


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() (i = 1, 2, …, K)
(i = 1, 2, …, K)
– середины всех интервалов или иначе:
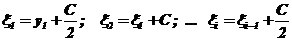 .
.
С этого момента считают, что случайная величина Х приняла в опыте не n отдельных значений xi , а К значений ![]() с соответствующими эмпирическими частотами
с соответствующими эмпирическими частотами ![]() (рис. 34а).
(рис. 34а).
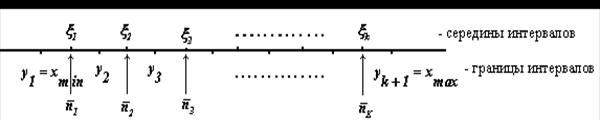 |
Число интервалов K назначается таким образом, чтобы результаты измерений в интервалах были хорошо обозримы и сами интервалы содержали достаточно большое количество сведений. Практически принимают K = 10 … 20 в зависимости от n (K = log2 n + 1).
Рис. 34а. Группировка данных
По результатам рабочей таблицы составляется статистический группированный ряд – ряд распределения случайной величины Х. При этом, в зависимости от того, что именно поставлено в соответствие новым значениям ![]() случайной величины Х, можно сформировать ряды распределения различных типов, например:
случайной величины Х, можно сформировать ряды распределения различных типов, например:
1. Тип 1 – группировка по абсолютным эмпирическим частотам
|
|
| … |
| |
|
|
| … |
|
|
2. Тип 2 – группировка по относительным эмпирическим частотам (частостям) – статистическим вероятностям ![]() , которые можно вычислить, согласно теореме Бернулли, по формуле
, которые можно вычислить, согласно теореме Бернулли, по формуле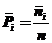 :
:
|
|
| … |
| |
|
|
| … |
|
|
При увеличении числа испытаний (наблюдений), согласно теореме Бернулли, относительная частота (частость) ![]() в каждом интервале будет сходиться по вероятности к своему теоретическому значению P.
в каждом интервале будет сходиться по вероятности к своему теоретическому значению P.
Таким образом, на этапе группировки исходная выборка значений ![]() объема n преобразуется в группированный статистический ряд значений
объема n преобразуется в группированный статистический ряд значений ![]() объема К, т. е. совершается переход от n значений случайной величины X, которые она действительно приняла в опыте, к К<< n значениям
объема К, т. е. совершается переход от n значений случайной величины X, которые она действительно приняла в опыте, к К<< n значениям ![]() и соответствующим им эмпирическим частотам
и соответствующим им эмпирическим частотам ![]() .
.
2.2.2. II этап. Построение графиков и выдвижение нулевойгипотезы о распределении
Графики дают более наглядное представление о законе распределения случайной величины. Они строятся на основе рядов распределения различных типов.
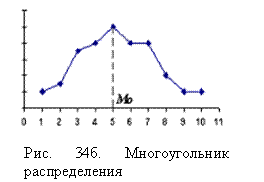
По данным ряда распределения типа 1 строится многоугольник распределения, иначе полигон частот (рис. 34б). На нем указывается значение Мо моды случайной величины.
 По данным ряда распределения типа 2 строят гистограмму (рис. 35), которая представляет собой статистическую функцию плотности вероятности случайной величины, следующим образом: над каждым интервалом строят прямоугольник площадью
По данным ряда распределения типа 2 строят гистограмму (рис. 35), которая представляет собой статистическую функцию плотности вероятности случайной величины, следующим образом: над каждым интервалом строят прямоугольник площадью ![]() , для чего вычисляют ординаты (высоты прямоугольников)
, для чего вычисляют ординаты (высоты прямоугольников) ![]() в точках
в точках ![]() , по формуле
, по формуле 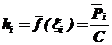 , где С – длина интервала. Таким образом, площадь всей гистограммы равна единице, так как
, где С – длина интервала. Таким образом, площадь всей гистограммы равна единице, так как ![]() . Если последовательно соединить отрезками прямой линии все ординаты
. Если последовательно соединить отрезками прямой линии все ординаты ![]() в точках
в точках ![]() , то контуры полученной линии повторяют контуры полигона частот.
, то контуры полученной линии повторяют контуры полигона частот.
