


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2.3.3. Оценка дисперсии и ее исследование
на состоятельность и несмещенность
Условие задачи – то же, т. е. имеем случайную величину X. ![]() – ее дисперсия – неизвестна;
– ее дисперсия – неизвестна; 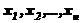 – независимые равноточные измерения случайной величины X, распределенные по тому же закону, что и X и
– независимые равноточные измерения случайной величины X, распределенные по тому же закону, что и X и ![]() , так как измеряется одна и та же величина.
, так как измеряется одна и та же величина.
Теоретически 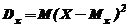 , но точное значение
, но точное значение ![]() нам неизвестно.
нам неизвестно.
В качестве оценки для дисперсии мы взяли формулу (75) центрального эмпирического момента второго порядка
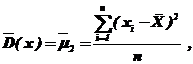
где 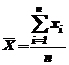 – среднее арифметическое.
– среднее арифметическое.
Исследуем ее на состоятельность и несмещенность.
1. При исследовании на состоятельность ответим на вопрос:
![]()
Преобразуем формулу для ![]() .
.
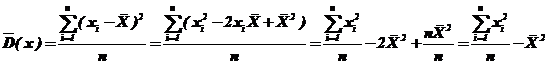 ,
,
таким образом, 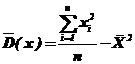 .
.
В правой части первый член сходится по вероятности при ![]() к
к ![]() – математическому ожиданию квадрата случайной величины. Второй член сходится к
– математическому ожиданию квадрата случайной величины. Второй член сходится к ![]() – квадрату математического ожидания. Это значит, что правая часть сходится по вероятности к величине
– квадрату математического ожидания. Это значит, что правая часть сходится по вероятности к величине
![]() .
.
Следовательно, оценка ![]() является состоятельной оценкой дисперсии.
является состоятельной оценкой дисперсии.
2. При исследовании на несмещенность ответим на вопрос: ![]()
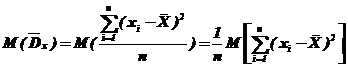 .
.
Преобразуем выражение в квадратных скобках и приведем его к виду
![]() .
.
Тогда
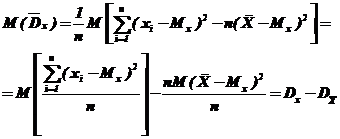 , т. е.
, т. е.
![]()
Следовательно, ![]() – смещенная оценка дисперсии, так как ее математическое ожидание не равно дисперсии
– смещенная оценка дисперсии, так как ее математическое ожидание не равно дисперсии ![]() ,а несколько меньше. Это означает, что формулу (75) нужно подправить так, чтобы она давала несмещенную оценку дисперсии.
,а несколько меньше. Это означает, что формулу (75) нужно подправить так, чтобы она давала несмещенную оценку дисперсии.
Умножим ее на ![]() и найдем математическое ожидание новой оценки:
и найдем математическое ожидание новой оценки:
![]()
Видим, что требование несмещенности оценки ![]() выполняется. Обозначим новую оценку
выполняется. Обозначим новую оценку ![]() =
= ![]() , тогда
, тогда
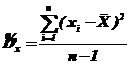 (82)
(82)
– несмещенная оценка дисперсии.
Теперь необходимо проверить новую оценку на соответствие требованию состоятельности: так как ![]() при
при ![]() , то
, то ![]() =
=![]() будет также и состоятельной оценкой дисперсии.
будет также и состоятельной оценкой дисперсии.
Отметим, что
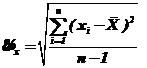 (83)
(83)
– несмещенная и состоятельная оценка среднего квадратического отклонения.
2.3.4. Интервальная оценка точности параметров
Оценки параметров, которые мы до сих пор рассматривали, называются точечными, так как они указывают на числовой оси точку, в которой находится приближенное значение неизвестного параметра.
На практике требуется не только найти для параметра а подходящее числовое значение, но и оценить его надежность, точность. Особенно это важно при малом числе наблюдений n, так как в этом случае точечная оценка ![]() параметра а в значительной мере является случайной.
параметра а в значительной мере является случайной.
