
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис. 1.8. Строгий порядок передачi повідомлень
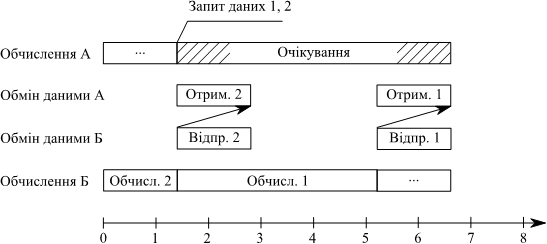
Рис. 1.9. Нестрогий порядок передачi повiдомлень
Колективна операцiя передбачає обмiн даними мiж бiльш нiж двома процесами. Такi операцiї можуть використовувати множиннi канали зв’язку та мультипрограмування або особливостi топологiї для органiзацiї деревовидного розповсюдження даних у випадку передач вiд одного до багатьох та вiд багатьох до одного, однак така поведiнка не вимагається явно в специфiкацiї iнтерфейсу i залежить вiд його реалiзацiї. Колективний обмiн мiж всiма процесам попарно може бути виконаний з паралельним обмiном даними мiж парами процесiв, що мають незалежнi канали зв’язку, що однак також не гарантується у всiх реалiзацiях iнтерфейсу передачi повiдомлень MPI.
Буферизованi передачi дозволяють виконати копiювання даних, що необхiдно передати у спецiальний буфер таким чином, щоб забезпечити подальшу роботу процесу, який iнiцiював цю передачу, в тому числi з його копiєю цих даних. У разi використання такої передачi, процес-джерело блокується на час копiювання даних у вiдповiдний буфер, пiсля чого може продовжувати виконання, навiть якщо данi ще не були переданi. Буферизованi передачi можуть створювати буфери як в локальнiй пам’ятi процесу, що виконує вiдправлення даних, в локальнiй пам’ятi процесу, що їх приймає, та навiть в обох. Такi передачi створюють передумови для вiдкладення безпосередньої передачi даних до того часу, як данi будуть явно необхiднi, однак буферизованi передачi не дозволяють органiзувати довiльний порядок отримання повiдомлень. Iстотним недолiком буферизованих передач є збiльшення обсягу пам’ятi, що використовується програмою, в два рази. Буферизованi передачi розпочинають вiдправлення даних одразу пiсля завершення їх копiювання у промiжний буфер процеса-джерела, якщо воно необхiдне, тому необхiдно розглянути чи доцiльно виконати безпосередньо передачу даних мiж вузлами пiзнiше, наприклад через фiксовану затримку або по запиту вiд отримувача.
Повiдомлення MPI також можуть виконувати певнi перетворення даних в процесi їх передачi [80]. Серед них можливiсть змiни порядку слiдування байтiв цiлих чисел (англ. endianness) для пiдтримки роботи в розподiлених системах з рiзними апаратними архiтектурами, та можливiсть перетворення користувацьких типiв за умови збереження або, в останнiх версiях iнтерфейсу, незбiльшення розмiру даних. Кiлькiсть даних, якi передаються, може змiнюватись в залежностi вiд стану програми пiд час роботи, тому розраховувати їх пiд час трансляцiї програми недоцiльно для бiльшостi вихiдних кодiв.
Iнтерфейс передачi повiдомлень MPI надає також спецiальний iнтерфейс прикладного програмування MPI Performance API для вимiрювання певних характеристик продуктивностi роботи програми, яка його використовує. [81] З його використанням можна отримати данi про час виконання певних операцiй, зокрема про час роботи функцiй передачi даних та обсяги переданих даних, пiсля їх завершення. Цей iнтерфейс, однак, не дає можливостi оцiнити час передачi даних, яка ще не була завершена, на основi попереднiх передач зi схожими характеристиками. Популярнi формати збереження цiєї iнформацiї для подальшого аналiзу [82] також не можуть зберiгати iнформацiю про час безпосереднього початку передачi даних.
Сучаснi реалiзацiї iнтерфейсу MPI [84] мають окрему реалiзацiю процедур передачi даних для випадку, коли процеси, мiж якими iнiцiйовано передачу, знаходяться в межах одного вузла, тобто мають доступ до локальної пам’ятi. В цьому випадку не створюються окремi буфери в обох процесах та можуть бути використанi засоби операцiйної системи для передачi контролю над певною дiлянкою пам’ятi iншому процесу.