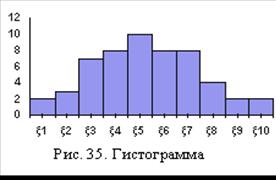 Иногда по данным ряда распределения типа 1 строят гистограмму частот. Тогда над каждым интервалом строят прямоугольник площадью
Иногда по данным ряда распределения типа 1 строят гистограмму частот. Тогда над каждым интервалом строят прямоугольник площадью ![]() , для чего вычисляют высоты прямоугольников по формуле
, для чего вычисляют высоты прямоугольников по формуле ![]() , где С – длина интервала. В этом случае площадь всей гистограммы равна
, где С – длина интервала. В этом случае площадь всей гистограммы равна ![]() , так как
, так как 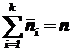 . Внешний вид гистограммы частот, как на рис.35.
. Внешний вид гистограммы частот, как на рис.35.
Всякое высказывание о генеральной совокупности, проверяемое по выборке из нее называется статистической гипотезой. Могут быть гипотезы о законе распределения случайной величины и о параметрах распределения (числовых характеристиках).
При проверке выдвигают так называемую нулевую гипотезу (проверяемую) и конкурирующую или альтернативную – противоречащую нулевой.
Так по внешнему виду гистограммы, а для нормального распределения – и по внешнему виду полигона эмпирических частот, выдвигается нулевая гипотеза ![]() о возможном конкретном законе распределения генеральной совокупности значений данной случайной величины, например:
о возможном конкретном законе распределения генеральной совокупности значений данной случайной величины, например:
![]() .
.
2.2.3. III этап. Вычисление эмпирических числовых
характеристик и выдвижение статистических гипотез о них
Эмпирические числовые характеристики – те же, что и теоретические, т. е. математическое ожидание, дисперсия, начальные и центральные моменты. Но, вычисляемые по выборке – по эмпирическим экспериментальным данным, – они являются для генеральной совокупности приближенными и называются оценками.
Статистическая оценка математического ожидания – среднее арифметическое![]() – статистическое среднее:
– статистическое среднее:
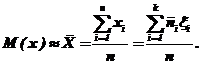 (74)
(74)
Статистическая оценка дисперсии – статистическая дисперсия ![]() :
:
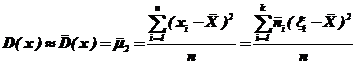 (75)
(75)
и оценка среднего квадратического отклонения
![]() . (76)
. (76)
Оценка начального момента S-го порядка – статистический начальный момент ![]() :
:
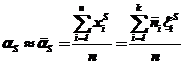 .
.
Оценка центрального момента S-го порядка – статистический центральный момент :
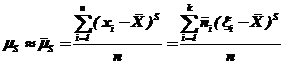 .
.
Отличие эмпирических формул от теоретических в том, что вместо математического ожидания M(x) в формулах для вычисления дисперсии D(x) и центрального момента ![]() используется его приближенное значение – оценка
используется его приближенное значение – оценка ![]() –среднее арифметическое.
–среднее арифметическое.
При увеличении n все эмпирические числовые характеристики будут сходиться по вероятности к соответствующим теоретическим числовым характеристикам и при достаточно большом n – приближенно равны им.
Вычисление эмпирических числовых характеристик выполняется в добавляемых к рабочей таблице дополнительных столбцах.
Кроме того, для всестороннего и более глубокого изучения случайной величины определяются:
1. Мода Мо случайной величины – по графику эмпирических частот или рабочей таблице.
2. Коэффициент асимметрии ![]() кривой эмпирического распределения
кривой эмпирического распределения
![]() ,
,
и выдвигается нулевая гипотеза
![]()
о равенстве нулю коэффициента асимметрии А кривой распределения генеральной совокупности.
3. Эксцесс ![]() кривой распределения
кривой распределения
![]() ,
,
и выдвигается нулевая гипотеза
![]()
о равенстве нулю эксцесса Е кривой распределения генеральной совокупности.
2.2.4. IY этап. Выравнивание статистического ряда
(расчет теоретической кривой распределения)
Задача выравнивания статистического ряда состоит в том, чтобы подобрать плавную теоретическую кривую, наилучшим образом описывающую данное эмпирическое распределение. Вид теоретической кривой f(x) выбирается по внешнему виду гистограммы или определяется, исходя из существа задачи. Далее задача выравнивания переходит в задачу выбора параметров выбранного распределения.
Выбор параметров обычно производится на основе так называемого «метода моментов», согласно которому несколько важнейших числовых характеристик теоретического распределения принимаются равными в точности соответствующим эмпирическим характеристикам, хотя на самом деле это равенство приближенное.
Например, если вид гистограммы позволяет предположить нормальное распределение опытных данных, то для расчета теоретической кривой нормального распределения
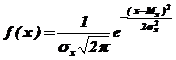 ,
,
приравнивают два момента: 1) ![]() и 2)
и 2) ![]() , т. е. принимают теоретические значения параметров нормального распределения равными в точности их оценкам, полученным по опытным данным.
