
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Можливi багато пiдходiв до динамiчного балансування навантаження. Було виявлено, що в даному випадку для поставленої задачi найбiльш доцiльно проводити динамiчне балансування навантаження пiсля пакетного планувальника, але перед планувальником операцiйної системи. Цей пiдхiд має наступнi переваги мiж iншими розглянутими: не потребує додаткової апаратної пiдтримки; наявна можливiсть перерозподiляти одиницi роботи мiж рiзними вузлами (так як пiдсистема балансування навантаження буде розмiщена до планувальника ОС). В якостi мiнiмальної одиницi навантаження, яка пiдлягає балансуванню, обрано пiдзадачу, пiд чим розумiємо послiдовнiсть елементарних крокiв паралельної реалiзацiї алгоритму, якi можна виконати паралельно з деякими iншими пiдзадачами.
Пiдсистема динамiчного балансування навантаження працює не сама по собi, а в тiснiй взаємодiї з бiблiотеками часу виконання та операцiйною системою, якi забезпечують пiдтримку тої моделi програмування, яка використовується на вiдповiднiй паралельнiй ЕОМ. Тому було сформульовано вимоги до моделi програмування паралельних ЕОМ, яка буде використовуватись з динамiчним балансуванням навантаженням.
В якостi моделi програмування, яка задовольняє поставленi вимоги було обрано модель високорiвневої передачi повiдомлень (запропонована в статтях [52, 53]). Ця модель програмування паралельних ЕОМ надає високорiвневi абстракцiї для опису крокiв алгоритму, якi можна виконати паралельно, а також необхiдних для їх виконання даних. Крiм того, абстракцiї цiєї моделi значно ближче до прикладних задач, i тому більш прості в застосуванні. Подано математичний опис даної моделі та доведено дві теореми про властивостi операцiї подiлу.
Для обраної моделi програмування описано загальну схему динамічного балансування навантаження, яка складається з наступних етапів: попередній подiл задачi на пiдзадачi, початкова розсилка пiдзадач, основний цикл обчислень. Запропоновано ряд пiдходiв органiзацiї кожного з цих етапів. В якості базового пiдходу органiзацiї основного циклу обчислень використано пiдхiд без балансування навантаження: вiн забезпечує виконання всiх необхiдних крокiв для отримання результату вихiдної задачi T0, але не мiстить крокiв що забезпечують динамiчне балансування навантаження. Всi iншi пiдходи тiльки доповнюють дiї базового варiанту.
Пiдходи з перерозподiлом вiд одного процесу виключають можливiсть транзитних пересилок даних мiж ядрами (рис. 2.10), що гарантує виконання не бiльше однiєї пересилки вхiдних даних мiж вузлами. Пiдходи з перерозподiлом мiж усiма процесами вимагають наявностi початкової розсилки пiдзадач, пiсля чого в процесi виконання перерозподiляють пiдзадачi за необхiднiстю.
Запропоновано виконувати додатковий подiл пiдзадач, для того, щоб забезпечити обробку, з часом, все менших та менших пiдзадач: поступового зменшення зерна паралелiзму. В результаті незбалансованiсть навантаження буде визначатись розмiром задач, якi обробляються останніми. Останнiми будуть оброблятись неподiльнi задачi, тому що неподiльнi задачі врештi-решт будуть отримані в результаті поділу. При виборi пари ядер, мiж якими виконується балансування навантаження, доцільно враховувати топологію системи, щоб забезпечити менший час передачі та зменшити навантаження на канали зв’язку. Не всі комбiнацiї запропонованих пiдходiв доцільно використовувати, тому надано рекомендації щодо комбінування пiдходiв в різних етапах динамічного балансування навантаження.
В даному роздiлi висунуто ряд гіпотез щодо запропонованих пiдходiв. Подальша перевірка цих гіпотез дозволить перевірити коректність припущень, які були покладено в основу розробки вiдповiдних пiдходiв.