Для определения точности оценки в математической статистике пользуются доверительными интервалами, а для определения ее надежности – доверительными вероятностями.
Пусть для параметра а из опыта получена несмещенная оценка ![]() . Требуется определить возможную при этом ошибку. Зададим некоторую достаточно большую вероятность
. Требуется определить возможную при этом ошибку. Зададим некоторую достаточно большую вероятность ![]() – доверительную вероятность – и найдем значение
– доверительную вероятность – и найдем значение ![]() , для которого
, для которого
![]()
или
![]() (84)
(84)
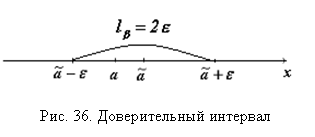 Последнее неравенство есть доверительный интервал, оно означает, что неизвестное значение параметра а с вероятностью
Последнее неравенство есть доверительный интервал, оно означает, что неизвестное значение параметра а с вероятностью ![]() попадет в интервал
попадет в интервал ![]() , где параметр а – неслучайная величина, оценка
, где параметр а – неслучайная величина, оценка ![]() – случайная величина (рис. 36). Положение интервала
– случайная величина (рис. 36). Положение интервала ![]() на числовой оси является случайным, т. к. зависит от случайного значения
на числовой оси является случайным, т. к. зависит от случайного значения ![]() – середины интервала. Длина интервала
– середины интервала. Длина интервала ![]() в общем случае также является случайной величиной.
в общем случае также является случайной величиной.
Таким образом, доверительная вероятность ![]() , соответствующая данному доверительному интервалу, есть вероятность того, что случайный интервал
, соответствующая данному доверительному интервалу, есть вероятность того, что случайный интервал ![]() , накроет неслучайную точку а на числовой оси, т. е., что истинное значение параметра а лежит внутри этого интервала с вероятностью
, накроет неслучайную точку а на числовой оси, т. е., что истинное значение параметра а лежит внутри этого интервала с вероятностью![]() . Величина
. Величина ![]() – уровень значимости.
– уровень значимости.
Значение доверительной вероятности назначается исходя из практических соображений и часто принимается равным:
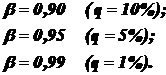
2.3.5. Доверительный интервал для математического
ожидания нормально распределенной случайной величины
Пусть случайная величина 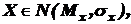 и пусть из опыта получены точечные оценки неизвестных параметров – математического ожидания и дисперсии соответственно:
и пусть из опыта получены точечные оценки неизвестных параметров – математического ожидания и дисперсии соответственно:
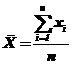 и
и 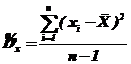 .
.
Построим доверительный интервал ![]() , соответствующий заданной доверительной вероятности
, соответствующий заданной доверительной вероятности ![]() для математического ожидания этой случайной величины.
для математического ожидания этой случайной величины.
Согласно Центральной предельной теореме закон распределения статистики ![]() близок к нормальному, так как
близок к нормальному, так как ![]() представляет собой сумму независимых одинаково распределенных величин
представляет собой сумму независимых одинаково распределенных величин ![]() . Пользуясь свойствами математического ожидания и дисперсии, выше мы показали, что:
. Пользуясь свойствами математического ожидания и дисперсии, выше мы показали, что:
1) ![]() – математическое ожидание среднего арифметического;
– математическое ожидание среднего арифметического;
2) 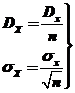 – дисперсия и среднее квадратическое отклонение среднего арифметического, т. е. статистика
– дисперсия и среднее квадратическое отклонение среднего арифметического, т. е. статистика 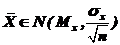 .
.
Найдем ![]() такое, для которого
такое, для которого
![]() или
или ![]() .
.
Здесь ![]() – вероятность попадания в интервал с симметричными границами относительно центра – оценки
– вероятность попадания в интервал с симметричными границами относительно центра – оценки ![]() . Ее значения, соответствующие различным значениям аргумента находятся в таблице функции Лапласа
. Ее значения, соответствующие различным значениям аргумента находятся в таблице функции Лапласа ![]() (см. табл. 1):
(см. табл. 1): ![]() .
.