, т. е. принимают теоретические значения параметров нормального распределения равными в точности их оценкам, полученным по опытным данным.
И далее, на основании принятых параметров, вычисляют теоретические вероятности ![]() попадания случайной величины во все намеченные интервалы по формуле:
попадания случайной величины во все намеченные интервалы по формуле:
![]() (77)
(77)
где ![]() ,
,
![]() – функция нормального распределения.
– функция нормального распределения.
Затем, на основании теоремы Бернулли, вычисляют теоретические частоты ![]() появления случайной величины в каждом намеченном интервале:
появления случайной величины в каждом намеченном интервале:
![]() (78)
(78)
где ![]() – объем выборки.
– объем выборки.
Далее, если выдвинута гипотеза о нормальном распределении, строят многоугольник теоретических частот, совмещая его с многоугольником эмпирических частот. Таким образом, получаем на графике эмпирическое и теоретическое распределения частот случайной величины.
В общем случае при выдвижении любой гипотезы на графике гистограммы на каждом интервале, как на основании, строят прямоугольник площадью ![]() . Высоты прямоугольника (ординаты
. Высоты прямоугольника (ординаты ![]() ) вычисляют аналогично высотам гистограммы, т. е.
) вычисляют аналогично высотам гистограммы, т. е.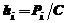 , где
, где ![]() – теоретические вероятности. Соединяя середины вершин прямоугольников, получим теоретическую плавную кривую – выравнивающую кривую плотности вероятности
– теоретические вероятности. Соединяя середины вершин прямоугольников, получим теоретическую плавную кривую – выравнивающую кривую плотности вероятности ![]() .
.
Заметим, что теперь каждому намеченному интервалу соответствуют две частоты – эмпирическая и теоретическая ![]() . При этом, как правило,
. При этом, как правило, ![]() . Графики эмпирического и теоретического распределений тоже не везде совпадают.
. Графики эмпирического и теоретического распределений тоже не везде совпадают.
Возникает вопрос: достаточно ли точно выбранная по внешнему виду гистограммы теоретическая функция распределения описывает данное эмпирическое распределение? Правдоподобна ли выбранная гипотеза о распределении случайной величины?
2.2.5. V этап. Проверка правдоподобия
статистических гипотез
При проверке нулевой гипотезы можно допустить следующие ошибки:
1) ошибка 1-го рода – когда нулевая гипотеза отвергается, хотя на самом деле она верна;
2) ошибка 2-го рода – когда нулевая гипотеза не отвергается, хотя на самом деле она неверна.
Нулевая гипотеза | Верна | Неверна |
Отвергается | Ошибка 1-го рода | Правильное решение |
Не отвергается | Правильное решение | Ошибка 2-го рода |
Проверка статистических гипотез выполняется с помощью критериев согласия. Критерий согласия – это правило (алгоритм), позволяющий либо отвергать гипотезу, либо нет.
Общий принцип проверки статистических гипотез заключается в том, что для проверки нулевой гипотезы разрабатывается специальная числовая характеристика ![]() – критерий согласия (критерий проверки гипотезы). Распределение этой числовой характеристики, как случайной величины, в условиях нулевой гипотезы должно быть известно. Оно задается таблицей, в которой помещены значения критерия
– критерий согласия (критерий проверки гипотезы). Распределение этой числовой характеристики, как случайной величины, в условиях нулевой гипотезы должно быть известно. Оно задается таблицей, в которой помещены значения критерия ![]() и соответствующие им вероятности Р.
и соответствующие им вероятности Р.
Далее по эмпирическим данным вычисляется ![]() – эмпирическое значение этого критерия и, если ему соответствует достаточно высокая вероятность Р, взятая из таблиц его теоретического распределения, то нулевая гипотеза не отвергается. В этом случае говорят, что экспериментальные данные не противоречат нулевой гипотезе.
– эмпирическое значение этого критерия и, если ему соответствует достаточно высокая вероятность Р, взятая из таблиц его теоретического распределения, то нулевая гипотеза не отвергается. В этом случае говорят, что экспериментальные данные не противоречат нулевой гипотезе.
Низкая вероятность ![]() , близкая к нулю, называется уровнем значимости. Это вероятность практически невозможного события и вероятность допустить ошибку 1-го рода.
, близкая к нулю, называется уровнем значимости. Это вероятность практически невозможного события и вероятность допустить ошибку 1-го рода.
Вероятность того, что не будет допущена ошибка 2-го рода, называется мощностью критерия.
