

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Степенная модель может быть преобразована к линейной путем логарифмирования обеих частей уравнения:
lny = ln![]() + lnε.
+ lnε.
Замена переменных: y'=lny, b0'=lnb0, x1'=lnx1, …, xm'=lnxm, ε'=lnε. В новых переменных модель запишется следующим образом:
y' = ![]() + ε'.
+ ε'.
Степенные модели получили широкое распространение в эконометрическом моделировании ввиду простой интерпретации параметров, которые представляют собой частные коэффициенты эластичности результативного признака по соответствующим факторным признакам.
· экспонента – 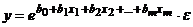 ,
,
Экспоненциальная модель линеаризуется аналогично:
lny = ![]() + lnε.
+ lnε.
Переходя к новым переменным y'=lny, ε'=lnε, получаем линейную регрессионную модель:
y' = ![]() + ε'.
+ ε'.
· гипербола –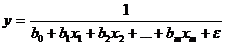 .
.
Гиперболическая модель линеаризуется непосредственной заменой переменной y'=1/y:
y' = ![]() + ε.
+ ε.
Эти функции используются при построении кривых Энгеля, которые описывают зависимость спроса на определенный вид товаров или услуг от уровня доходов потребителей или от цены товара.
· логарифмическая модель:
y = 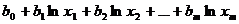 + ε.
+ ε.
При выборе формы уравнения регрессии важно помнить, что чем сложнее функция, тем менее интерпретируемы ее параметры.
В качестве примера использования линеаризующего преобразования регрессии рассмотрим производственную функцию Кобба-Дугласа:
Y = AKαLβε,
где Y – объем производства, К – затраты капитала, L – затраты труда.
Путем логарифмирования обеих частей данную степенную модель можно свести к линейной:
lnY = lnA + α·lnK + β·lnL + lnε.
Переходя к новым переменным Y'=lnY, A'=lnA, K'=lnK, L'=lnL, ε'=lnε, получаем линейную регрессионную модель:
Y' = A' + α·K' + β·L' + ε'.
Эластичность выпуска продукции.
Показатели α и β являются коэффициентами частной эластичности объема про-изводства Y соответственно по затратам капитала К и труда L. Это означает, что с увели-чением только затрат капитала (труда) на 1% объем производства возрастает на α% (β%):
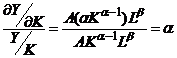 ;
;
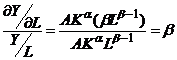 .
.
Эффект от масштаба производства.
Если α и β в сумме превышают единицу, то говорят, что функция имеет возрастающий эффект от масштаба производства (это означает, что если К и L увеличиваются в некоторой пропорции, то Y растет в большей пропорции). Если их сумма равна единице, то это говорит о постоянном эффекте от масштаба производства. Если их сумма меньше единицы, то имеет место убывающий эффект от масштаба производства. Например, К и L увеличиваются в 2 раза. Найдем новый уровень выпуска (Y*):
Y* = A(2K)α(2L)β = A2αKα2βLβ = 2α+βAKαLβ= 2α+βY.
Если α+β =1,2, то 2α+β=2,30, а Y увеличивается больше, чем в 2 раза.
Если α+β =1, то 2α+β=2, и Y увеличивается также в 2 раза.
Если α+β =0,8, то 2α+β=1,74, а Y увеличивается меньше, чем в 2 раза.
Первоначально Кобб и Дуглас представляли функцию в виде Y = AKαL1-αε,
т. е. предполагали постоянную отдачу от масштаба производства. Впоследствии это допущение было ослаблено.
Если в модели α+β =1, то функцию Кобба-Дугласа представляют в виде
Y = AKαL1-αε
или ![]() .
.
Таким образом, переходят к зависимости производительности труда (Y/L) от его капиталовооруженности (К/L). Логарифмируя обе части уравнения, приводим его к линейному виду:
ln(Y/L) = lnA + α·ln(К/L) + lnε.
