
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Інженери-розробники мікропроцесорів шукають різні шляхи обходу вищеназваних фізичних обмежень. Серед популярних інженерних рішень варто виділити введення конвеєра та векторних інструкцій. Але ці розробки самі по собі не можуть дати необмежений приріст продуктивності без одночасного збільшення тактової частоти мікропроцесора. Таким чином, вони можуть забезпечити збільшення продуктивності тільки в константну кількість разів, а головним обмежуючим фактором все ж залишається тактова частота. З іншої сторони, ці розробки підходять не однаково гарно для різних програмних застосунків. Дійсно, якщо в програмному коді є багато переходів, напрямок яких важно передбачити, то переваги конвеєра зникають (мікропроцесор вимушений скидати конвеєр при виконанні неправильно передбаченого переходу). Якщо ж програмний код важко адаптувати до сучасних векторних та суперскалярних архітектур, то і переваг векторної чи суперскалярної архітектури застосунок отримати не зможе.
Таким чином, продуктивність окремих ядер зростає повільніше з року в рік.
Сучасним підходом до вирішення згаданих проблем є створення багатоядерних мікропроцесорів. [8, 9] Даний підхід передбачає розміщення декількох функціонально незалежних обчислювальних ядер разом з комунікаційним середовищем у спільному корпусі. Окремі ядра є рівноцінними з точки зору програміста прикладних програм, що дозволяє проводити процес програмування так само, як і для класичних багатопроцесорних систем.
Таким чином, сьогодні можливості прискорення розв’язання задач зосереджені саме в площині розпаралелювання обчислень. Тільки завантаживши всі обчислювальні пристрої, які працюють паралельно в сучасних ЕОМ, можна досягти максимальної швидкості розв’язання задач. Тому підвищення ступеня завантаженості паралельних ЕОМ, підвищення ефективності використання їх ресурсів, є важливою сучасною науково-технічною проблемою. Вирішення цієї проблеми можливе лише комплексно, як на апаратному, так і на програмному рівні:
– з однієї сторони, розробники апаратного забезпечення повинні створити передумови (наприклад, надавати такі абстракції і примітиви, які дозволять ефективно реалізувати необхідне програмне забезпечення);
– з іншої сторони, програмне забезпечення має створюватись з урахуванням характеристик сучасних паралельних ЕОМ, таких як декілька рівнів паралелізму та порядок кількості обчислювальних пристроїв на кожному рівні.
В даній роботі основна увага приділена підвищенню ефективності розв’язання задач через більш збалансоване завантаження всіх обчислювальних ядер кластерних обчислювальних систем. Вибір саме цього напряму досліджень зумовлений тим, що незбалансованість навантаження призводить до принципових обмежень значення коефіцієнту прискорення зверху деякою константою, в той час як недостатньо повне використання інших можливостей сучасних паралельних обчислювальних систем призводить до зменшення максимально можливого значення коефіцієнту прискорення в константну кількість разів, але не призводить до принципового обмеження зверху. Пояснимо це.
Нехай програма розпаралелена і запущена на N процесорних ядрах. При незбалансованому навантаженні на протязі деякого часу ТМ програма використовує не більше, ніж M ядер (M < N). Застосовуючи міркування аналогічні до тих, що покладені в основу закону Амдала, отримаємо, що максимальне
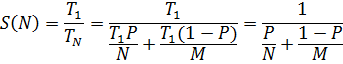
де: P – коефіцієнт від 0 до 1, який показує частину обчислень, що використовує N процесорних ядер; Т1 – час виконання програми на 1 ядрі; TN – час виконання програми на N ядрах.
Якщо спрямувати N до нескінченості та обчислити відповідну границю, то отримаємо, що максимальний коефіцієнт прискорення:
![]()
Тобто, максимальне значення коефіцієнту прискорення обмежується зверху через незбалансованість навантаження.
Розглянемо, до чого призводить недостатньо повне використання інших можливостей сучасних паралельних обчислювальних систем. Наприклад, нехай програма не використовує векторні команди, що наявні в даному процесорі. Тоді за одиницю часу програма виконує в K разів менше обчислень, де K – кількість елементів даних в векторному регістрі. У зв’язку з цим час виконання програми зростає в K разів, але на максимальний коефіцієнт прискорення це не впливає. Інший приклад: нехай програма не оптимізована з урахуванням суперскалярної архітектури сучасних процесорів. Тоді за одиницю часу програма викопує в L разів менше обчислень, де L – максимальна кількість команд, яку може виконати процесор за один такт. Таке сповільнення також не створює принципових обмежень на максимальний коефіцієнт прискорення.
Виходячи з міркувань, наведених вище, найбільший інтерес представляє зменшення незбалансованості завантаження всіх обчислювальних ядер, так як незбалансованість навантаження призводить до принципових обмежень значення коефіцієнту прискорення зверху деякою константою.
1.2. Процес обробки завдання в паралельній обчислювальній системі
Для того, щоб виявити за рахунок яких недоліків виникає недостатньо повне використання ресурсів паралельних обчислювальних систем, розглянемо процес обробки завдання в паралельній системі від його постановки в чергу користувачем до виконання.
