
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
– примушує вибрати максимальну кількість паралельних потоків на етапі програмування;
– не дозволяє змінювати набір операцій, що виконуються паралельно, на етапі виконання;
– і, як наслідок попередніх двох недоліків, не дозволяє змінювати зернистість на етапі виконання.
В оновлений стандарт 2011 року мови С ++ включена бібліотека під назвою Futures, [29] яка дозволяє відвантажити роботу одного потоку виконання для виконання в іншому потоці виконання, та повернути обчислений результат в перший потік. Це досягається за рахунок виконання заданої функції в окремому потоці виконання, причому система підтримки часу виконання повертає в перший потік дескриптор результату, за допомогою якого перший потік може отримати результат обчислень. Взаємодія потоків при відвантаженні проілюстрована на рис. 1.6.
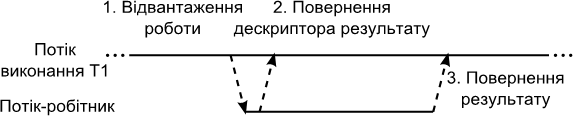
Рис. 1.6. Паралельна обробка за допомогою бібліотеки Futures в C++ 2011
Бібліотека Futures дозволяє відвантажувати роботу рекурсивно. Це дозволяє виконувати будь-які незалежні обчислення паралельно, навіть якщо наявність або відсутність незалежних обчислень визначається оброблюваними даними. Найбільш легко виражаються реалізації алгоритмів, паралельна обробка в яких має деревоподібний характер. Приклад такої обробки наведено на рис. 1.7:
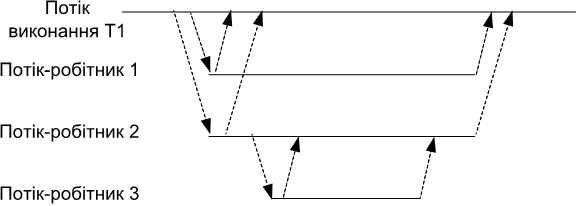
Рис. 1.7. Деревоподібна паралельна обробка за допомогою бібліотеки Futures в С++ 2011
В бібліотеці Futures створені необхідні передумови для зміни зерна паралелізму на етапі виконання. Наприклад, за умови наявності в задачі паралельної обробки за деревоподібною схемою, можна обирати, чи обробляти дочірні вузли дерева паралельно, тим самим зменшуючи зерно, чи обробляти їх послідовно, тим самим зафіксувавши розмір зерна рівним розміру поточного піддерева. Але відкритим залишається наступне питання: на основі якої інформації можна прийняти таке рішення?
Нажаль, бібліотека Futures не дозволяє автоматично змінювати зерно паралельних обчислень. Ця задача покладена на програміста. В бібліотеці відсутні будь-які засоби, що дозволяють змінювати зерно. Фактично, для динамічної зміни зерна необхідно на етапі програмування для кожної задачі знайти свій підхід.
Можливості, що надаються директивою task розширення ОреnМР 3.0 [28, 30] та розширенням Intel Cilk [27] в цілому аналогічні можливостям бібліотеки Futures. Між цими технічними рішеннями, звичайно, існує різниця, але вона не є принциповою. З однієї сторони, бібліотека Futures є частиною стандартної бібліотеки мови C++, та є більш інтегрованою з іншими нововведеннями стандарту C++ 2011 року. З іншої сторони, на відміну від Futures, що є бібліотекою, ОреnМР та Intel Cilk є розширеннями синтаксису мови, тому дозволяють більш компактний та простий запис паралельних реалізацій деяких алгоритмів. Переваги та недоліки в цілому аналогічні перевагам та недолікам бібліотеки Futures.
1.7. Модель програмування з неявним поділом задачі
Ідею накладання обмежень на спосіб створення та очікування завершення виконання потоків можна розвинути далі. Наприклад, можна взагалі заборонити явно створювати потоки виконання, а замість цього покласти обов’язок створення потоків на допоміжну бібліотеку часу виконання.
Для реалізації такого підходу необхідно, щоб програміст виділив кроки алгоритму, які можна виконувати паралельно. З іншого боку, програміст не виконує запуск потоків виконання явно, а надає інформацію про наявний паралелізм задачі бібліотеці часу виконання. Бібліотека часу виконання, отримавши повну інформацію про наявні паралельні ділянки, може визначити необхідну кількість потоків та порядок виконання цих підзадач.
Використання вищеописаної моделі програмування має наступні переваги над іншими розглянутими моделями:
– Спрощується розробка паралельної програми. Програміст тільки визначає, які кроки алгоритму можна виконувати паралельно з іншими, а запуск потоків, синхронізацію, взаємне виключення виконує бібліотека часу виконання.
– Наявна можливість зміни зерна паралелізму в процесі виконання. Так як програміст надає повну інформацію про наявний паралелізм, можна виконувати якнайбільше кроків паралельно для використання найменшого зерна, або об’єднувати деякі паралельні кроки в послідовні ділянки для збільшення зерна.
– Створені передумови для автоматичної зміни зерна паралелізму. Описане вище об’єднання паралельних кроків в послідовні ділянки може бути виконано бібліотекою часу виконання автоматично.