Функция Кобба-Дугласа с учетом технического прогресса имеет вид:
Y = AKαLβeθtε,
где t – время, параметр θ – темп прироста объема производства благодаря техническому прогрессу.
Тема 5. Модели стационарных и нестационарных временных рядов.
Временным рядом (динамическим рядом) называется набор значений какого-либо показателя за несколько последовательных моментов или периодов времени. Отдельные наблюдения называются уровнями ряда.
В общем виде при исследовании экономических процессов временного ряда выделяются несколько составляющих:
yt = ut + vt + ct + εt (t=1, 2, …, n),
где ut – тренд, vt – сезонная компонента, ct – циклическая компонента, εt – случайная компонента.
Стационарные временные ряды.
Важное значение в анализе временных рядов имеют стационарные временные ряды, вероятностные свойства которых не изменяются во времени. Временной ряд yt (t=1, 2, …, n) называется строго стационарным, если совместное распределение вероятностей n наблюдений y1, y2,…, yn такое же, как и n наблюдений y1+τ, y2+τ,…, yn+τ при любых n, t, и τ. Таким образом, свойства строго стационарных рядов не зависят от момента времени t.
Степень тесноты связи между последовательностями наблюдений временного ряда y1, y2, …, yn и y1+τ, y2+τ, …, yn+τ можно оценить с помощью выборочного коэффициента корреляции r(τ):
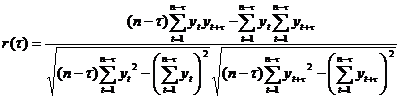 .
.
Так как он оценивает корреляцию между уровнями одного и того же ряда, его называют коэффициентом автокорреляции.
Функция r(τ) называется выборочной автокорреляционной функцией, а ее график - коррелограммой.
Кроме автокорреляционной функции при исследовании стационарных временных рядов рассматривают частную автокорреляционную функцию. Статистической оценкой частного коэффициента корреляции является выборочный частный коэффициент корреляции (или просто частный коэффициент корреляции):
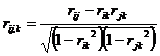 ,
,
где rij, rik rjk – выборочные коэффициенты корреляции.
Так, выборочный частный коэффициент автокорреляции 1-го порядка между членами временного ряда yt и yt+2 при устранении влияния yt+1 определяется по формуле:
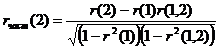 ,
,
где r(1), r(1,2), r(2) – выборочные коэффициенты автокорреляции между yt и yt+1, yt+1 и yt+2, и yt и yt+2 соответственно.
Наиболее распространенным приемом устранения автокорреляции во временных рядах является подбор соответствующей модели: авторегрессионной АР(p), скользящей средней СС(q) или авторегрегрессионной модели скользящей средней АРСС(p,q) для остатков модели (в литературе можно встретить англоязычные названия моделей: авторегрессионной – АR(p), скользящей средней – MA(q) и авторегрегрессионной модели скользящей средней АRMA(p,q).)
Идентификацией временного ряда называется построение для ряда остатков адекватной АРСС-модели, в которой остатки представляют собой белый шум, а все регрессоры значимы. Такое представление, как правило, не единственное, и один и тот же ряд может быть идентифицирован и с помощью АР-модели, и с помощью СС-модели.
Авторегрессионная модель порядка p (модель АР(p)) имеет вид:
yt = β0 + β1 yt-1+ β2 yt-2+…+ βp yt-p+εt, (t=1, 2, …, n),
где β0, β1,… βp – некоторые константы.
Если исследуемый процесс yt в момент t определяется его значениями только в преды-дущий период t-1, то получаем авторегрессионную модель 1-го порядка (или модель АР(1)).
yt = β0 + β1 yt-1 +εt, (t=1, 2, …, n),
Наряду с авторегрессионными моделями временных рядов в эконометрике рассматриваются также модели скользящей средней. В них моделируемая величина задается линейной функцией от возмущений (остатков) в предыдущие моменты времени. Модель скользящей средней порядка q (модель СС(q)) имеет вид:
yt = εt – γ1εt-1 – γ2εt-2 –…– γqεt-q (t=1, 2, …, n).