Из названных таблиц по принятой доверительной вероятности![]() обратным интерполированием можно найти значение аргумента
обратным интерполированием можно найти значение аргумента ![]() , который, в свою очередь, равен
, который, в свою очередь, равен
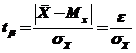 ,
,
откуда можно вычислить значение ![]() , а затем получить доверительный интервал
, а затем получить доверительный интервал 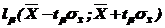 , что означает
, что означает
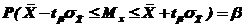 (85)
(85)
или
![]() .
.
Значение ![]() задается, как всегда, исходя из практической целесообразности.
задается, как всегда, исходя из практической целесообразности.
Формула (85) позволяет построить доверительный интервал для математического ожидания нормально распределенной случайной величины, если известно точное значение среднего квадратического отклонения ![]() . Если же оно неизвестно, а имеется лишь его оценка
. Если же оно неизвестно, а имеется лишь его оценка ![]() , которая в геодезии (и не только в геодезии) называется средней квадратической ошибкой и обозначается
, которая в геодезии (и не только в геодезии) называется средней квадратической ошибкой и обозначается ![]() или
или ![]() , то формула доверительного интервала выглядит следующим образом:
, то формула доверительного интервала выглядит следующим образом:
![]() , (86)
, (86)
где 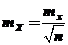 – средняя квадратическая ошибка среднего арифметического;
– средняя квадратическая ошибка среднего арифметического;
![]() – средняя квадратическая ошибка измерений случайной величины X.
– средняя квадратическая ошибка измерений случайной величины X.
При этом в формуле (86) коэффициент ![]() выбирается по вероятности
выбирается по вероятности ![]() (или уровню значимости
(или уровню значимости ![]() ) и числу степеней свободы
) и числу степеней свободы 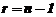 из таблиц распределения Стьюдента (прил. 3), т. е.
из таблиц распределения Стьюдента (прил. 3), т. е.
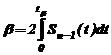 ,
,
где ![]() – плотность распределения Стьюдента с
– плотность распределения Стьюдента с ![]() степенями свободы.
степенями свободы.
Необходимо отметить, что при малых значениях n распределение статистики ![]() (среднего арифметического) имеет распределение Стьюдента (а не нормальное) и лишь при
(среднего арифметического) имеет распределение Стьюдента (а не нормальное) и лишь при ![]() является нормальным.
является нормальным.
Вывод: в случаях, когда n < 20 в формулах (85) и (86) коэффициент ![]() необходимо определять из таблиц распределения Стьюдента.
необходимо определять из таблиц распределения Стьюдента.
2.3.6. Доверительный интервал
для среднего квадратического отклонения
нормально распределенной случайной величины
По-прежнему предполагаем, что случайная величина 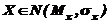 ;
; 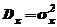 – дисперсия случайной величины X.
– дисперсия случайной величины X.
Если ![]() , то можно вычислить среднее квадратическое отклонение статистической дисперсии по формуле [3]
, то можно вычислить среднее квадратическое отклонение статистической дисперсии по формуле [3]
![]() (87)
(87)
Доверительный интервал для среднего квадратического отклонения ![]() имеет вид:
имеет вид:
![]() (88)
(88)
где ![]() .
.
Этот интервал несимметричен относительно оценки 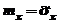 . Значения
. Значения ![]() и
и ![]() вычисляются на основе
вычисляются на основе ![]() -распределения, имеющего график плотности, несимметричный относительно математического ожидания по формулам:
-распределения, имеющего график плотности, несимметричный относительно математического ожидания по формулам:
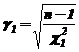 и
и 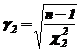 ,
,
а величины ![]() и
и ![]() выбираются из таблиц
выбираются из таблиц ![]() -распределения по вероятностям
-распределения по вероятностям 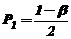 и
и 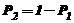 , соответственно. Отметим, что удобнее пользоваться специальными таблицами, которые по доверительной вероятности
, соответственно. Отметим, что удобнее пользоваться специальными таблицами, которые по доверительной вероятности ![]() и числу степеней свободы
и числу степеней свободы 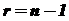 сразу дают значения
сразу дают значения ![]() и
и ![]() (прил. 2).
