
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Реалiзацiя запропонованих пiдходiв виконана з метою демонстрацiї запропонованих принципiв на практицi, пiдтвердження можливостi досягнення заявлених характеристик та перевiрки висунутих гiпотез, створення можливостi проведення експериментiв. Через те, що дана реалiзацiя в першу чергу орiєнтована на дослiдження, вона не є оптимiзованою та має обмежену функцiональнiсть. Тим не менше, вiдсутнi принциповi перешкоди до створення повної реалiзацiї, орiєнтованої на практичне застосування.
4.2. Задачi, що використовувались в експериментах
Запропонованi пiдходи органiзацiї динамiчного балансування навантаження можуть бути застосованi до розв’язання будь-яких задач. Програмiсту достатньо надати опис завдання у виглядi (2.21). Але для демонстрацiї роботи запропонованих пiдходiв та отримання емпiричних даних необхiдно розв’язати декiлька типових задач, якi вирiшуються на кластерних системах. Обрана модель програмування реалiзується у виглядi додаткового рiвня абстракцiї над низькорiвневим iнтерфейсом передачi повiдомлень, тому неможливо безпосередньо використати її для iснуючих програм iз застосуванням MPI; необхiдно виконати адаптацiю iснуючих програм. Було обрано ряд типових задач, якi мають характернi особливостi, поведiнку та схеми взаємодiї, та адаптовано для використання дослiдницької реалiзацiї.
З точки зору органiзацiї обчислень, часової складностi та подiлу паралельних реалiзацiй на такi, що мають регулярний та нерегулярний паралелiзм, можна видiлити наступнi широкi класи задач.
а) Задачi, для яких iснують паралельнi реалiзацiї з регулярним паралелiзмом, в яких обчислювальна складнiсть пiдзадач одного порядку є приблизно однаковою та обсяги вхiдних даних для цих пiдзадач також є близькими. Прикладами таких задач є операцiї лiнiйної алгебри iз щiльними векторами, матрицями та тензорами, що зберiгаються за стовпцями або рядками, в тому числi задачi одно - та багатовимiрної згортки, зокрема гаусово розмиття, дискретнi перетворення в системах ортогональних функцiй, зокрема перетворення Фур’є; розв’язання диференцiйних рiвнянь на рiвномiрних сiтках методами кiнцевих рiзниць тощо.
б) Задачi, для яких iснують паралельнi реалiзацiї з регулярним або нерегулярним паралелiзмом, в яких обчислювальна складнiсть пiдзадач є полiномiальною або бiльш простою (лiнiйною, логарифмiчною i так далi). До цього класу можуть бути вiднесенi задачi чисельного математичного аналiзу, зокрема чисельного iнтегрування зi складними характеристиками збiжностi; iтерацiйнi методи, що виконуються на iнтервалах до збiжностi; iтерацiйнi методи розв’язку систем лiнiйних рiвнянь; розв’язок диференцiйних рiвнянь методами кiнцевих рiзниць чи кiнцевих елементiв з адаптивними або нерiвномiрними сiтками тощо.
в) Задачi, для яких iснують паралельнi реалiзацiї з нерегулярним паралелiзмом, в яких обчислювальна складнiсть пiдзадач залежить вiд значень вхiдних даних, а не вiд їх обсягу, або задачi, в яких обсяги використаної пам’ятi можуть випадковим чином залежати вiд значень вхiдних даних або результатiв, отриманих при попереднiх обчисленнях. Таким чином, розподiл часу обчислення пiдзадач в залежностi вiд обсягiв вхiдних даних є випадковим. Прикладами таких задач є задачi лiнiйної алгебри над довiльними розрiдженими матрицями з випадковим заповненням; ймовiрнiснi методи, зокрема методи Монте-Карло; моделювання випадкових процесiв; деякi обчислювально складнi задачi на графах.
Така класифiкацiя задач не претендує на повноту, а лише має на метi показати типовi задачi, якi вирiшуються на кластерних системах.
Для проведення експериментiв з метою перевiрки висунутих гiпотез було обрано та реалiзовано по однiй задачi з кожного класу:
а) задача «А»: чисельне розв’язання диференцiйного рiвняння квантової оптики методом кiнцевих рiзниць з рiвномiрною сiткою;
б) задача «Б»: чисельне iнтегрування функцiй однiєї змiнної;
в) задача «В»: знаходження власних чисел та векторiв розрiдженої матрицi з випадковим заповненням.
Цi задачi є цiкавими не тiльки самi по собi, але також використовуються як етапи бiльш складних обчислень. Тому збiльшення ефективностi їх розв’язання також призведе до збiльшення ефективностi розв’язання бiльш складних задач.
