має обмежену функцiональнiсть. Тим не менше, вiдсутнi принциповi перешкоди до створення повної реалiзацiї, орiєнтованої на практичне застосування.
4.10. Задачi, що використовувались в експериментах
Для експериментiв був обраний широкий спектр практичних наукових задач. Критерiями для пiдбору таких задач були:
а) Важливе наукове значення задачi.
б) Задача повинна складатися з серiї послiдовних крокiв.
в) Задача повинна масштабуватися, та потребувати високопродуктивної системи для досягнення достатньої швидкостi виконання.
Було пiдiбрано п’ять задач, якi вiдповiдають цим критерiям. Для кожної задачi були пiдiбранi типовi параметри, що вiдповiдають реальному використанню. До пiдiбраних задач вiдносяться:
BLAST – це експеримент, що займається пошуком спiвпадiнь протеїнiв та нуклеотидiв у базi даних геному. Як запити, так i архiвнi данi можуть мiстити продiли та помилки, але допустима ступiнь схожостi може регулюватися. Пiд час вирiшення цiєї задачi часто необхiдний повний перебор. Один запуск такої задачi приймає на вхiд послiдовнiсть, проводить пошук по базi даних та виводить знайденi спiвпадiння.
IBIS – це система глобального моделювання стану Землi. IBIS моделює впливи людських занять на стан зовнiшнього середовища (наприклад, глобальне потеплiння). Ця система виконує моделювання та створює серiю знiмкiв глобального стану землi.
CMS – експеримент з фiзики високих енергiй, що почав свою роботу у 2006 роцi. CMS складається з двох послiдовних частин: перша частина називається cmkin та, отримавши випадковi початковi данi, генерує та моделює поведiнку розiгнаних часток. Результати першого етапу передаються до програми cmsim, яка моделює вiдклик детектору часток. Кiнцевим результатом роботи експерименту є список подiй, сила яких перевищила порiг активацiї детектора часток.
Meskit Hartree-Fock – це експеримент по моделюванню нерелятивiстських взаємодiй мiж ядрами атомiв та електронами, що дозволяє обчислення таких властивостей як сила зв’язку, енергiя реакцiй тощо. Експеримент складається з трьох окремих програм: програма iнiцiалiзацiї, яка створює файли вхiдних даних на основi вхiдних параметрiв, argos обчислює та записує iнтеграли, що описують конфiгурацiї атомiв, svf iтеративно вирiшує самоузгодженi рiвняння поля.
AMANDA – програма для обробки астрофiзичних даних, яка визначає космiчнi подiї, такi як сплески гамма-випромiнювання, шляхом спостереження за видiленими нейтрино в момент їх взаємодiї з масою Землi. Перший етап калiбрування corsika моделює створення нейтрино та основну взаємодiю, яка створює потоки мюонiв. corama перетворює данi у стандартне представлення для фiзики високих енергiй. mmc моделює проходження мюонiв через землю та лiд, а також вносить атмосфернi шуми. Нарештi, amasim2 моделює вiдклик детектора на побiчнi мюони. AMANDA оброблює велику кiлькiсть невеликих, незалежно згенерованих подiй. Типовими об’ємами даних для одного запуску є 100000 потокiв. Слiд зауважити, що процесорнi ресурси та ресурси вводу-виводу, якi необхiднi для виконання такого пакету ростуть лiнiйно з кiлькiстю подiй
Деякi з цих прикладiв мають змiнну зернистiсть. CMS та AMANDA обробляють змiнну кiлькiсть малих, незалежних згенерованих подiй. Для цих прикладiв, ми будемо обирати розмiри конвеєру у 250 подiй (для CMS) та 100000 дощiв (для AMANDA), що вiдповiдає їх звичайнiй роботi. У обох випадках необхiднiсть у процесорних ресурсах та ресурсах для вводу-виводу росте лiнiйно в залежностi вiд кiлькостi Nautilus. IBIS та Nautilus виконують одне обчислення змiнного об’єму, у той час як BLAST та HF працюють над вхiдними даними фiксованого розмiру.
4.11. Час очiкування введення та виведення
Очiкування початку передачi даних за мережею, на вiдмiну вiд часу безпосередньої передачi даних, передбачає вiдсутнiсть виконання обчислень через неготовнiсть даних, що в свою чергу може суттєво вплинути на час виконання обчислень та на коефiцiєнт ефективностi.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