Нередко используются и комбинированные модели временных рядов АР и СС, которые имеют вид:
yt = β0 + β1 yt-1+ β2 yt-2+…+ βp yt-p+ εt – γ1εt-1 – γ2εt-2 –…– γqεt-q.
Если все значения выборочной частной автокорреляционной функции порядка выше p незначимо отличаются от нуля, временной ряд следует идентифицировать с помощью модели, порядок авторегрессии которой не выше p.
Если все значения выборочной автокорреляционной функции порядка выше q незначимо отличаются от нуля, временной ряд следует идентифицировать с помощью модели скользящей средней, порядок которой не выше q.
Нестационарные временные ряды.
Пусть имеется временной ряд
yt = ρyt-1+ ξt.
Предположим, что ошибки ξt независимы и одинаково распределены, т. е. образуют белый шум. Перейдем к разностным величинам:
Δyt = λyt-1+ ξt,
где Δyt = yt – yt-1, λ= ρ-1.
Если ряд Δyt является стационарным, то исходный нестационарный ряд yt называется интегрируемым (или однородным).
Нестационарный ряд yt называется интегрируемым (однородным) k-го порядка, если после k-кратного перехода к приращениям
dkyt = dk-1yt – dk-1yt-1,
где d1yt = Δyt, получается стационарный ряд dkyt.
Если при этом стационарный ряд dkyt корректно идентифицируется как АРСС(p,q), то нестационарный ряд yt обозначается как АРПСС(p,k,q). Это означает модель авторегрессии – проинтегрированной скользящей средней (другое обозначение - ARIMA(p,k,q)) порядков p, k, q, которая известна как модель Бокса-Дженкинса. Процедура подбора такой модели реализована во многих эконометрических пакетах.
Модели с распределенными лагами.
При исследовании экономических процессов приходится моделировать ситуации, когда значение результативного признака в текущий момент времени t формируется под воздействием ряда факторов, действовавших в прошлые моменты времени. Величину l, характеризующую запаздывание в воздействии фактора на результат, называют лагом, а временные ряды самих факторных переменных, сдвинутые на один или более моментов времени, - лаговыми переменными. Модели, содержащие не только текущие, но и лаговые значения факторных переменных, называют моделями с распределенными лагами:
В случае конечной величины максимального лага модель имеет вид:
yt = a + b0xt + b1xt-1 + … + blxt-l +εt.
Коэффициент b0 характеризует среднее абсолютное изменение yt при изменении xt на 1 ед. своего измерения в некоторый фиксированный момент времени t, без учета воздействия лаговых значений фактора x. Этот коэффициент называется краткосрочным мультипликатором.
Долгосрочный мультипликатор вычисляется по формуле:
b = b0 + b1 + … + bl.
Он показывает абсолютное изменение в долгосрочном периоде t+l результата y под влиянием изменения на 1 ед. фактора x.
Величины βj=bj/b (j = 0,…,l) называются относительными коэффициентами модели с распределенным лагом.
Средний лаг определяется по формуле средней арифметической взвешенной:
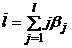
и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора в момент времени t. Небольшая величина среднего лага свидетельствует об относительно быстром реагировании результата на изменение фактора. Высокое его значение говорит о том, что воздействие фактора на результат будет сказываться в течение длительного периода времени.
Медианный лаг (lMe) – представляет собой период времени, в течение которого буде реализована половина общего воздействия фактора на результат и определяется следующим соотношением:
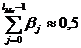 .
.
Оценка модели с распределенными лагами зависит от того, конечное или бесконечное число лагов она содержит.
Метод Алмон.