4.3. Проведення експериментів
Характеристики кластерної системи
Для тестування розробленого прототипу пiдсистеми динамiчного балансування навантаження використовувалась кластерна обчислювальна система Центру суперкомп’ютерних обчислень НТУУ «КПI» з наступним апаратним забезпеченням вузла:
• процесори: два Intel Xeon E5345 (2,33 ГГц, 4 ядра, 8 Мб кеш-пам’ятi другого рiвня);
• оперативна пам’ять: DDR2 1333 МГц, 8192 Мб.
Вiдповiдно до правил запуску задач, при тестуваннi одночасно використовувалось до 32 ядер (тобто, не бiльше 4 вузлiв).
Характеристики мережевого обладнання:
• мережева карта InfiniBand HCA: Mellanox MT25204 (пiдтримує SDR, 10 Гбiт/с);
• комутатор Voltaire Grid Director ISR 9288 (пiдтримує SDR, 10 Гбiт/с, 288 портiв, реалiзує повнiстю неблокуючу комутацiю).
В якостi програмного забезпечення використовувались:
• операцiйна система: CentOS release 6.4 x86_64;
• компiлятор C++: g++ 4.7.2;
• реалiзацiя MPI: OpenMPI 1.6.4.
Методика тестування
Основними критерiями ефективностi розв’язання задач є коефiцiєнт ефективностi KЕ та коефiцiєнт прискорення KП, точне визначення яких дається в роздiлi??. Безпосередн№ вимiрювання цих коефiцi№нтiв неможливе. Тому замiсть цього виконуються вимiри часу роботи паралельної реалiзацiї T, а також її складовi вiдповiдно до (2.5). На основi цих вимiрiв обчислюються KЕ та KП.
Для вимiрювання часу виконання використовувався системний виклик clock_gettime(2), який на данiй кластернiй системi реалiзовано на основi високоточних апаратнi таймери, наявнi в сучасних процесорах; роздiльна здатнiсть цих таймерiв складає порядку одиниць – десяткiв наносекунд. [1]
Для вимiрювання часових характеристик MPI використовувалась його стандартна частина – iнтерфейс вимiрювання продуктивностi MPI Performance API, який дозволяє вимiрювати, наприклад, час виконання певних функцiй MPI, зокрема внутрiшнiх функцiй очiкування, таких як MPI_Wait. Для збору цих значень з мiнiмальним впливом часовi характеристики процесу виконання обчислень, виконувалось iнструментування на етапi компiляцiї викликiв вiдповiдних функцiй. [54] В результатi виконання iнструментованих виконавчих файлiв проводиться не тiльки обчислення, а й збiр та збереження iнформацiї про виконання програми у файлах трасування спецiального формату. [55] Також вимiрювались додатковi витрати часу на виконання пiдсистеми балансування навантаження та накладнi витрати на виконання iнструментацiї. В подальшому, отриманi файли трасування були проаналiзованi за допомогою розробленого в Центрi суперкомп’ютерних обчислень засобу аналiзу та вiзуалiзацiї статистики виконання програми. [56]
Всi вимiри проводились тричi та для кожного вимiру обиралось середнє значення серед трьох запускiв.
4.4. Ефективнiсть розв’язання задач без балансування навантаження
Спочатку необхiдно виявити, якою є ефективнiсть розв’язання трьох обраних задач без застосування динамiчного балансування навантаження. В табл. 2.2 наведенi комбiнацiї способiв органiзацiї окремих етапiв балансування навантаження, якi доцiльно використовувати. Серед цих комбiнацiй є три, якi не включають в себе власне балансування навантаження. Тому цi три комбiнацiї приймаємо за базовий рiвень та будемо порiвнювати iншi комбiнацiї в першу чергу з ними. Цi три комбiнацiї вiдрiзняються способами попереднього подiлу задачi. Так як подальший подiл задачi не виконується, то в даних випадках способи попереднього подiлу визначають зерно паралелiзму. Для рiзних задач оптимальними є рiзнi розмiри зерна паралелiзму. Тому, щоб визначити, який iз запропонованих трьох способiв подiлу є найбiльш близьким до оптимального, необхiдно провести порiвняння.
Результати тестування розв’язання задач без використання балансування навантаження представленi на рис. 4.2 – 4.7 .
В результатi аналiзу отриманих даних виявлено наступне:
• Для задачi A максимальне значення коефiцiєнту прискорення склало 14 на 31 процесорi, при чому використовувався подiл на пiдзадачi рiзного порядку. Отже, гiпотеза 2 пiдтверджена. Це очiкуваний результат, тому що для задач, де для кожного елементу даних виконується однакова кiлькiсть операцiй, спосiб подiлу на пiдзадачi рiзного порядку мiнiмiзує незбалансованiсть навантаження, а будь-який додатковий подiл є надмiрним та тiльки призводить до додаткових накладних витрат, в тому числi, на об’єднання результатiв.
