
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
– можливість автоматичної зміни зерна паралелізму.
Але залишається недолік: ця модель розрахована тільки на системи зі спільною пам’яттю, так як в абстракціях даної моделі відсутнє поняття даних та відсутній жорсткий зв’язок обчислень з даними.
Таким чином, доцільно скомбінувати дану модель програмування з моделлю низькорівневої передачі повідомлень та реалізувати динамічне балансування навантаження для такої комбінованої моделі програмування з метою підвищення ефективності використання ресурсів ЕОМ.
В табл. 1.3 перелічено види обчислювальних систем, які підтримуються певними технологіями паралельних обчислень. Неважко вiдмiтити, що на даний момент не підтримуються вiдкладенi обчислення на системах з локальною пам’яттю. Однією з задач, яку необхідно розв’язати для забезпечення їх підтримки є ефективна органiзацiя пересилання даних.
Таблиця 1.3
Підтримка певних обчислювальних систем в моделях програмування
Час початку пере-дачi даних | Технології паралельного програмування з підтримкою обчислювальних систем: | ||
зi спiльною пам’яттю | з локальною пам’яттю | з використанням акселераторів | |
Негайна передача даних та обчис-лення | OpenMP, TBB, ArBB | MPI | CUDA, CUDA-MPI |
Вiдкладена пере-дача даних та об-числення | C++ Futures, Haskell | – | Частково TBB |
Навiть при органiзацiї паралельних обчислень в системi зi спiльною пам’яттю частою проблемою є очiкування результатiв обчислення в iншому потоцi, без яких продовжити обчислення в даному потоцi неможливо. В певних випадках це очiкування викликане не безпосередньо обчисленнями, що має бути розв’язане за допомогою сучасних моделей програмування з пiдтримкою балансування навантаження, наприклад Threading Building Blocks, а через виконання безпосереднього копiювання даних в адресний простiр iншого потоку. Таке копiювання може бути викликане особливостями органiзацiї пам’ятi або необхiднiстю доступу до певної версiї даних, якi в подальшому можуть бути змiненi в процесi паралельних обчислень. З iншого боку, виконання копiювання даних вiдразу пiсля того, як вони були обчисленi, може збiльшити обсяг основної пам’ятi, що використовується пiд час обчислень, через необхiднiсть збереження двох копiй. Тому для таких систем доцiльно дослiдити можливiсть вибору моменту початку перенесення або копiювання даних, якi необхiднi iншому потоку, в довiльний час мiж завершенням їх обчислення та першим зверненням до них.
При органiзацiї паралельних обчислень в системах з локальною пам’яттю, час передачi необхiдних даних, оскiльки вона може виконуватись мережею, значно впливає на загальний час розв’язання задачi, тому вкрай необхiдно зменшити час очiкування даних. Завдяки мультипрограмуванню можливо органiзувати одночаснi обчислення та передачу даних мiж вузлами. При цьому слiд врахувати оцiнений час передачi даного обсягу даних та момент часу, у який цi данi будуть використанi. В сучасних обчислювальних системах з локальною пам’яттю використовуються складнi алгоритми планування, наприклад в системi HTCKondor допускається мiграцiя певних обчислювальних процесiв мiж вузлами, при якiй необхiдно також виконати копiювання всiх необхiдних даних. Якщо цi данi перед цим були перемiщенi з iншого вузла, то це може призвести до додаткових витрат часу через повторне перемiщення даних, тому може бути доцiльно вiдкладати безпосередню передачу даних до певного моменту часу. Також слiд зауважити, що в низькорiвневому iнтерфейсi передачi повiдомлень iснує можливiсть програмованої буферизацiї повiдомлень як в джерелi, так i в приймачi повiдомлення, тому необхiдно врахувати обсяги основної пам’ятi, що використовується в вузлах з цiллю мiнiмiзацiї.
Слiд зазначити, що переважна бiльшiсть технологiй та моделей програмування не дозволяє оцiнити час, необхiдний на копiювання або пересилання даних, не змiнюючи логiку роботи складових частин операцiйної системи. Однак, використання високорiвневих абстракцiй задач та пiдзадач, якi пов’язанi з необхiдними даними, може розв’язати цю проблему на рiвнi бiблiотеки часу виконання. Оцiнкою часу, необхiдного для виконання частини обчислень або пересилання даних в цьому разi може бути певне статистичне значення, отримане шляхом аналiзу часу, витраченого на аналогiчнi операцiї, що були виконанi для пiдзадач близьких розмiрiв. Тому доцільно орієнтуватись на моделі програмування, що застосовані у технології TBB та її розширенні на обчислювальні системи з локальною пам’яттю.
Передбачається, що застосування ідеї відкладених обчислень до пересилання даних мiж вузлами обчислювальної системи з локальною пам’яттю з огляду на оцінений час передачі та момент часу, у який буде виконане перше звернення до цих даних, дозволить зменшити час очiкування даних. При цьому слід також мiнiмiзувати обсяги основної пам’яті, що використовується для буферизацiї, оскільки надмірне використання пам’яті може сповільнити виконання програми через роботу системи підкачки в сучасних операційних системах.