Незважаючи на наявнiсть оптимiзованих для вузлiв з локальною пам’яттю версiй iнтерфейсу передачi повiдомлень, використання цього iнтерфейсу в так званих гiбридних системах, що являють собою об’єднання вузлiв, кожен з яких має спiльну пам’ять, в систему з локальною пам’яттю, у цiлому рядi випадкiв не дозволяє досягнути максимальної продуктивностi обчислювальної системи. [85] Це пояснюється використанням абстракцiї повiдомлення та виконанням додаткових операцiй щодо роботи з ними та забезпечення надiйностi передачi за умови передачi мережею, що не має сенсу при роботi в системах зi спiльною пам’яттю. Тому для розробки нових програм для таких систем пропонується використовувати одночасно iнтерфейс передачi повiдомлень MPI для органiзацiї передачi мiж вузлами та технологiю з використанням вказiвок компiлятору OpenMP для органiзацiї паралельних обчислень в межах одного вузла. Показано [86], що такий пiдхiд дозволяє зменшити загальний час виконання обчислень на подiбних системах. При цьому тим не менш, значно ускладнюється визначення даних, якi мають бути переданi мiж вузлами та органiзацiї доступу для них в межах одного вузла.
На сьогоднiшнiй день iснує ряд бiблiотек вихiдних кодiв та компонентiв програмного забезпечення, якi допомагають розв’язувати певнi математичнi задачi з використанням технологiй паралельних обчислень. До них, наприклад, можна вiднести використовуванi у Центрi суперкомп’ютерних обчислень НТУУ «КПI» [57] програмнi пакети Gromacs, fftw, Gamess та деякi iншi. Цi пакети програмного забезпечення мiстять в собi запрограмованi з використанням технологiї MPI паралельнi реалiзацiї алгоритмiв для чисельних розрахункiв проблем молекулярної динамiки, молекулярної бiологiї, математичної фiзики та низку загальновживаних математичних методiв, як то перетворення Фур’є. Такi пакети програмного забезпечення є, зазвичай, вузько спецiалiзованими та дозволяють отримувати досить високi показники коефiцiєнту ефективностi використання паралельної обчислювальної системи та вiдносно невеликий час розв’язання у порiвняннi з бiльш узагальненими пiдходами. Однак, їх вузька спецiалiзацiя призвела до того, що їх проектування, програмування i оптимiзацiя виконувались з огляду лише на особливостi певної задачi та властивостi iснуючих паралельних алгоритмiв для її розв’язання, що унеможливлює узагальнення використаних пiдходiв для досягнення бiльшої продуктивностi розв’язку iнших задач. Разом з тим, використання таких пакетiв не вимагає вiд їх користувача глибоких знань в паралельному програмуваннi та архiтектурi паралельних обчислювальних систем, так як вiн взаємодiє з високорiвневим iнтерфейсом в термiнах умов розв’язуваної задачi, а безпосереднє виконання обчислень виконується пакетами програмного забезпечення.
Комплекс паралельних методiв для розв’язку задач лiнiйної алгебри LAPack [87,88] є одним з найбiльш яскравих прикладiв узагальненої бiблiотеки вихiдних кодiв, яка застосовується при розв’язаннi прикладних та наукових задач. Оскiльки бiльшiсть розрахункiв так чи iнакше спирається на математичнi методи, ефективне розпаралелювання саме ресурсоємних методiв алгебри дозволяє досить ефективно розв’язувати задачi, описанi з використанням термiнологiї лiнiйної алгебри. В цьому разi користувач обчислювальної системи також не має взаємодiяти з iнтерфейсами паралельного та розподiленого програмування безпосередньо, а лише описати свою задачу з використанням вiдповiдного пiдтримуваного математичного апарату та переписати математичнi викладки на мовi програмування. Останнє перетворення може бути виконане навiть в автоматизованому режимi за допомогою сучасних програмних комплексiв для математичних розрахункiв.