(прил. 2).
При необходимости можно построить доверительный интервал для ![]() – среднего квадратического отклонения статистики
– среднего квадратического отклонения статистики ![]() (среднего арифметического) аналогично:
(среднего арифметического) аналогично:
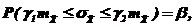 (89)
(89)
где 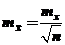 .
.
2.4. Элементы регрессионного анализа
2.4.1. Функциональная и статистическая связь
Связи между различными явлениями в природе сложны и многообразны, однако их можно определенным образом классифицировать.
Функциональная связь между переменными ![]() и
и ![]() – такая, когда каждому возможному значению
– такая, когда каждому возможному значению ![]() соответствует однозначно определенное значение
соответствует однозначно определенное значение ![]() . Функциональная связь выражается аналитически, т. е. в виде строгой формулы, например,
. Функциональная связь выражается аналитически, т. е. в виде строгой формулы, например, 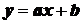 ,
, 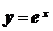 ,
, 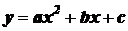 и т. п.
и т. п.
Статистическая связь между переменными ![]() и
и ![]() имеет место тогда, когда однозначность значения
имеет место тогда, когда однозначность значения ![]() теряется, и каждому возможному значению
теряется, и каждому возможному значению ![]() соответствует целый ряд возможных значений
соответствует целый ряд возможных значений ![]() , изменяющийся вместе с изменением
, изменяющийся вместе с изменением ![]() . Другими словами, каждому возможному значению
. Другими словами, каждому возможному значению ![]() соответствует распределение значений
соответствует распределение значений ![]() .
.
Статистическая (корреляционная) связь состоит в том, что одна случайная величина реагирует на изменение другой либо изменением своего закона распределения (т. е. изменением вида кривой распределения), либо изменением своего математического ожидания (среднего значения), либо изменением других числовых характеристик.
При решении широкого круга задач прежде всего необходимо знать, связаны или не связаны в принципе между собой две или более случайные величины. Например, существует ли связь между количеством выкуренных сигарет и средней продолжительностью жизни, между способностями человека, выраженными количественными показателями, и его успехами в учебе, науке.
Наличие статистической связи между двумя случайными величинами ![]() и
и ![]() , а также ее тесноту, силу, можно установить, вычислив коэффициент корреляции
, а также ее тесноту, силу, можно установить, вычислив коэффициент корреляции
![]() ,
,
который может принимать значения ![]() и является безразмерной величиной.
и является безразмерной величиной.
Коэффициент корреляции определяет степень линейной статистической зависимости между случайными величинами.
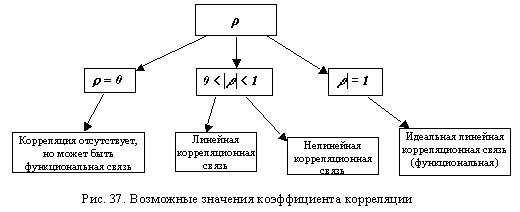 |
В зависимости от значения коэффициента корреляции будем иметь (рис. 37):
На практике вычисляется оценка коэффициента корреляции ![]() – выборочный коэффициент корреляции:
– выборочный коэффициент корреляции:
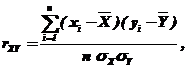 (90)
(90)
который также может принимать значения в диапазоне 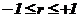 .
.
На рис. 38 представлена:
а) идеальная положительная корреляция – линейная функциональная связь;
б) идеальная отрицательная корреляция – линейная функциональная связь;
в), г) линейная корреляция с умеренным рассеянием – положительная и отрицательная соответственно;
д) нелинейная корреляция;
е) отсутствие корреляции.
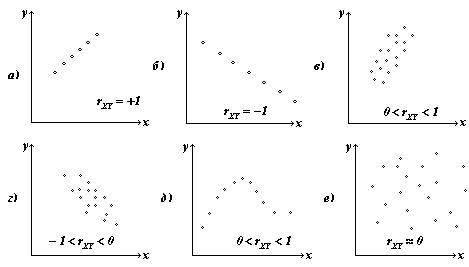
Рис. 38. Возможные формы зависимости двух случайных величин
Линейная корреляционная связь – частный случай статистической связи между переменными ![]() и
и ![]() – такая, при которой с изменением одной из них меняется математическое ожидание другой.