Бібліотека Thread Building Blocks, розроблена компанією Intel, відповідає даній моделі програмування паралельних ЕОМ. [31]
Але у навіть у такої доволі високорівневої моделі є принциповий недолік: в абстракціях даної моделі відсутнє поняття даних та відсутній жорсткий зв’язок обчислень з даними. Програміст не вказує вичерпний перелік вхідних та вихідних даних для задачі; дозволяється використовувати глобальні змінні для взаємодії між паралельними ділянками.
1.8. Транзакційна пам’ять
Одним з можливих альтернативних варіантів вирішення задачі взаємного виключення є використання транзакційної пам’яті. [32] В транзакційній моделі багато паралельних потоків виконання працюють зі спільними змінними. Будь-який потік може розпочати транзакцію, після чого може спекулятивно обчислювати нові значення для спільних змінних. Ці зміни записуються в спільну пам’ять тільки якщо транзакція завершується без конфліктів з іншими потоками виконання. Інакше, зміни до спільних змінних не вносяться, а виконання потоків відкатується до початку транзакції.
Транзакційна модель роботи зі спільними змінними має наступні переваги:
– дозволяє вирішувати задачу взаємного виключення без блокування потоків (зауважимо, що використання м’ютексів чи семафорів призводить до блокування). [33]
– в транзакційній моделі вирішення задачі взаємного виключення значно спрощується, так як для цього в паралельну програму не потрібно вводити спеціальні змінні (типу м’ютексів чи семафорів);
– в транзакційній моделі принципово неможливе виникнення тупиків. [32]
Транзакційна пам’ять – багатообіцяюча та перспективна область, але все ж на сьогоднішній день, вона залишається дослідницькою та не доступною широкому колу користувачів. До недавнього часу, існували лише програмні реалізації транзакційної пам’яті, які мали великі накладні витрати. В високопродуктивних кластерах IBM BlueGene/Q є апаратна підтримка транзакційної пам’яті з 2012 року, [34] але ці системи не доступні широкому колу користувачів. В процесорах Intel апаратна підтримка транзакційної пам’яті анонсована лише в процесорах мікроархітектури Haswell, [35] випуск яких планується в середині 2014 року.
1.9. Низькорівнева передача повідомлень
Модель низькорівневої передачі повідомлень орієнтована на паралельні ЕОМ з локальною пам’яттю, хоча немає перешкод реалізації цієї моделі на ЕОМ зі спільною пам’яттю. В даній моделі програмісту доступні операції відправки та прийому повідомлень. Потоки виконання створюються системою підтримки часу виконання, та їх кількість звичайно фіксована на весь час виконання паралельної програми.
В даній моделі звичайно доступні наступні операції для передачі повідомлень в режимі точка-точка:
– відправка повідомлення заданому потоку;
– прийом повідомлення від будь-якого потоку з заданої множини.
Часто вводять додаткові операції для колективних операцій передачі повідомлень – операцій, в яких беруть участь більше, ніж 2 потоки. Такі операції можна розділити на три великі класи:
– one-to-many (один потік розсилає однакові чи різні дані іншим);
– many-to-one (один потік приймає від інших дані);
– many-to-many (потоки обмінюються даними за певним правилом, кожен потік і відправляє, і приймає).
Колективні операції можна реалізувати очевидним способом на основі операцій передачі в режимі точка-точка, тому наявність колективних операцій не збільшує складність даної моделі. Але ці операції зустрічаються дуже часто в паралельних програмах, та для них можливі оптимізовані реалізації, тому колективні операції вказаних вище видів часто реалізовують окремо. Це дозволяє збільшити виразність вихідного коду та збільшити продуктивність паралельної програми.
Дана модель є однією з найбільш низькорівневих на паралельних ЕОМ з локальною пам’яттю, і тому вона надає програмісту максимум контролю: програмісту доступні всі примітиви, з яких можна побудувати більш високорівневі взаємодії. Тому низькорівневість можна вважати перевагою.
Нажаль, це і є основний недолік даної моделі. Розмір вихідного коду паралельних програм, написаних відповідно до цієї моделі, зазвичай значно більший, ніж код паралельних програм, що розв’язують таку ж задачу, але іншими засобами. [17] Це можна пояснити тим, що дана модель надає програмісту такі абстракції і примітиви, які відображають особливості паралельних ЕОМ з локальною пам’яттю, а не абстракції, які безпосередньо корисні при реалізації прикладного програмного забезпечення.
1.10. Модель програмування без блокувань
Для передачі даних між потоками можуть використовуватись спільні ресурси. Але одночасний доступ до спільних ресурсів є некоректним, тому виникає задача взаємного виключення при доступі до спільних ресурсів. Задача взаємного виключення звичайно вирішується за допомогою спеціальних об’єктів, таких як м’ютекси, семафори, бар’єри, умовні змінні і так далі. Ці об’єкти забезпечують блокування інших потоків від доступу до спільних змінних на той час, коли будь-який потік працює зі спільними змінними.
Але блокування потоків має свої недоліки, [36] в тому числі:
– Обмеження розширюваності системи на більшу кількість процесорів. Дійсно, блокування потоків є протилежністю до паралельного виконання. Програміст, вводячи блокування в паралельну програму, фактично вводить в неї послідовні ділянки, тим самим обмежуючи максимальний коефіцієнт прискорення відповідно до закону Амдала.
– Можливість виникнення тупиків. Сама наявність операцій блокування призводить до появи можливості тупиків. Якщо в системі б не було блокування, тупики стали б принципово неможливими.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
