

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
|
Замечания о сходимости.
Подчеркнем, что приведенная теорема не гарантирует сходимости метода, но лишь его условную сходимость, причем, локальную. Например, для функции f(x) = (1 + x2)–1 на R последовательность {xn} градиентного метода с постоянным шагом, начинающаяся с произвольного x0 стремится к ∞.
Поскольку в приведенной теореме градиент непрерывен, любая предельная точка последовательности {xn} является стационарной. Однако эта точка вовсе не обязана быть точкой минимума, даже локального. Например, рассмотрим для функции f(x) = x2sign x градиентный метод с шагом α ![]() (0, 1/2). Тогда, как легко видеть, если x0 > 0, то xn → 0 при n → ∞. Точка же x = 0 не является локальным минимумом функции f.
(0, 1/2). Тогда, как легко видеть, если x0 > 0, то xn → 0 при n → ∞. Точка же x = 0 не является локальным минимумом функции f.
Заметим также, что описанный метод не различает точек локального и глобального минимумов. Поэтому для того, чтобы сделать заключение о сходимости xn к точке x* = argmin f(x) приходится налагать дополнительные ограничения, гарантирующие, в частности, существование и единственность решения задачи (1). Один вариант таких ограничений описывается ниже.
Теорема о линейной сходимости градиентного метода с постоянным шагом.
Пусть выполнены условия предыдущей теоремы и, кроме того, f дважды непрерывно дифференцируема и сильно выпукла с константой λ. Тогда при α ![]() (0, 2/Λ) градиентный метод с шагом α сходится со скоростью геометрической прогрессии со знаменателем q = max{|1 – αλ|, |1 – αΛ |}:
(0, 2/Λ) градиентный метод с шагом α сходится со скоростью геометрической прогрессии со знаменателем q = max{|1 – αλ|, |1 – αΛ |}:
||xn – x*|| ≤ qn||x0 – x*||. |
Д о к а з а т е л ь с т в о. Решение x* = argmin f(x) существует и единственно в силу известных теорем. Для функции F(x) = f ′(x) воспользуемся аналогом формулы Ньютона — Лейбница
|
или, для x = x* и y = xn, учитывая, что f ′(x*) = Θ,
| (6) |
Далее, в силу известного утверждения f ′′(x) ≤ Λ при всех x ![]() Rm. Кроме того, по условию f ′′(x) ≥ λ при тех же x. Поэтому, так как
Rm. Кроме того, по условию f ′′(x) ≥ λ при тех же x. Поэтому, так как
λ||h||2 ≤ (f ′′[x* + s(xn –x*)]h, h) ≤ Λ ||h||2, |
выполнено неравенство
| (7) |
Интеграл, стоящий в этом неравенстве, определяет линейный (симметричный в силу симметричности f) оператор на Rm, обозначим его Ln. Неравенство (7) означает, что λ ≤ Ln ≤ Λ. В силу (6) градиентный метод записывается в виде
xn+1 = xn – αLn(xn – x*). |
Но тогда
||xn+1–xn||=||xn–x*–αLn(xn–x*)||= |
Спектр σ(I – αLn) оператора I – αLn состоит из чисел вида σi = 1 –αλi, где λi ![]() σ(Ln). В силу (7) и известного неравенства,
σ(Ln). В силу (7) и известного неравенства,
1 – αλ ≥ σi ≥ 1 – αΛ, |
и следовательно
||I – αLn|| ≤ max{|1 –αλ|, |1 – αΛ |} = q. |
Таким образом,
||xn+1 – xn|| ≤ q||xn – x*||. |
Из этого неравенства вытекает утверждение теоремы.
Об оптимальном выборе шага.