– такая, при которой с изменением одной из них меняется математическое ожидание другой.
При решении задач корреляционного и регрессионного анализа случайную величину ![]() называют предиктором или фактором, а случайную величину
называют предиктором или фактором, а случайную величину ![]() – откликом или результативным признаком.
– откликом или результативным признаком.
Выборочный коэффициент корреляции ![]() , являясь функцией случайных величин
, являясь функцией случайных величин ![]() и
и ![]() , изменчив. Он обладает значительной выборочной изменчивостью. Поэтому равенство нулю выборочного коэффициента корреляции
, изменчив. Он обладает значительной выборочной изменчивостью. Поэтому равенство нулю выборочного коэффициента корреляции ![]() еще не означает равенства нулю действительного коэффициента корреляции
еще не означает равенства нулю действительного коэффициента корреляции ![]() и отсутствия корреляционной связи между случайными величинами
и отсутствия корреляционной связи между случайными величинами ![]() и
и ![]() , и наоборот. Поэтому всегда нужно убеждаться в том, что отличное от нуля значение
, и наоборот. Поэтому всегда нужно убеждаться в том, что отличное от нуля значение ![]() не случайно и действительно отражает наличие статистически значимой корреляционной зависимости между исследуемыми переменными
не случайно и действительно отражает наличие статистически значимой корреляционной зависимости между исследуемыми переменными ![]() и
и ![]() .
.
2.4.2. Определение значимости выборочного коэффициента корреляции
Определить значимость ![]() означает установить, достаточна ли его величина для обоснованного вывода о наличии корреляционной зависимости между X и Y. Вопрос о значимости решается следующим образом.
означает установить, достаточна ли его величина для обоснованного вывода о наличии корреляционной зависимости между X и Y. Вопрос о значимости решается следующим образом.
1. Если ![]() , то используется критерий Романовского, согласно которому вычисляется значение
, то используется критерий Романовского, согласно которому вычисляется значение ![]() , и корреляционная связь между X и Y считается установленной, если
, и корреляционная связь между X и Y считается установленной, если ![]() . Наименьшая величина
. Наименьшая величина ![]() , удовлетворяющая этому условию, может быть вычислена в зависимости от n по формуле
, удовлетворяющая этому условию, может быть вычислена в зависимости от n по формуле ![]() .
.
2. Если ![]() , то проверяется нулевая гипотеза
, то проверяется нулевая гипотеза
![]()
– о незначимости действительного коэффициента корреляции. Критерий проверки – статистика 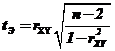 в условиях нулевой гипотезы имеет распределение Стьюдента с
в условиях нулевой гипотезы имеет распределение Стьюдента с ![]() степенями свободы. Из таблицы распределения Стьюдента по
степенями свободы. Из таблицы распределения Стьюдента по ![]() и уровню значимости
и уровню значимости ![]() , где
, где![]() – доверительная вероятность, находят критическое значение критерия
– доверительная вероятность, находят критическое значение критерия ![]() . Если
. Если ![]() , то нулевая гипотеза не отвергается на принятом уровне значимости, т. е.
, то нулевая гипотеза не отвергается на принятом уровне значимости, т. е. ![]() незначим. В этом случае
незначим. В этом случае 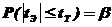 . Если
. Если ![]() , то нулевая гипотеза отвергается, т. е.
, то нулевая гипотеза отвергается, т. е. ![]() значим.
значим.
Для оценки надежности выборочного коэффициента корреляции ![]() строят доверительный интервал для
строят доверительный интервал для ![]() согласно критерия Фишера:
согласно критерия Фишера:
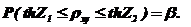 (91)
(91)
Здесь ![]() – символ гиперболического тангенса.
– символ гиперболического тангенса.