Під завданням розуміємо зовнішню одиницю роботи обчислювальної системи, для якої безпосередньо система ресурси не виділяє.
Загальна схема процесу обробки завдання представлена на рис. 1.1. Весь процес планування в паралельній обчислювальній системі можна представити у вигляді багаторівневої схеми. [10] Завдання проходить через декілька рівнів планувальників, кожен з яких розглядає паралельну обчислювальну систему на деякому рівні абстракції.
– Планувальник розподіленої системи. Звичайно розподілену систему розглядають як строго неоднорідну, і тому претендування завдання на ресурс виражається вектором булевих значень R – {R1, R2,... Rn}, (де Rі – булеве значення, яке вказує, чи може i-й ресурс бути використаний для обробки даної задачі). Далі, використовуючи інформацію, отриману з моніторингу розподіленої системи, планувальник призначає завдання на відповідний вільний ресурс, відповідно до певного алгоритму.
Планувальник розподіленої системи виконує всю необхідну обробку для певного завдання до його активізації. В процес роботи задачі планувальник не втручається (крім випадків завершення примусового задачі через перевищення допустимого часу роботи).
– Пакетний планувальник кластерної системи. Кластерна система звичайно є однорідною. [11] В кластерних (мультикомп’ютерних) системах застосовують пакетні планувальники, [12] які призначають завдання на вільний ресурс за такими алгоритмами як FIFO, Backfill, Shortest Job First, за алгоритмами на основі пріоритетів, та іншими. Звичайно цільовою функцією пакетного планувальника є максимізація пропускної здатності системи (кількість виконаних задач в одиницю часу), або мінімізація часу очікування задачі.
Як і планувальник розподіленої системи, пакетний планувальник виконує обробку до активізації завдання, а в процес роботи задачі він не втручається.
– Планувальник операційної системи. Цей планувальник дозволяє виконувати кілька потоків виконання в режимі розділення часу; звичайно цей планувальник оптимізований для інтерактивних задач. В кластерних системах звичайно кожному потоку виконання виділяється окреме ядро і тому фактично режим розділення часу не використовується.
Планувальник операційної системи працює під час роботи задачі, забезпечуючи використання ядер в режимі розділення часу, якщо це необхідно. Планувальник ОС може легко перемістити потоки виконання між ядрами та процесорами в межах однієї запущеної копії ОС на одному комп’ютері. Але планувальник ОС звичайно не виконує міграцію процесів між різними комп’ютерами в кластерній системі. Міграція процесів в цілому є складною задачею, [11] розв’язання якої пов’язане з проблемою використання локальних ресурсів процесом.
– Одночасна багатопоточність. Деякі сучасні процесори [13] можуть виконувати кілька потоків на одному фізичному ядрі в режимі розділення часу, причому переключення потоків відбувається на апаратному рівні і є повністю прозорим для операційної системи. До таких процесорів відноситься, наприклад, Sun UltraSPARC Т2, який може виконувати до 8 потоків на одному фізичному ядрі. Апаратне переключення потоків є більш швидким (реалізація зміни контексту не потребує дій операційної системи) та може відбуватись не тільки за квантами часу, а й за апаратними подіями (наприклад, за кеш-промахами).
– Паралелізм рівня команд. Сучасні процесори, які використовуються у високопродуктивних системах, звичайно є суперскалярними. Суперскалярний процесор – процесор, що реалізує паралелізм на рівні команд. [1] Одне ядро суперскалярного процесора здатне виконувати декілька незалежних команд кожен такт.
З аналізу, наведеного вище, слідує, що при такому процесі обробки завдання, як наведено на рис. 1.1, ресурси (обчислювальні ядра) для задачі виділяються один раз перед запуском задачі, і звільняються всі разом після завершення виконання задачі. Задача не може звільнити деякі ядра, якщо вони стали не потрібні, або надати запит і отримати більше ядер, якщо виникла така потреба. Крім того, у вихідному стані загальний обсяг підзадач на різних обчислювальних вузлах може бути різним, що призводить до незбалансованого навантаження на вузли. Таким чином виникає задача балансування навантаження між ресурсами, що виділені задачі.
Під балансуванням навантаження в даній роботі маємо на увазі розподіл та перерозподіл навантаження (задач, підзадач) між обчислювальними ресурсами з метою вирівнювання навантаження на обчислювальні ресурси. [14] Можливі наступні способи виконання балансування навантаження: статичне балансування та динамічне. При статичному балансуванні навантаження розподіл підзадач відбувається на основі апріорної інформації про структуру задачі, оцінки часу виконання підзадач тощо. Динамічне балансування навантаження, навпаки, не потребує апріорної інформації про задачу. Найбільший інтерес представляє динамічне балансування навантаження, так як тільки динамічне балансування навантаження має більш широку сферу застосування. Наприклад, у випадках, коли апріорні оцінки часу виконання принципово неможливі, тільки динамічне балансування навантаження може бути застосоване. Такі оцінки часу можуть бути відсутні, наприклад, для нерегулярних паралельних реалізацій деяких алгоритмів.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