РОЗДІЛ 3
ТЕОРИТИЧНІ ОСНОВИ МЕХАНІЗМУ ВІДКЛАДЕННЯ ПОЧАТКУ ПЕРЕДАЧІ ДАНИХ
3.1. Формулювання задачi визначення моменту початку
передачi даних
Будемо розглядати паралельне виконання обчислень в гетерогеннiй, тобто неоднорiднiй, обчислювальнiй системi з локальною пам’яттю, що мiстить K вузлiв та N процесорiв. Один вузол може мiстити вiд 1 до (N – K + 1) процесорiв. Гетерогеннiсть системи може полягати в рiзнiй продуктивностi обчислювальних вузлiв або у рiзнiй пропускнiй здатностi мережевих зв’язкiв мiж ними, при чому мережа органiзована таким чином, щоб забезпечити можливiсть зв’язку мiж будь-якою парою вузлiв.
Виконання паралельних обчислень в системi з локальною пам’яттю передбачає пересилання даних, якi необхiднi для виконання певної частини обчислень, з локальної пам’ятi одного вузла в локальну пам’ять iншого, на якому будуть виконуватися обчислення. Позначимо Mi обсяг пам’ятi, що використано в i-тому вузлi, де i ∈ – номер вузла. Позначимо mk розмiр k-го блоку даних. Позначимо tirdy, k час готовностi k-го блоку даних в i-тому вузлi, необхiдних для обчислення в певному iншому j-тому вузлi, такому що i ≠ j Причому tirdy, k = 0 ∀i ∈ ![]() для вхiдних даних, якi не обчислюються в процесi роботи (вважаємо, що вхiднi данi перенесенi засобами операцiйної системи на всi вузли, в яких вони необхiднi для обчислень) Позначимо
для вхiдних даних, якi не обчислюються в процесi роботи (вважаємо, що вхiднi данi перенесенi засобами операцiйної системи на всi вузли, в яких вони необхiднi для обчислень) Позначимо ![]() час запиту k-го блоку даних для виконання обчислень з його використанням в j-тому вузлi. Вiдмiтимо, що для у загальному випадку, обсяг пам’ятi, що буде використано, може залежати вiд значень вхiдних даних та вiд результатiв обчислень на попереднiх кроках, тому його необхiдно враховувати динамiчно, тобто в процесi виконання обчислень. Тодi необхiдно визначити моменти часу для початку передачi даних
час запиту k-го блоку даних для виконання обчислень з його використанням в j-тому вузлi. Вiдмiтимо, що для у загальному випадку, обсяг пам’ятi, що буде використано, може залежати вiд значень вхiдних даних та вiд результатiв обчислень на попереднiх кроках, тому його необхiдно враховувати динамiчно, тобто в процесi виконання обчислень. Тодi необхiдно визначити моменти часу для початку передачi даних 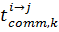 , такi що задовольняють нерiвнiсть ≥
, такi що задовольняють нерiвнiсть ≥ ![]() , максимiзують ефективнiсть використання обчислювальної системи KE → max та мiнiмiзують обсяг пам’ятi, що використано в усiх вузлах
, максимiзують ефективнiсть використання обчислювальної системи KE → max та мiнiмiзують обсяг пам’ятi, що використано в усiх вузлах 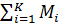 → min, з урахуванням можливостi багаторазової змiни вузла j на j′ у промiжок часу
→ min, з урахуванням можливостi багаторазової змiни вузла j на j′ у промiжок часу 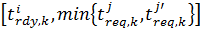 . У якостi критерiю ефективностi використовується коефiцiєнт ефективностi KE, який визначається вiдношенням прискорення паралельної реалiзацiї обчислень у порiвняннi з послiдовною реалiзацiєю до кiлькостi процесорiв N. [1] При визначеннi також врахувати час, необхiдний на безпосередню передачу даних мiж вузлами
. У якостi критерiю ефективностi використовується коефiцiєнт ефективностi KE, який визначається вiдношенням прискорення паралельної реалiзацiї обчислень у порiвняннi з послiдовною реалiзацiєю до кiлькостi процесорiв N. [1] При визначеннi також врахувати час, необхiдний на безпосередню передачу даних мiж вузлами ![]() , який залежить вiд структури системи та обсягу даних.