Обычно при проверке статистических гипотез принимают q = 10%; 5%; 1%.
Практически проверку гипотез выполняют в следующем порядке:
1) вычисляют эмпирическое значение ![]() критерия согласия;
критерия согласия;
2) назначают доверительную вероятность ![]() или уровень значимости
или уровень значимости ![]() ;
;
3) из таблиц теоретического распределения критерия по ![]() (или
(или ![]() ) и некоторым другим данным выбирают
) и некоторым другим данным выбирают ![]() – теоретическое (критическое) значение критерия согласия;
– теоретическое (критическое) значение критерия согласия;
4) если ![]() , то нулевая гипотеза не отвергается. В этом случае
, то нулевая гипотеза не отвергается. В этом случае 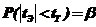 .
.
В математической статистике разработан ряд критериев для проверки различных гипотез, но следует понимать, что ни один из них не может дать 100-процентной гарантии правильного решения. Всегда остается риск допустить ошибку 1-го или 2-го рода.
Для проверки нулевой гипотезы о распределении применяется критерий согласия Пирсона (или критерий ![]() – «хи-квадрат»).
– «хи-квадрат»).
2.2.6. Критерий согласия Пирсона
Рассматривая вопрос о расхождении теоретических и эмпирических вероятностей (частостей) в интервалах, Пирсон предложил использовать величину
![]() (79)
(79)
распределение которой зависит от параметра r – числа степеней свободы, определяемого, как разность 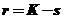 , где K – число интервалов, а s – число связей, накладываемых на расчет теоретических частот. При проверке гипотезы о нормальном распределении
, где K – число интервалов, а s – число связей, накладываемых на расчет теоретических частот. При проверке гипотезы о нормальном распределении ![]() , т. е. число связей s = 3, а именно:
, т. е. число связей s = 3, а именно:
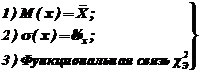 – связи при расчете нормального распределения.
– связи при расчете нормального распределения.
Критическое значение критерия проверки![]() выбирается из таблиц распределения
выбирается из таблиц распределения ![]() по числу степеней свободы r и уровню значимости q (прил. 2). Если
по числу степеней свободы r и уровню значимости q (прил. 2). Если 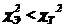 , расхождение эмпирических и теоретических частот в интервалах считается несущественным, и нулевая гипотеза о распределении не отвергается.
, расхождение эмпирических и теоретических частот в интервалах считается несущественным, и нулевая гипотеза о распределении не отвергается.
Например, ![]()
Так как 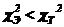 , поэтому нулевая гипотеза о распределении не отвергается.
, поэтому нулевая гипотеза о распределении не отвергается.
Если нулевая гипотеза отклоняется, то выдвигается новая нулевая гипотеза, которая проверяется в том же порядке.
Замечание. При применении критерия Пирсона требуется, чтобы количество частот в интервалах было порядка 10, иначе значение ![]() может быть необоснованно большим. В этом случае при вычислении значения
может быть необоснованно большим. В этом случае при вычислении значения ![]() объединяют некоторые соседние интервалы в один так, чтобы суммарная теоретическая частота в этом интервале была порядка 10.
объединяют некоторые соседние интервалы в один так, чтобы суммарная теоретическая частота в этом интервале была порядка 10.
2.2.7. Проверка гипотез об асимметрии и эксцессе
При проверке нулевой гипотезы
![]()
о равенстве нулю коэффициента асимметрии эмпирическим значением ![]() критерия проверки гипотезы служит абсолютная величина эмпирического коэффициента асимметрии, т. е.
критерия проверки гипотезы служит абсолютная величина эмпирического коэффициента асимметрии, т. е. ![]() . Критическое значение
. Критическое значение 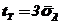 , где
, где ![]() – среднее квадратическое отклонение коэффициента асимметрии. Таким образом, если
– среднее квадратическое отклонение коэффициента асимметрии. Таким образом, если ![]() , то асимметрия считается несущественной, статистически незначимой.
, то асимметрия считается несущественной, статистически незначимой.
При проверке нулевой гипотезы
![]()
о равенстве нулю эксцесса эмпирическим значением ![]() критерия проверки гипотезы служит абсолютная величина эмпирического эксцесса, т. е.
критерия проверки гипотезы служит абсолютная величина эмпирического эксцесса, т. е. ![]() . Критическое значение
. Критическое значение ![]() , где
, где ![]() – среднее квадратическое отклонение коэффициента эксцесса. Таким образом, если
– среднее квадратическое отклонение коэффициента эксцесса. Таким образом, если ![]() , то эксцесс считается несущественным, статистически незначимым.