Предполагается, что веса текущих и лаговых значений объясняющих переменных подчиняются полиномиальному закону распределения:
bj = c0 + c1·j + c2·j2 + … + ck·jk. (5.1)
Уравнение регрессии примет вид:
yt = a + c0·z0 + c1·z1 + c2·z2 + … + ck·zk + εt, (5.2)
где 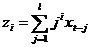 , i = 1,…,k; j=0,…,l. (5.3)
, i = 1,…,k; j=0,…,l. (5.3)
Схема расчета параметров модели:
1. устанавливается максимальная величина лага l;
2. определяется степень полинома k, описывающего структуру лага;
3. по соотношениям (5.3) рассчитываются значения переменных z0, z1,…, zk;
4. обычным методом наименьших квадратов определяются
параметры уравнения линейной регрессии yt от zi (5.2);
5. рассчитываются параметры исходной модели по формулам (5.1).
Метод Койка.
Предполагается, что коэффициенты при лаговых значениях переменной убывают в геометрической прогрессии:
![]() , j = 1, 2, … 0 < λ <
, j = 1, 2, … 0 < λ <
Уравнение регрессии преобразуется к виду:
yt = a + b0xt + b0·λ xt-1 + b0·λ2 xt-2 +… +εt.
После ряда преобразований получается уравнение авторегрессии первого порядка:
yt = a·(1 – λ) + b0·xt + (1 – λ) yt-1 + ut,
где ut = εt – λ εt-1.
Определив параметры данной модели, находятся λ и оценки параметров a и b0 исходной модели. Далее из соотношения (5.4) определяются параметры модели b1, b2,… .
Величина среднего лага в модели Койка определяется формулой:
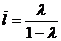 .
.
Пример 5. По данным о динамике товарооборота (Y, млрд. руб.) и доходах населения (X, млрд. руб.) была получена следующая модель с распределенными лагами:
Yt = 0,50∙Xt + 0,25∙Xt-1 + 0,13∙Xt-2 + 0,13∙Xt-3 + εt.
(0,06) (0,04) (0,04) (0,06)
В скобках указаны значения стандартных ошибок для коэффициентов регрессии. Значение R2 = 0,98.
Задание:
1. Проанализируйте полученные результаты регрессионного анализа.
2. Дайте интерпретацию параметров модели: определить краткосрочный и долгосрочный мультипликаторы.
3. Определите величину среднего лага и медианного лага.
Решение.
1. Проверка значимости отдельных коэффициентов модели дает следующие расчетные значения t-статистики для коэффициентов:
tb0 = 0,50/0,06 = 8,33; tb1 = 0,25/0,04 = 6,25;
tb2 = 0,13/0,04 = 3,25; tb3 = 0,13/0,06 = 2,17.
Таким образом, все коэффициенты оказываются значимыми, и выбор величины лага l=3 является оправданным. Об адекватности полученной модели свидетельствует и высокое значение коэффициента детерминации.
2. Краткосрочный мультипликатор в модели равен b0 = 0,50. Он показывает, что увеличение доходов на 1 млрд. руб. ведет в среднем к росту товарооборота на 0,5 млрд. руб. в том же периоде.
Долгосрочный мультипликатор для полученной модели составит:
b = b0 + b1 + b2 + b3 = 0,50 + 0,25 + 0,13 + 0,13 = 1,01.
Получаем, что увеличение доходов на 1 млрд. руб. в настоящий момент времени в долгосрочной перспективе (через 3 месяца) приведет к росту товарооборота на 1,01 млрд. руб.
Рассчитаем относительные коэффициенты модели:
β0 = 0,50/1,01 = 0,495; β1 = 0,25/1,01 = 0,248;
β2 = 0,13/1,01 = 0,129; β3 = 0,13/1,01 = 0,129.
Следовательно, 49,5% общего увеличения товарооборота, вызванного ростом доходов населения, происходит в текущий момент времени; 24,8% - в момент времени (t+1); 12,9% - в моменты времени (t+2) и (t+3).
3. Средний лаг в модели определяется следующим образом:
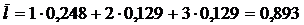 .
.
Величина среднего лага меньше месяца, что подтверждает, что эффект роста доходов населения на объем товарооборота проявляется сразу же.
