
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис. 6.14. Статистика викликів функцій показує велику
тривалість введення даних
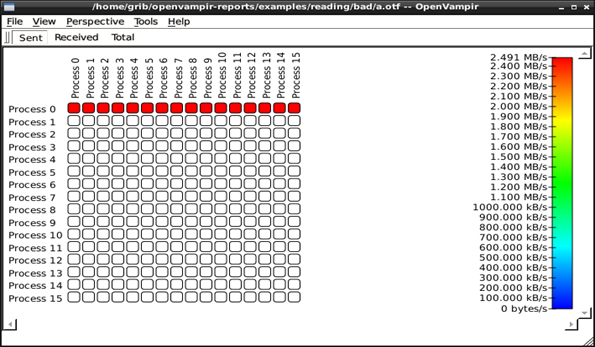
Рис. 6.15. Статистика відправлених повідомлень показує,
що завдання 0 виробляє розсилку
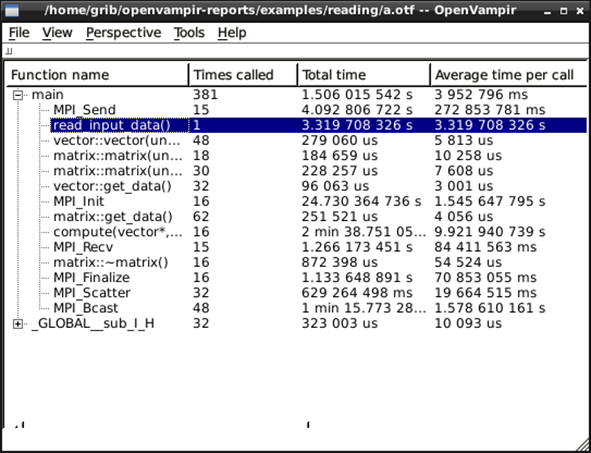
Рис. 6.16. Статистика викликів функцій при правильному
запуску програми
6.9.4. Множення вектора на розріджену матрицю (SpMV)
Фрагмент програми, що аналізується виконує множення вектора на розріджену матрицю у форматі зберігання CSR.
У початковому варіанті програми обчислювальна робота розподілена нерівномірно між вузлами (рис. 6.17). Знаючи специфіку задачі, можна висунути гіпотезу про те, що нерівномірність навантаження викликана розбиттям вихідної розрідженої матриці на неоднакові за розміром частини. Перевірити гіпотезу можна за допомогою діаграм статистики повідомлень, причому необхідно вибрати часовий проміжок, в якому відбувається розсилка даних. Діаграми (рис. 6.18, 6.19) не суперечать гіпотезі. [119, 120, 123, 128]
При подальшому аналізі вихідного коду виявляється, що відбувається розсилка рівної кількості рядків матриці (а не приблизно однакової кількості елементів матриці). Виправлення алгоритму розбиття матриці зменшило нерівномірність навантаження і різницю між розміром найбільшою і найменшою частин склала менше 1% від розміру найбільшої частини.

Рис. 6.17. Часова діаграма показує нерівномірний розподіл
обчислювального завантаження
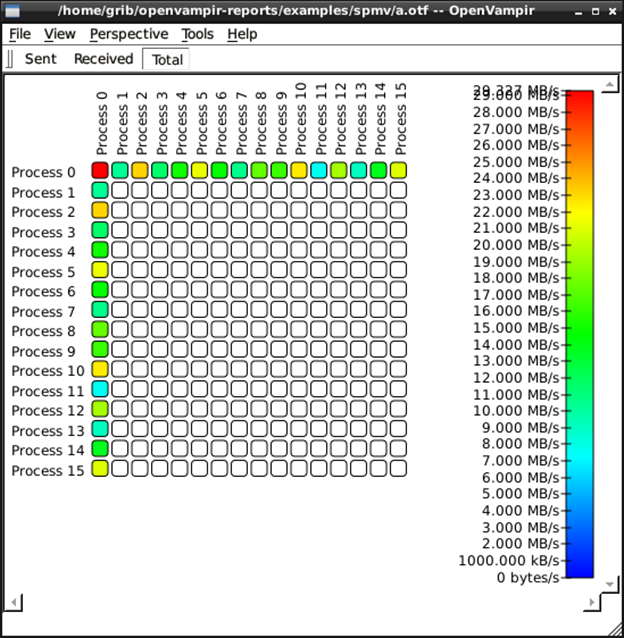
Рис. 6.18. Статистика відправлених повідомлень
показує нерівномірне розбиття матриці
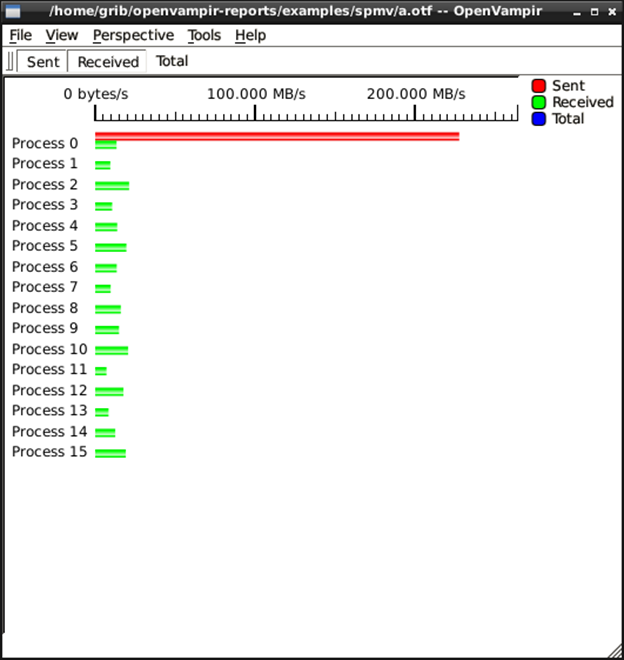
Рис. 6.19. Статистика відправлених повідомлень показує
нерівномірне розбиття матриці
6.10. Компіляція і збірка
Для успішної компіляції і збірки програмного забезпечення використовувались такі програми на користувальницької обчислювальної системи:
· GCC и G++ 4.6.1;
· GNU Make 3.81.
Додатково необхідні наступні бібліотеки і утиліти:
· Qt 4.7.4, включаючи Qmake 2.0.1a;
· Boost 1.4.0;
· OTFLib 1.9;
Qt
Для установки бібліотеки Qt необхідно виконати наступні кроки:
а) Якщо бібліотека доступна у вигляді системного пакету (наприклад як в Debian GNU / Linux), слід встановити її системними засобами. Для Debian GNU / Linux це буде виглядати наступним чином:
$ Su - l root
$ Apt-get install libqt4-core libqt4-dev qt4-qmake
б) У випадку, якщо такий пакет не доступний, необхідно конфігурувати, скомпілювати і встановити бібліотеку з вихідних кодів наступним чином:
$ Cd qt-src-4.7
$ ./configure
$ make
$ Make install
в) Якщо інсталяція вироблялася з вихідних кодів, так само необхідно додатково встановити змінні оточення, додавши наступні рядки в файл. profile:
$ PATH = / usr / local / Trolltech / Qt-4.7 / bin: $ PATH
$ Export PATH
$ LD_LIBRARY_PATH = / usr / local / Trolltech / Qt-4.7 / lib: $ PATH
$ Export LD_LIBRARY_PATH
Boost
Для установки бібліотеки Boost необхідно виконати наступні кроки:
а) Завантажити вихідні коди бібліотеки.
б) Розпакувати архів з вихідними кодами:
$ Tar xjf boost_1_4_0.tar. bz2
в) Перейти в розпаковану папку:
$ Cd./boost_1_4_0
г) Виконати конфігурацію, збірку і інсталяцію бібліотеки за допомогою наступних команд:
$ ./bootstrap. sh --exec-Prefix = / usr / local --libdir = <library dir> \
--includedir = <include dir>
$ Su - l root
$ ./bjam Install
OTFLib
Для установки бібліотеки OTFLib необхідно виконати наступні кроки:
а) Завантажити вихідні коди бібліотеки.
б) Розпакувати архів з вихідними кодами:
$ Tar - xgf OTF-1.9.tar. gz
в) Перейти в розпаковану папку:
$ Cd OTF-1.9
г) Виконати конфігурацію, збірку і інсталяцію бібліотеки в каталог /home/<username>/otf1.9 за допомогою наступних команд:
$ ./configure --prefix = $ HOME / otf1.9
$ make
$ Make install
Для компіляції програмного продукту необхідно виконати наступні дії:
а) Розпакувати архів з програмним продуктом:
$ Tar - xzf OpenVampir. tar. gz <path>
б) Перейти в каталог <path> / src:
$ Cd <path> / src
Для запуску програмного продукту необхідно виконати наступні дії:
а) Перейти в каталог <path> / src / release:
$ Cd <path> / src / release
б) Запустити виконуваний файл openvampir:
$ ./openvampir
Висновки до розділу 6
У даному розділі на чотирьох прикладах паралельних MPI програм продемонстровані можливості розробленого програмного забезпечення. Показані типові прийоми використання та продемонстровано практичне застосування методики роботи з профілювальником.