, то эксцесс считается несущественным, статистически незначимым.
Видим, что критические значения для проверки этих гипотез устанавливаются исходя из закона больших чисел согласно правилу «трех сигма».
Из анализа результатов проверки всех статистических гипотез принимается окончательное решение по обработке эксперимента.
2.3. Оценивание неизвестных параметров распределения
2.3.1. Общие сведения. Требования к оценкам параметров
Вычислительная операция, имеющая целью нахождение подходящих значений для параметров теоретического распределения случайной величины, называется оцениванием параметров. Математические формулы, предназначенные для оценивания параметров, называются статистиками или оценочными функциями.
Постановка задачи: Имеется случайная величина X, закон распределения которой содержит неизвестный параметр а (это может быть математическое ожидание, дисперсия и др.).
Требуется на основании опытных данных найти для этого параметра подходящую оценку, т. е. приближенное значение.
Обозначим ![]() – результаты наблюдений случайной величины X. Пусть величина , вычисленная на основании наблюденного материала, является оценкой параметра а. Это значит, что
– результаты наблюдений случайной величины X. Пусть величина , вычисленная на основании наблюденного материала, является оценкой параметра а. Это значит, что ![]() – есть функция величин
– есть функция величин
![]() ,
,
т. е. оценка ![]() – функция случайных величин, поэтому сама она так же является случайной величиной и как любая случайная величина имеет свой закон распределения, зависящий от закона распределения случайной величины X и числа опытов n.
– функция случайных величин, поэтому сама она так же является случайной величиной и как любая случайная величина имеет свой закон распределения, зависящий от закона распределения случайной величины X и числа опытов n.
В принципе, для получения оценки может быть использована любая оценочная функция (формула), но чтобы оценка параметра имела практическую ценность, она должна удовлетворять следующим требованиям.
1. Оценка параметра должна быть несмещенной, т. е. математическое ожидание оценки должно быть равно оцениваемому параметру при неограниченном увеличении числа опытов:
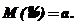 (80)
(80)
2. Оценка параметра должна быть состоятельной, т. е. сходиться по вероятности к оцениваемому параметру:
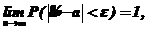 (81)
(81)
где ![]() - бесконечно малое положительное число.
- бесконечно малое положительное число.
3. Оценка параметра должна быть эффективной, т. е. ее дисперсия должна быть минимальной:
![]()
Последнее требование применяется для выбора наилучшей оценки из нескольких возможных.
Ранее мы приняли для вычисления оценки математического ожидания формулу среднего арифметического (74) и для вычисления оценки дисперсии формулу (75).
Соответствуют ли они указанным требованиям?
2.3.2. Оценка математического ожидания и ее исследование
на несмещенность и состоятельность
Условие задачи: имеем случайную величину X. ![]() – ее математическое ожидание – неизвестно;
– ее математическое ожидание – неизвестно;
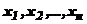 – независимые равноточные измерения случайной величины X, распределенные по тому же закону, что и сама X и
– независимые равноточные измерения случайной величины X, распределенные по тому же закону, что и сама X и ![]() , так как измеряется одна и та же величина.
, так как измеряется одна и та же величина.
Теоретически
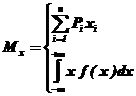
– соответственно, для дискретной и непрерывной случайных величин, но точные значения вероятностей ![]() и плотности вероятностей
и плотности вероятностей![]() нам неизвестны.
нам неизвестны.
В качестве оценки для ![]() мы приняли формулу (74) среднего арифметического
мы приняли формулу (74) среднего арифметического
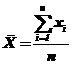 .
.
Исследуем ее на несмещенность и состоятельность.
1. При исследовании на несмещенность ответим на вопрос: ![]() ?
?
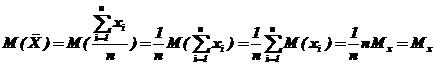 ,
,
т. е. среднее арифметическое ![]() – несмещенная оценка математического ожидания случайной величины.
– несмещенная оценка математического ожидания случайной величины.
2. При исследовании на состоятельность ответим на вопрос:
![]() ? (
? ( ![]() - бесконечно малое положительное число).
- бесконечно малое положительное число).
Согласно закону больших чисел (теорема Чебышева)
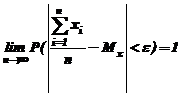 ,
,
что и означает состоятельность оценки.
Вывод: среднее арифметическое ![]() – есть несмещенная и состоятельная оценка математического ожидания случайной величины.
– есть несмещенная и состоятельная оценка математического ожидания случайной величины.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
