

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
По таблице критических точек распределения Дарбина–Уотсона для заданного уровня значимости ![]() , числа наблюдений и количества объясняющих переменных m определить два значения: dн- нижняя граница и dв - верхняя граница (таблица 7).
, числа наблюдений и количества объясняющих переменных m определить два значения: dн- нижняя граница и dв - верхняя граница (таблица 7).
Таблица 7
Статистика Дарбина–Уотсона, уровень значимости 0,05 | ||||||||||
m | 1 | 2 | 3 | 4 | 5 | |||||
| dн | dв | dн | dв | dн | dв | dн | dв | dн | dв |
20 | 1,20 | 1,41 | 1,1 | 1,54 | 1,00 | 1,67 | 0,90 | 1,83 | 0,79 | 1,99 |
21 | 1,22 | 1,42 | 1,13 | 1,54 | 1,03 | 1,66 | 0,93 | 1,81 | 0,83 | 1,96 |
22 | 1,24 | 1,43 | 1,15 | 1,54 | 1,05 | 1,66 | 0,96 | 1,80 | 0,86 | 1,94 |
23 | 1,26 | 1,44 | 1,17 | 1,54 | 1,08 | 1,66 | 0,99 | 1,79 | 0,90 | 1,92 |
24 | 1,27 | 1,45 | 1,19 | 1,55 | 1,10 | 1,66 | 1,01 | 1,78 | 0,93 | 1,90 |
25 | 1,29 | 1,45 | 1,21 | 1,55 | 1,12 | 1,66 | 1,04 | 1,77 | 0,95 | 1,89 |
В нашем случае модель содержит 2 объясняющие переменные (m=2), нижняя и верхняя границы равны соответственно dн = 1,19 и dв = 1,55.
Расчетное значение d-статистики лежит в интервале 0≤d≤dн. Следовательно, в ряду остатков существует положительная автокорреляция. ¨
Тема 3. Линейные регрессионные модели с переменной структурой.
При изучении социально-экономических процессов и явлений может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровня, например, образование, пол, фактор сезонности. Качественные признаки могут существенно влиять на структуру линейных связей между переменными и приводить к скачкообразному изменению параметров регрессионной модели. В этом случае говорят об исследовании регрессионных моделей с переменной структурой или построении регрессионных моделей по неоднородным данным.
Оценить влияние значений количественных переменных и уровней качественных признаков с помощью одного уравнения регрессии можно путем введения фиктивных переменных.
В качестве фиктивных переменных обычно используются дихотомические (бинарные) переменные, которые принимают всего два значения: «0» и «1». Например, при исследовании зависимости заработной платы от уровня образования Z можно рассмотреть k=3 уровня: начальное образование, среднее и высшее. Обычно вводят (k-1) бинарную переменную. В нашем случае потребуется ввести две фиктивные переменные.
Тогда регрессионная модель запишется в виде:
y= b0 + b1∙x1 + … + bm∙xm + bm+1∙z1 + bm+2∙z2 +ε,
где 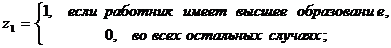
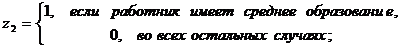
x1, …,∙xm – экономические (количественные) переменные.
Наличие у работника начального образования будет отражено парой значений z1=0, z2=0.
Параметры при фиктивных переменных z1 и z2 представляют собой разность между средним уровнем результативного признака для соответствующей группы и базовой группы (в нашем примере это работники с начальным образованием).
При построении регрессионных моделей по неоднородным данным необходимо выяснить, действительно ли две выборки однородны в регрессионном смысле, можно ли объединить их в одну и рассматривать единую модель регрессии?
Для ответа на этот вопрос можно воспользоваться тестом Г. Чоу.
По каждой выборке строятся две линейные регрессионные модели:
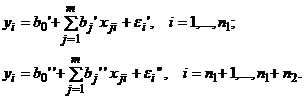
Проверяемая нулевая гипотеза имеет вид – H0: b'=b''; D(ε')= D(ε'')= σ2.
Если нулевая гипотеза верна, то две регрессионные модели можно объединить в одну объема n = n1 + n2.