Одна і та ж проблема незбалансованості обчислювального навантаження може мати різні причини. У розробленому програмному забезпеченні присутні різні види аналізу, які можуть допомогти знайти дійсну причину проблеми.
Профілювання є важливим етапом в розробці програмного забезпечення промислового рівня, особливо важливим у високопродуктивних обчисленнях, оскільки дозволяє істотно підвищити коефіцієнти прискорення та ефективності в розподілених системах і зменшити час роботи програми в цілому. Профілювання дозволяє виявити ділянки програми, що потребують оптимізації в першу чергу, для досягнення найкращих показників часу виконання.
Логічним продовженням процесу профілювання є оптимізація програмного продукту, зокрема - синтез оптимізованої топологічної організації, що підходить для ефективного використання ПЗ, що використовується. Синтез такий топологічної організації часто неможливий без використання спеціалізованого програмного забезпечення і вельми трудомісткий, але в більшості випадків дозволяє істотно прискорити виконання програми.
На сьогоднішній день переважна більшість розподілених обчислювальних систем представлена кластерними системами, а програмне забезпечення для них, як правило, розробляється з використанням інтерфейсу MPI і супутніх технологій. Тому при розробці засобів профілювання програм для розподілених систем доцільно орієнтуватися саме на дані технології. На додаток, механізм віртуальних топологій MPI дозволяє на льоту адаптувати субоптимальні програмні топологічні організації до реальних фізичних.
Був розроблений програмний продукт, що дозволяє аналізувати виконання програми в умовах реальної розподіленої системі і синтезувати субоптимальні топологічні організації на основі такого аналізу. Даний продукт використовує підхід запису трасувальних файлів під час роботи програми і подальший їх незалежний аналіз. Такий підхід дозволив розділити збір даних і проведення їх дослідження, що істотно розширює можливості застосування розробленого програмного забезпечення і покращує якість аналізу. Більшість кластерних систем не припускають можливість інтерактивної взаємодії і виконання дій, пов'язаних з розробкою програм, безпосередньо на цільовій системі. Запропонований підхід дозволяє ефективно вирішити цю проблему, не збільшуючи навантаження на цільову систему, зберігаючи при цьому оточення і динамічний стан аналізованої програми.
У розробленому програмному продукті запропоновано ряд засобів, що надають можливості візуального аналізу поведінки досліджуваної програми. Ці засоби дозволяють детально аналізувати особливості виконання паралельних програм, такі як взаємодія між різними процесами, пересилання даних, синхронізацію обчислень, співвідношення часу обчислення і часу пересилань, тобто, такі параметри програми, які складно проаналізувати існуючими засобами.
Запропонована загальна методика аналізу паралельних програм з використанням розробленого продукту. На реальних прикладах продемонстровані методи пошуку можливих проблем в програмах і описані шляхи їх вирішення. Комплексне використання всіх присутніх в розробленому продукті засобів дозволяє виявити складні помилки в проектуванні досліджуваної програми, які хоч і не призводять до відмов або некоректних результатів, але можуть істотно знизити ефективність паралельного виконання.
Продемонстрований процес побудови віртуальної топології для реального прикладу, на основі наданих програмним продуктом результатів програміст може згенерувати MPI код для реалізації такої організації, тим самим, нормалізуючи навантаження на систему зв'язку обчислювальної системи і підвищуючи реальну продуктивність завдання
Розроблений програмний продукт може бути корисний розробникам програмного забезпечення розподілених обчислювальних систем і операторам таких систем з метою тонкої оптимізації використовуваного обчислювального програмного забезпечення. Він також може бути використаний у навчальному процесі для наочного пояснення принципів роботи MPI програм, а також поглибленого вивчення механізму віртуальних топологій.
Автор висловлює подяку Центру суперкомп'ютерних обчислень НТУУ «КПІ» за наданий машинний час для розробки та тестування програмного забезпечення.
ВИСНОВКИ
В дисертації наведено теоретичне узагальнення і нове вирішення наукової проблеми, яка полягає в розвитку теоретичних основ побудови кластерних паралельних обчислювальних систем, що мають високу продуктивність за рахунок використання ефективних засобів організації обчислювальних процесів на їх рівні.
Розроблені методи і засоби забезпечили підвищення ефективності паралельних обчислень в кластерних системах шляхом прискорення рішення проблемно-орієнтованих задач з регулярним і нерегулярним паралелізмом та кращого завантаження апаратно-програмних ресурсів завдяки запропонованому механізму балансування.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