, який залежить вiд структури системи та обсягу даних.
Необхiдно розглянути три наступнi випадки спiввiдношень мiж часом запиту даних ![]() i часом готовностi даних
i часом готовностi даних ![]() . [64]
. [64]
а) Данi обчисленi ранiше, нiж вони використовуються вперше: ![]() <
< ![]() . В цьому випадку моделi, що забезпечують пiдтримку негайної передачi даних виконають перемiщення даних у момент готовностi останнiх =
. В цьому випадку моделi, що забезпечують пiдтримку негайної передачi даних виконають перемiщення даних у момент готовностi останнiх = ![]() , а моделi, що забезпечують пiдтримку вiдкладеної передачi даних виконають перемiщення у момент запиту =
, а моделi, що забезпечують пiдтримку вiдкладеної передачi даних виконають перемiщення у момент запиту = ![]() . При цьому, незалежно вiд пiдтримуваного способу передачi даних, обсяги пам’ятi, що використовується в обох процесах, мають пiдпорядковуватися обмеженням
. При цьому, незалежно вiд пiдтримуваного способу передачi даних, обсяги пам’ятi, що використовується в обох процесах, мають пiдпорядковуватися обмеженням
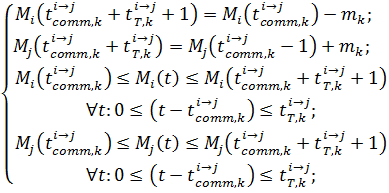 (3.1)
(3.1)
де першi два рiвняння показують, що пам’ять, яка була використана для зберiгання даних в i-тому вузлi може бути звiльнена пiсля завершення передачi, а в j-тому вузлi пiсля передачi має бути видiлено достатньо пам’ятi для зберiгання отриманих даних; а останнi двi нерiвностi показують, що видiлення та звiльнення пам’ятi може вiдбуватися будь-яким чином в процесi передачi, наприклад лiнiйно або стрибкоподiбно на початку та у кiнцi передачi. В даному випадку необхiдно визначити такий час початку передачi , ![]() , ≤ , ≤
, ≤ , ≤ ![]() , що максимiзує ефективнiсть та мiнiмiзує максимальний обсяг використаної пам’ятi на промiжку часу
, що максимiзує ефективнiсть та мiнiмiзує максимальний обсяг використаної пам’ятi на промiжку часу 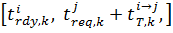 :
:
![]()
Слiд зазначити, що обсяг пам’ятi, що використана в кожному з процесiв, може залежати вiд значень вхiдних даних або результатiв попереднiх обчислень, тому недоцiльно виконувати оптимiзацiю статично.
В цьому випадку також необхiдно врахувати можливiсть змiни вузла j, на якому фактично будуть виконанi обчислення, у час 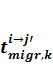 , такий що
, такий що 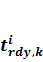 < < min
< < min 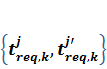 внаслiдок роботи методiв балансування навантаження. При цьому, якщо k-тий блок даних вже було передано у локальну пам’ять j-того вузла, необхiдно передати його iз локальної пам’ятi вузла j у локальну пам’ять вузла j′. Для мiнiмiзацiї часу, необхiдного на передачу даних, необхiдно також мiнiмiзувати рiзницю мiж часом передачi та часом запиту даних
внаслiдок роботи методiв балансування навантаження. При цьому, якщо k-тий блок даних вже було передано у локальну пам’ять j-того вузла, необхiдно передати його iз локальної пам’ятi вузла j у локальну пам’ять вузла j′. Для мiнiмiзацiї часу, необхiдного на передачу даних, необхiдно також мiнiмiзувати рiзницю мiж часом передачi та часом запиту даних
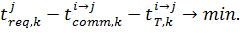

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