Доверительный интервал строят в следующем порядке:
а) вычисляют вспомогательную статистику Z
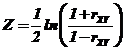 ,
,
которая имеет нормальное распределение с математическим ожиданием 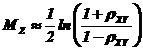 и средним квадратическим отклонением
и средним квадратическим отклонением 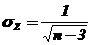 ;
;
б) вычисляют значение ![]() ;
;
в) вычисляют значения ![]() и
и ![]() :
:
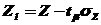 ,
, ![]() ,
,
где ![]() – аргумент функции Лапласа (
– аргумент функции Лапласа (![]() );
);
г) вычисляют значения гиперболических тангенсов ![]() и
и ![]() и записывают доверительный интервал в числовом виде.
и записывают доверительный интервал в числовом виде.
Таким образом, с вероятностью ![]() можно утверждать, что действительное значение
можно утверждать, что действительное значение ![]() коэффициента корреляции находится в интервале (
коэффициента корреляции находится в интервале (![]() ;
;![]() ).
).
Если ![]() , т. е. если доверительный интервал меньше абсолютного значения коэффициента корреляции, то наличие значимой линейной корреляционной зависимости между X и Y считается установленным, равно как, если
, т. е. если доверительный интервал меньше абсолютного значения коэффициента корреляции, то наличие значимой линейной корреляционной зависимости между X и Y считается установленным, равно как, если ![]() .
.
2.4.3. Определение формы связи. Функция регрессии.
Уравнение регрессии
Коэффициент корреляции характеризует только тесноту, силу статистической связи между переменными X и Y, но по нему нельзя судить о форме этой связи (см. рис. 38 в) и д)). Зная форму связи, можно предсказывать значение Y (отклика) в зависимости от значения X (предиктора), т. е. использовать аналитическое выражение связи X и Y для прогнозов, не проводя опытов, что очень важно.
Форма связи X и Y характеризуется так называемой функцией регрессии. Определение вида функции регрессии – основная задача регрессионного анализа.
Функцией регрессии случайной величины Y относительно X (функцией регрессии Y по X) называется условное математическое ожидание ![]() случайной величины Y, рассматриваемое как функция x, т. е.
случайной величины Y, рассматриваемое как функция x, т. е.
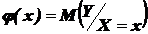 – функция регрессии Y по X;
– функция регрессии Y по X;
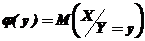 – функция регрессии X по Y.
– функция регрессии X по Y.
В зависимости от вида функции регрессии будем иметь линейную или нелинейную корреляционную связь (см. рис. 38 в) и г)).
В случае линейной корреляционной связи между X и Y функция регрессии имеет вид
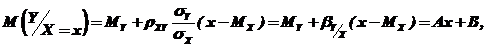 (92)
(92)
т. е. вид уравнения прямой линии.
Здесь 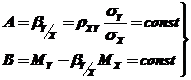 – коэффициенты функции регрессии;
– коэффициенты функции регрессии;
![]() – коэффициент корреляции.
– коэффициент корреляции.
Оценкой функции регрессии является уравнение регрессии ![]() , которое представим в виде
, которое представим в виде
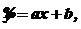 (93)
(93)
т. е. в виде обычного уравнения прямой линии.
В нем коэффициенты уравнения регрессии а и b – соответственно оценки коэффициентов A и B функции регрессии; ![]() – среднее значение случайной величины Y, зависящее от того, какое значение x приняла случайная величина X, т. е. оценка условного математического ожидания
– среднее значение случайной величины Y, зависящее от того, какое значение x приняла случайная величина X, т. е. оценка условного математического ожидания ![]() .
.
Подстановка в уравнение регрессии какого-либо значения предиктора X = x позволяет предсказать среднее значение отклика Y для этого x.
Коэффициенты уравнения регрессии a и b – параметры уравнения прямой линии. Они определяются по экспериментальным данным на основе метода наименьших квадратов (МНК), который позволяет получать несмещенные, состоятельные и эффективные оценки – наилучшие оценки параметров.
2.4.4. Определение коэффициентов уравнения регрессии
Пусть имеем из наблюдений пары ![]() значения случайных величин X и Y
значения случайных величин X и Y ![]() . Выберем в качестве предиктора X, а в качестве отклика Y.
. Выберем в качестве предиктора X, а в качестве отклика Y.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