Согласно критерию Г. Чоу нулевая гипотеза H0 отвергается на уровне значимости α, если статистика
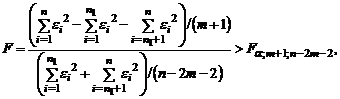
где 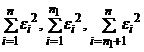 - остаточные суммы квадратов соответственно для объединенной, первой и второй выборок, n = n1 + n2.
- остаточные суммы квадратов соответственно для объединенной, первой и второй выборок, n = n1 + n2.
Для проверки гипотезы о структурной стабильности тенденции изучаемого временного ряда можно также использовать тест Д. Гуйарати.
Пример 4. Рассмотрим полученную в примере 1 модель зависимости балансовой прибыли предприятия торговли ![]() (тыс. руб.) от следующих переменных:
(тыс. руб.) от следующих переменных:
![]() - фонд оплаты труда, тыс. руб.;
- фонд оплаты труда, тыс. руб.; ![]() - объем продаж по безналичному расчету, тыс. руб.
- объем продаж по безналичному расчету, тыс. руб.
Известно, что первая выборка значений переменных объемом n1=12 получена при одних условиях, а другая, объемом n2=12, - при несколько измененных условиях.
Задание: Проверьте, адекватно ли предположение об однородности исходных данных в регрессионном смысле. Можно ли объединить две выборки в одну и рассматривать единую модель регрессии по ![]() ?
?
Решение.
Для проверки предположения об однородности исходных данных в регрессионном смысле применим тест Чоу.
В соответствии со схемой теста построим уравнения регрессии по первым n1=12 наблюдениям. Результаты представлены в таблице 8.
Таблица 8
Дисперсионный анализ | |||||
df | SS | MS | F | Значимость F | |
Регрессия | 2 | 1,02E+09 | 5,1E+08 | 11,9033 | 0,002967 |
Остаток | 9 | ESS1 = = 3,85E+08 | 4,3Е+07 | ||
Итого | 11 | 1,40E+09 |
Результаты дисперсионного анализа модели, построенной по оставшимся n2=12 наблюдениям, представлены в таблице 9.
Таблица 9
Дисперсионный анализ | |||||
df | SS | MS | F | Значимость F | |
Регрессия | 2 | 1,87Е+09 | 9,33E+08 | 57,1758 | 7,6549E-06 |
Остаток | 9 | ESS2 = = 1,47E+08 | 1,63Е+07 | ||
Итого | 11 | 2,01E+09 |
Результаты регрессионного и дисперсионного анализа модели, построенной по всем n = n1 + n2 = 24 наблюдениям, представлены в таблице 3 (ESS = 6,39Е+08):
Рассчитаем статистику F по формуле:
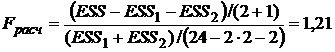 .
.
Находим табличное значение Fтабл= FРАСПОБР(0,05;3;18) = 3,15.
Так как, Fрасч< Fтабл, то справедлива гипотеза ![]() , т. е. надо использовать единую модель по всем наблюдениям. ¨
, т. е. надо использовать единую модель по всем наблюдениям. ¨
Тема 4. Нелинейные модели регрессии и их линеаризация.
Довольно часто соотношения между социально-экономическими явлениями и процессами приходится описывать нелинейными функциями. Например, производственные функции (зависимость между объемом производства и основными факторами производства) или функции спроса (зависимость между спросом на товары или услуги и их ценами или доходом).
Следует различать модели, нелинейные по параметрам, и модели, нелинейные по переменным.
Для оценки параметров нелинейных моделей существует два основных подхода:
1. Первый подход основан на линеаризации модели: преобразованием исходных переменных и введением новых, нелинейную модель можно свести к линейной, для оценки параметров которой используется метод наименьших квадратов.
2. Если подобрать соответствующее линеаризующее преобразование не удается, то применяются методы нелинейной оптимизации на основе исходных переменных.
Если модель нелинейна по переменным, то используется первый подход, т. е. вводятся новые переменные, и модель сводится к линейной:
y = ![]() + ε.
+ ε.
Переходим к новым переменным: x1'=lnx1, x2'=![]() и получаем линейное уравнение:
и получаем линейное уравнение:
y = ![]() + ε.
+ ε.
Более сложной проблемой является нелинейность по оцениваемым параметрам. В ряде случаев путем подходящих преобразований эти модели удается привести к линейному виду. Рассмотрим следующие модели, нелинейные по оцениваемым параметрам:
· степенная (мультипликативная) – ![]() ,
,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