Iншою широко застосованою бiблiотекою паралельних алгоритмiв є бiблiотека Ouverture [89], яка використовується для розв’язання диференцiйних рiвнянь в часткових похiдних. Даний математичний апарат також застосовується в багатьох актуальних наукових та iнженерних задачах. Бiблiотека Ouverture мiстить в собi два взаємозамiнюванi компоненти A++ та P++, якi забезпечують iдентичний iнтерфейс для опису задач з диференцiйними рiвняннями високорiвневими засобами мови С++, зокрема з використанням шаблонiв. Користувач може пiдключати один або iнший компонент для обчислення розв’язку поставленої задачi в залежностi вiд використовуваного апаратного забезпечення: компонент А++ дозволяє iнiцiювати послiдовний розв’язок, в той час як Р++ – паралельний, з використанням технологiї MPI [79]. Такий пiдхiд спрощує перевiрку коректностi запрограмованих алгоритмiв на невеликих обсягах даних без задiяння ресурсiв великих розподiлених обчислювальних систем, а сумiснiсть iнтерфейсiв компонентiв дозволяє користувачу бiблiотеки абстрагувати математичнi обчислення вiд безпосередньої взаємодiї з iнтерфейсами паралельного програмування.
Розробка та використання подiбних програмних пакетiв набули значних обсягiв з розповсюдженням розподiлених систем. Запропонований пiдхiд абстрагування логiки задач користувача вiд низькорiвневої взаємодiї з паралельними системами з одного боку спрощує використання таких систем для розв’язання наукових та iнженерних задач користувачами, якi не є фахiвцями в областi паралельних систем, а з iншого – дозволяє адаптувати та оптимiзувати програмне забезпечення таких бiблiотек пiд конкретну обчислювальну систему. На жаль, подiбнi пакети програмного забезпечення розробленi лише для певних задач та, як було показано вище, не можуть бути узагальненi для розв’язку довiльної користувацької задачi. Бiблiотеки паралельних алгоритмiв математичних методiв, що виконують подiбну роль, вимагають вiд розробника зведення його задачi до ряду реалiзованих в них математичних абстракцiй, що є нетривiальним. Таке зведення також може потребувати додаткових обчислень, що може нiвелювати переваги вiд використання паралельних систем через несумiснiсть математичних абстракцiй та вiдсутнiсть використання природного паралелiзму конкретної задачi або алгоритму її розв’язання.
1.15. Концепцiя вiдвантаження обчислень
На протязi останнiх рокiв виробники апаратного забезпечення для паралельних обчислювальних систем, зокрема виробники мiкропроцесорiв, значну увагу придiляють покращенню механiзмiв апаратної пiдтримки паралельного програмування. Наприклад, в нових мiкропроцесорах Intel сiмейства Haswell, появу яких анонсовано у другiй половинi 2013 року, з’явиться апаратна пiдтримка транзакцiйної моделi пам’ятi [90]. Ця модель, з використанням зворотньо-сумiсного апаратно реалiзованого алгоритму приховування блокувань (англ. hardware lock elision), дозволить не виконувати блокування доступу до пам’ятi, що використовуються спiльно декiлькома процесорами, якщо воно гарантовано не змiнить поведiнку програми (наприклад, якщо вiдбувається лише читання), навiть якщо в програмi виконується блокування. Такий пiдхiд дозволить спростити розпаралелювання iснуючих програм, оскiльки виявлення залежностей за даними та коректного порядку читань та записiв даних є однiєю з найбiльш важких задач у розпаралелюваннi, зокрема при застосуваннi складних алгоритмiв над великими обсягами даних, що зазвичай i призвело до необхiдностi паралельної реалiзацiї алгоритму. З використанням транзакцiйної моделi пам’ятi, достатньо лише позначити певнi частини, коду якi потенцiйно можуть виконувати доступ в множини адрес, що перетинаються, а безпосередньо перевiрка коректностi такого доступу та розв’язок проблеми взаємного виключення буде виконаний пiд час роботи програми на апаратному рiвнi [91]. Крiм того, оскiльки виконання програми може змiнюватись в динамiцi, необхiднiсть забезпечення взаємного виключення може i не виникати при певних запусках того ж самого програмного забезпечення. Запропонований пiдхiд, тим не менш, може бути застосований лише на рiвнi кеш-пам’ятi процесора з урахуванням наявностi протоколiв когерентностi, тобто орiєнтований лише на роботу в системi зi спiльною пам’яттю. Цей пiдхiд дозволяє спростити розв’язання задачi взаємного виключення та зменшити обсяг використовуваних системних ресурсiв при програмуваннi обчислювальних систем зi спiльною пам’яттю, однак не може бути прямо застосований до систем з локальною пам’яттю. Тим не менш, його слiд взяти до уваги при розглядi оптимiзованих версiй iнтерфейсу передачi повiдомлень, розглянутого в роздiлi 1.14.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