Константа q, фигурирующая в предыдущей теореме и характеризующая скорость сходимости метода, зависит от шага α. Нетрудно видеть, что величина
q = q(α) = max{|1 – αλ|, |1 – αΛ |} |
минимальна, если шаг α выбирается из условия |1 – αλ| = |1 – αΛ | (см. рис. 3), т. е. если α = α* = 2/(λ+ Λ). При таком выборе шага оценка сходимости будет наилучшей и будет характеризоваться величиной
|
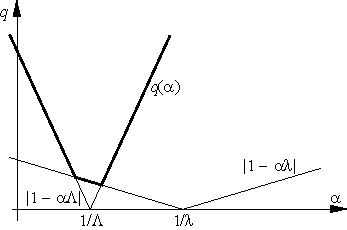
Рис. 3.
Напомним, что в качестве λ и Λ могут выступать равномерные по x оценки сверху и снизу собственных значений оператора f ′′(x). Если λ << Λ, то q* ≈ 1 и метод сходится очень медленно. Геометрически случай λ << Λ соответствует функциям с сильно вытянутыми линиями уровня (см. рис. 4). Простейшим примером такой функции может служить функция на R2, задаваемая формулой
f(x1, x2) = λx21+ Λ x22с λ << Λ. |
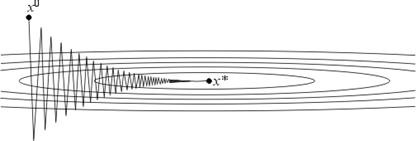
Рис. 4.
Поведение итераций градиентного метода для этой функции изображено на рис. 4 — они, быстро спустившись на "дно оврага", затем медленно "зигзагообразно" приближаются к точке минимума. Число μ = Λ/λ (характеризующее, грубо говоря, разброс собственных значений оператора f ′′(x)) называют числом обусловленности функции f. Если μ >> 1, то функции называют плохо обусловленными или овражными. Для таких функций градиентный метод сходится медленно.
Но даже для хорошо обусловленных функций проблема выбора шага нетривиальна в силу отсутствия априорной информации о минимизируемой функции. Если шаг выбирается малым (чтобы гарантировать сходимость), то метод сходится медленно. Увеличение же шага (с целью ускорения сходимости) может привести к расходимости метода. Мы опишем сейчас два алгоритма автоматического выбора шага, позволяющие частично обойти указанные трудности.
4.6. Градиентный метод с дроблением шага.
В этом варианте градиентного метода величина шага αn на каждой итерации выбирается из условия выполнения неравенства
f(xn+1) = f(xn – αnf ′(xn)) ≤ f(xn) – εαn||f ′(xn)||2, | (8) |
где ε ![]() (0, 1) — некоторая заранее выбранная константа. Условие (8) гарантирует (если, конечно, такие αn удастся найти), что получающаяся последовательность будет релаксационной. Процедуру нахождения такого αn обычно оформляют так. Выбирается число δ
(0, 1) — некоторая заранее выбранная константа. Условие (8) гарантирует (если, конечно, такие αn удастся найти), что получающаяся последовательность будет релаксационной. Процедуру нахождения такого αn обычно оформляют так. Выбирается число δ![]() (0, 1) и некоторый начальный шаг α0. Теперь для каждого n полагают αn = α0 и делают шаг градиентного метода. Если с таким αn условие (8) выполняется, то переходят к следующему n. Если же (8) не выполняется, то умножают αn на δ ("дробят шаг") и повторяют эту процедуру до тех пор пока неравенство (6) не будет выполняться. В условиях вышеприведенной теоремы эта процедура для каждого n за конечное число шагов приводит к нужному αn.
(0, 1) и некоторый начальный шаг α0. Теперь для каждого n полагают αn = α0 и делают шаг градиентного метода. Если с таким αn условие (8) выполняется, то переходят к следующему n. Если же (8) не выполняется, то умножают αn на δ ("дробят шаг") и повторяют эту процедуру до тех пор пока неравенство (6) не будет выполняться. В условиях вышеприведенной теоремы эта процедура для каждого n за конечное число шагов приводит к нужному αn.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