Медианный лаг для данной модели составляет чуть более 1 месяца. ¨
Тема 6. Прогнозирование, основанное на использовании моделей временных рядов.
Характерной чертой адаптивных методов прогнозирования является их способность непрерывно учитывать эволюцию динамических характеристик изучаемых процессов, «адаптироваться» к этой эволюции, придавая тем больший вес, тем более высокую информационную ценность имеющимся наблюдениям, чем ближе они к текущему моменту прогнозирования.
В основе процедуры адаптации лежит метод проб и ошибок. По модели делается прогноз на один интервал по времени. Через один шаг моделирования анализируется результат: насколько он далек от фактического значения. Затем в соответствии с моделью происходит корректировка. После этого процесс повторяется. Таким образом, адаптация осуществляется рекуррентно с получением каждой новой фактической точки ряда.
Методы экспоненциального сглаживания. Модель Брауна.
Пусть анализируемый временной ряд x(t) представлен в виде:
x(t) = a0 + ε(t),
где a0 – неизвестный параметр, не зависящий от времени, ε(t) - случайный остаток со средним значением, равным нулю, и конечной дисперсией.
В соответствии с методом Брауна прогноз x*(t+τ) для неизвестного значения x(t+τ) по известной до момента времени t траектории ряда x(t) строится по формуле:
x*(t; τ) = S(t),
где значение экспоненциально взвешенной скользящей средней S(t) определяется по рекуррентной формуле:
S(t)= αx(t) + (1-α) S(t-1).
Коэффициент сглаживания α можно интерпретировать как коэффициент дисконтирования, характеризующий меру обесценивания информации за единицу времени. Из формулы следует, что экспоненциально взвешенная скользящая средняя является взвешенной суммой всех уровней ряда x(t), причем веса уменьшаются экспоненциально по мере удаления в прошлое.
В качестве S(0) берется, как правило, среднее значение ряда динамики или среднее значение нескольких начальных уровней ряда.
Случай линейного тренда: x(t) = a0 + a1t + ε(t).
В этом случае прогноз x*(t; τ) будущего значения определяется соотношением:
x*(t; τ) = ,
а пересчет коэффициентов осуществляется по формулам:
Начальные значения коэффициентов берутся из оценки тренда линейной функцией.
Модель Хольта.
В модели Хольта введено два параметра сглаживания α1 и α 2 (0< α 1, α 2 <1). Прогноз x*(t;l) на l шагов по времени определяется формулой:
x*(t; τ) = ,
а пересчет коэффициентов осуществляется по формулам:
Модель Хольта-Уинтерса.
Эта модель помимо линейного тренда учитывает и сезонную составляющую. Прогноз x*(t;τ) на τ шагов по времени определяется формулой:
x*(t;τ) = ,
где f(t) – коэффициент сезонности, а T – число временных тактов (фаз), содержащихся в полном сезонном цикле.
Видно, что в данной модели сезонность представлена мультипликативно. Формулы обновления коэффициентов имеют вид:
Модель Тейла-Вейджа.
Если исследуемый временной ряд имеет экспоненциальную тенденцию с мульти-пликативной сезонностью, то после логарифмирования обеих частей уравнения получается модель с линейной тенденцией и аддитивной сезонностью или модель Тейла-Вейджа.
Имеется модель:
x(t) = a0(t) + g(t) + δ(t),
a0(t) = a0(t-1) + a1(t).
Здесь a0(t) – уровень процесса после устранения сезонных колебаний, a1(t) – аддитивный коэффициент роста, ω(t) – аддитивный коэффициент сезонности и δ(t) – белый шум.
Прогноз x*(t;τ) на τ шагов по времени определяется формулой:
x*(t;τ) = .
Коэффициенты вычисляются рекуррентным способом по формулам:
Для определения оптимальных значений параметров адаптации перебирают различные наборы их значений и сравнивают получающиеся при этом среднеквадратические ошибки прогнозов.
Тема 7. Системы линейных одновременных уравнений.