РОЗДІЛ 2
ТЕОРЕТИЧНІ ОСНОВИ ПОБУДОВИ ВИСОКОЕФЕКТИВНИХ ЗАСОБІВ ДИНАМІЧНОГО БАЛАНСУВАННЯ НАВАНТАЖЕННЯ
2.1. Постановка задачі
Будемо розглядати процес обробки завдання в кластерній обчислювальній системі, яка є однорідною. Кластерна система є мультикомп’ютерною системою, одиничним елементом якої є паралельна обчислювальна система (обчислювальний вузол), що містить n ядер, а базовим елементом є комп’ютерна мережа. Нехай для задачі в кластерній системі виділено K обчислювальних вузлів. (Не важливо скільки всього вузлів в кластерній системі.)
Необхідно підвищити ефективність розв’язання задачі в кластерній системі за рахунок більш збалансованого навантаження обчислювальних ресурсів, які виділені задачі. Ресурси (обчислювальні ядра) для задачі виділяються один раз перед запуском задачі, і звільняються всі разом після завершення виконання задачі. Задача не може звільнити деякі ядра, якщо вони стали не потрібні, або надати запит і отримати більше ядер, якщо виникла така потреба.
Питання керування ресурсами обчислювальної системи, виділення ресурсів для завдань, планування завдань відносяться відповідно до функцій операційної системи та планувальника. Підходи до розв’язання цих задач глибоко вивчені та існує велика кількість способів їх розв’язання, [11, 12, 18] тому в даному досліджені ці питання не розглядаються, а використовуються відомі та реалізовані підходи.
2.2. Критерії ефективності розв’язання задачі та оцінка збалансованості навантаження
Відповідно до постановки задачі, обчислення виконуються на паралельній обчислювальній системі з локальною пам’яттю, вузли якої можуть містити спільну для певної невеликої кількості процесорів пам’ять.
Нехай для задачі виділено K вузлів, при чому i-тий вузол в свою чергу містить n процесорів. Таким чином загальна кількість ядер, які доступні задачі в паралельній обчислювальній системі визначається як 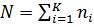 . Для спрощення вважаємо, що на виділених вузлах виконуються лише задача користувача, а також складові частини операційної системи та система керування паралельними обчисленнями. При цьому обсяги обчислень, що виконуються двома різними процесорами за одиницю часу, можуть відрізнятись.
. Для спрощення вважаємо, що на виділених вузлах виконуються лише задача користувача, а також складові частини операційної системи та система керування паралельними обчисленнями. При цьому обсяги обчислень, що виконуються двома різними процесорами за одиницю часу, можуть відрізнятись.
Позначимо час виконання паралельної реалізації алгоритму, що використовується у задачі, що розглядається, на заданій обчислювальній системі як T. Час виконання вимірюється від моменту активізації задачі (моменту початку обчислень) до моменту отримання кінцевого результату. Але час активного використання i-го процесора задачею складає ti, таке що:
ti ≤ T . (2.1)
через додатковi витрати часу, які специфічні для паралельних реалізацій: необхідність комунікації з іншими процесами, отримання доступу до спільного ресурсу тощо.
Час, необхідний для виконання тієї самої реалізації алгоритму в послідовному режимі на даній обчислювальній системі дорівнює сумі часу обчислень кожним процесором окремо 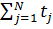 . Тоді коефіцієнт прискорення визначається відношенням оціненого часу обчислень в послідовному режимі до часу обчислень в паралельному режимі:
. Тоді коефіцієнт прискорення визначається відношенням оціненого часу обчислень в послідовному режимі до часу обчислень в паралельному режимі:
 (2.2)
(2.2)
Якщо врахувати обмеження (2.1), можна помітити, що коефіцієнт прискорення не може перевищувати кількості наявних процесорів:
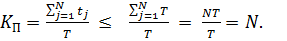 (2.3)
(2.3)
Фізичний зміст коефіцієнта прискорення: коефіцієнт прискорення показує, в скільки разів швидше можна розв’язати задачу в паралельному режимі, ніж в послідовному.
В такому разі коефіцієнт, ефективності визначається як відношення коефіцієнту прискорення до кількості наявних процесорів:
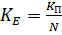 , (2.4)
, (2.4)
при чому, з урахуванням (2.3), коефіцієнт ефективності може приймати тільки значення на проміжку [0; 1], оскільки:
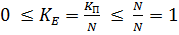 .
.
Фізичний зміст коефіцієнта ефективності: коефіцієнт ефективності показує частину машинного часу, під час якої виконувались обчислення. Дійсно, перепишемо (2.4), підставивши (2.2):
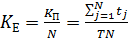 .
.
В чисельнику отримали загальний машинний час, протягом якого проводились обчислення, а в знаменнику – загальний затрачений машинний час.
Але з такого визначення коефіцієнта ефективності (2.4) не можна зробити висновків про те, що саме необхідно змінити, щоб збільшити значення коефіцієнта ефективності, окрім очевидного:
KП → max.
Щоб виявити, що саме підлягає вдосконаленню та сформулювати умови оптимізації, необхідно розглянути, які саме фактори впливають на коефіцієнт прискорення. Зокрема, слід проаналізувати складові сумарного часу обчислень T. Цей час має наступні складові:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