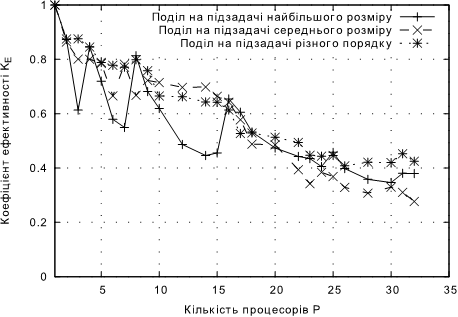
Рис. 4.2. Залежнiсть KЕ від кількості процесорів для підходів без балансування навантаження для задачі А.
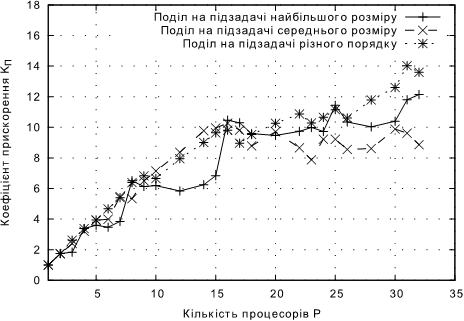
Рис. 4.3. Залежнiсть KП від кількості процесорів для підходів без балансування навантаження для задачі А.
Однак слiд вiдмiтити, що для 4..16 процесорiв попереднiй подiл на пiдзадачi середнього розмiру дає приблизно однаковi показники ефективностi з подiлом на пiдзадачi рiзного порядку.
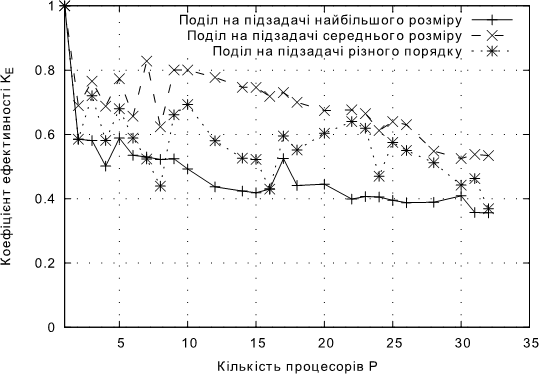
Рис. 4.4. Залежнiсть KЕ від кількості процесорів для підходів без балансування навантаження для задачі Б.
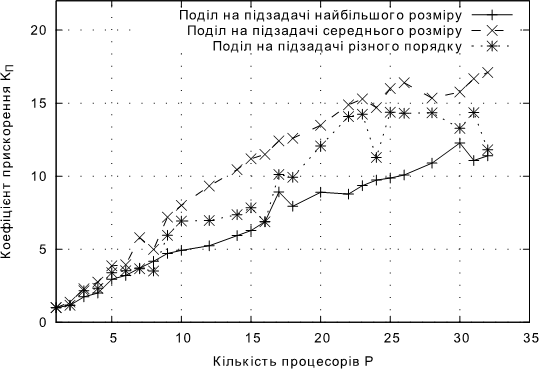
Рис. 4.5. Залежнiсть KП від кількості процесорів для підходів без балансування навантаження для задачі Б.
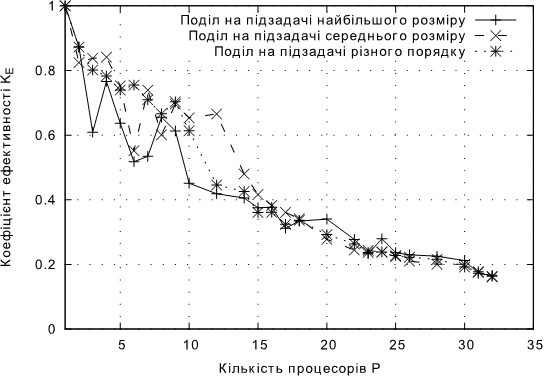
Рис. 4.6. Залежнiсть KЕ від кількості процесорів для підходів без балансування навантаження для задачі В.
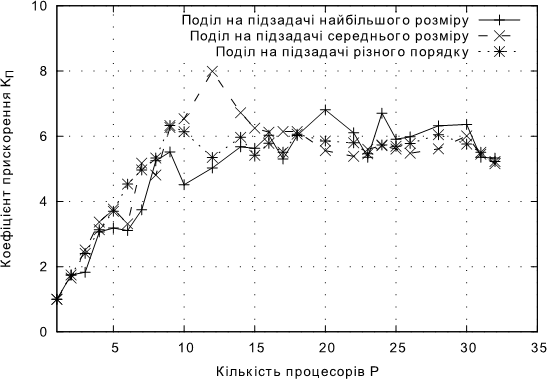
Рис. 4.7. Залежнiсть KП від кількості процесорів для підходів без балансування навантаження для задачі В.
• Для задачi Б найкращим способом подiлу виявився спосiб подiлу на пiдзадачi однакового порядку середнього розмiру. Максимальне значення коефiцiєнту прискорення склало 17,1 на 32 процесорах. При цьому цей спосiб показував кращi результати, нiж iншi способи, у всiх запусках.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