Нередко при моделировании реальных экономических объектов для объяснения механизма их функционирования приходится строить систему уравнений, состоящую из тождеств и регрессионных уравнений. Система уравнений в эконометрических исследованиях может быть построена по-разному.
Возможна система независимых уравнений, когда каждая зависимая переменная (y) рассматривается как функция одного и того же набора объясняющих факторов (x1, х2,…,хm):
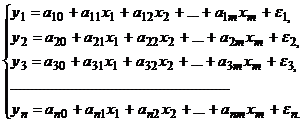
Каждое уравнение такой системы может рассматриваться самостоятельно, а для нахождения его параметров применяется метод наименьших квадратов.
Если зависимая переменная y одного уравнения выступает в виде фактора x в другом уравнении, то можно построить модель в виде системы рекурсивных уравнений:
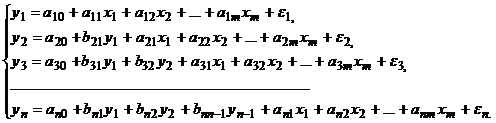
Каждое уравнение такой системы также может рассматриваться самостоятельно, а его параметры оцениваются методом наименьших квадратов.
В системе линейных одновременных уравнений одни и те же переменные (y) одновременно рассматриваются как зависимые в одних уравнениях и независимые в других. Такая система уравнений называется структурной формой модели. Каждое уравнение в системе одновременных уравнений не может рассматриваться самостоятельно, поэтому метод наименьших квадратов для оценки параметров неприменим.
В общем случае структурная форма модели имеет вид:
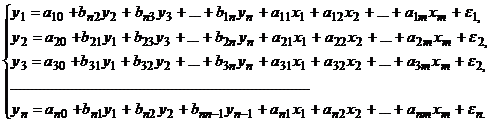
Зависимые переменные, число которых равно числу уравнений в системе, называются эндогенными переменными и обозначаются y.
Предопределенные переменные, влияющие на эндогенные переменные, но не зависящие от них, называются экзогенными переменными и обозначаются x.
Примером системы одновременных уравнений является модель спроса и предложения, когда объем спроса на товар (Qd) определяется его ценой (P) и доходом потребителя (I), объем предложения (Qs) – его ценой (P) и достигается равновесие между спросом и предложением:
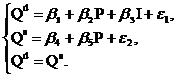
Переменные Qd, Qs, и P формируют свои значения внутри модели, согласно уравнениям системы, и таким образом, являются эндогенными переменными. Переменная I полагается заданной, ее значения формируются вне модели, и она является экзогенной.
Использование МНК для оценивания структурных коэффициентов модели дает смещенные и несостоятельные оценки. Поэтому для определения структурных коэффициентов модель преобразуется в приведенную форму модели.
Приведенная форма модели представляет систему линейных функций эндогенных переменных от экзогенных:
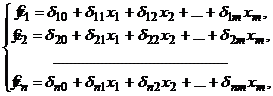
где δij – коэффициенты приведенной формы модели.
При переходе от приведенной формы модели к структурной приходится сталкиваться с проблемой идентифицируемости модели. Идентифицируемость – это единственность соответствия между приведенной и структурной формами модели.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
· идентифицируемые;
· неидентифицируемые;
· сверхидентифицируемые.
Модель идентифицируема, если все ее структурные коэффициенты определяются однозначно, единственным образом, по коэффициентам приведенной формы модели, т. е. число параметров структурной модели равно числу параметров приведенной формы модели.
Модель неидентифицируема, если число приведенных коэффициентов меньше числа структурных коэффициентов, и в результате структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели.
Модель сверхидентифицируема, если число приведенных коэффициентов больше числа структурных коэффициентов. В этом случае на основе коэффициентов приведенной формы можно получить два и более значений одного структурного коэффициента.
Необходимое условие идентифицируемости:
D + 1 = H – уравнение идентифицируемо;
D + 1 < H – уравнение неидентифицируемо;
D + 1 > H – уравнение сверхидентифицируемо,
где H – число эндогенных переменных в уравнении, D – число экзогенных переменных, которые содержатся в системе, но не входят в данное уравнение.
Достаточное условие идентифицируемости:
Уравнение идентифицируемо, если по отсутствующим в нем переменным можно из коэффициентов при них в других уравнениях системы получить матрицу, определитель которой не равен нулю, а ранг матрицы не меньше, чем число эндогенных переменных в системе без единицы.
Модель считается идентифицируемой, если каждое уравнение системы идентифицируемо. Если хотя бы одно из уравнений неидентифицируемо, то и вся модель считается неидентифицируемой.
Рассмотрим ряд модификаций модели спроса-предложения.
1. Модель спроса-предложения с учетом тренда.
Если предположить изменение спроса со временем, то в первое уравнение системы необходимо добавить временной тренд:
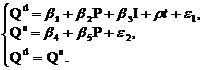
Приведенная форма модели запишется в виде:
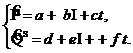
Исходная система не оказывается идентифицируемой, поскольку параметр β5 является сверхидентифицируемым. Чтобы это показать, запишем систему в следующем виде:
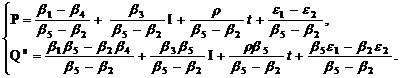
Сравнивая две записи приведенной формы, легко заметить, что оценку β5. можно получить двумя способами: как e/b и f/c.
2. Модель спроса-предложения с учетом налога.
Предположим, что продавцы товаров облагаются специальным налогом T. Величина налога меняется со временем и представлена временным рядом. Тогда система уравнений запишется следующим образом:
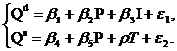
В данном случае система является идентифицируемой, но если теперь предположить, что доход I на протяжении длительного времени является постоянной величиной, то в уравнении спроса переменную I следует исключить.
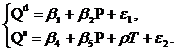
Данная система уравнений уже не является идентифицируемой. Получить идентифицируемое уравнение формирования предложения можно, наложив ограничение на структурные коэффициенты: β5 = -ρ. Смысл этого ограничения в том, что мы полагаем, что продавцы исходят из суммы, которую они получают после уплаты налога, т. е. Р* = Р - Т.
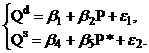
Пример 6. Структурная форма модели имеет вид:
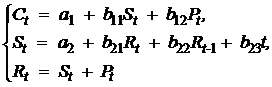
где: Сt – личное потребление в период t,
St – зарплата в период t,
Pt – прибыль в период t,
Rt – общий доход в период t,
Rt-1 – общий доход в период t-1,
Задание:
1. Проверьте каждое уравнение модели на идентифицируемость, применив необходимое и достаточное условия идентифицируемости.
2. Запишите приведенную форму модели.
Решение.
Модель представляет собой систему одновременных уравнений, состоящую из двух уравнений, которые необходимо проверить на идентифицируемость для определения способа оценки параметров, и тождества, параметры которого известны, поэтому необходимости в проверке его на идентифицируемость нет.
Модель включает три эндогенные переменные (Ct, St, Rt) и три экзогенные переменные (Pt, t, в том числе одну лаговую переменную Rt-1).
Проверим уравнения модели на идентифицируемость.
1 уравнение.
Проверим выполнение необходимого условия идентифицируемости. Это уравнение включает две эндогенные переменные (Ct ,St) и одну экзогенную переменную (Pt). Таким образом, H = 2; число экзогенных переменных системы, не входящих в это уравнение, также равно двум D = 2. Получаем: D + 1 > H, следовательно, первое уравнение сверхидентифицируемо.
Теперь проверим достаточное условие идентифицируемости.
Запишем матрицу коэффициентов при переменных (эндогенных и экзогенных), не входящих в первое уравнение (Rt, Rt-1, t):
Номер уравнения | Rt | Rt-1 | t |
2 | b21 | b22 | b23 |
3 | -1 | 0 | 0 |
Ее ранг равен 2, так как определитель квадратной подматрицы 2х2 этой матрицы не равен нулю:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
