

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
где hk — случайный равномерно распределенный на единичной сфере вектор, α>0 — фиксированная длина пробного шага. Метод может быть записан в виде
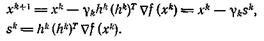
Используя результат упражнения 1, получаем
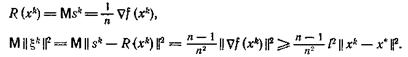
Из теоремы 2 следует, что при любом способе выбора γk метод случайного поиска не может сходиться быстрее, чем геометрическая прогрессия со знаменателем
![]() (14)
(14)
В частности, для ![]() метод случайного поиска
метод случайного поиска
сходится не быстрее прогрессии со знаменателем (п—1)/n.
Теорему 2 можно несколько уточнить для случая, когда R(х) линейна, а для помехи известна оценка снизу не только для дисперсии, но и для матрицы ковариаций. Pасматривается метод
![]() (15)
(15)
где ξk независимы, х0 случайный вектор, A-1 существует и
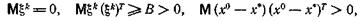 (16)
(16)
a Гk — детерминированные матрицы n×n.
Теорема 3. В методе (15) при любых Гk справедлива оценка
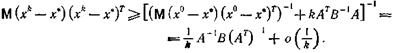
В качестве приложения рассмотрим обобщение градиентного метода минимизации квадратичной функции
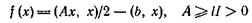
при наличии помех:
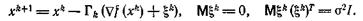 (18)
(18)
Применяя теорему 3, получаем, что при любых Гk
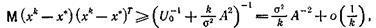 (19)
(19)
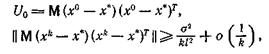 (20)
(20)
причем равенство в (19), (20) достигается при
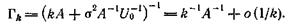 (21)
(21)
Сопоставляя (20) с оценкой (13) п. 9.2 для градиентного метода, получаем, что при данных условиях выбор γk= 1/kl в градиентном методе является асимптотически оптимальным.
2. Оптимальные алгоритмы. До сих пор мы ограничивались довольно узким классом алгоритмов — линейными рекуррентными. Однако вопрос об оптимальности можно решать для гораздо более общего класса процедур. В ряде случаев можно установить потенциальные возможности любых (не обязательно рекуррентных или линейных) методов минимизации при наличии случайных помех. Основным инструментом здесь является известное в статистике неравенство Крамера — Рао (информационное неравенство).
Пусть функция f(x) квадратична:
![]() (22)
(22)
а ее градиент вычисляется со случайной помехой ξ. Предположим, что помехи ξ независимы и одинаково распределены (раньше мы такого предположения не делали). Пусть уже вычислены значения 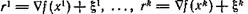 в некоторых точках х1,..., xk. Наконец, пусть матрицы А и А-1 известны. Тогда
в некоторых точках х1,..., xk. Наконец, пусть матрицы А и А-1 известны. Тогда
![]() Обозначим
Обозначим![]()
![]() Тогда
Тогда![]() Величины zi известны (так как хi, ri и А-1 известны), а величины ηi независимы и одинаково распределены (ибо такими являются ξi). Таким образом, задача свелась к следующей. Заданы векторы zi = х*+ ηi, где ηi — реализации независимой, одинаково распределенной случайной величины. Требуется по ним оценить х*.
Величины zi известны (так как хi, ri и А-1 известны), а величины ηi независимы и одинаково распределены (ибо такими являются ξi). Таким образом, задача свелась к следующей. Заданы векторы zi = х*+ ηi, где ηi — реализации независимой, одинаково распределенной случайной величины. Требуется по ним оценить х*.
Это — классическая задача оценки параметров, рассматриваемая в статистике. Для нее справедливо неравенство Крамера — Рао, утверждающее, что если ηi имеют плотность рη(z), эта плотность регулярна (т. е. справедливо равенство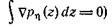 и существует фишеровская информационная матрица
и существует фишеровская информационная матрица
![]() (23)
(23)
то для любой несмещенной оценки ![]() k вектора х* по измерениям zi, i = 1, ..., k, имеет место неравенство
k вектора х* по измерениям zi, i = 1, ..., k, имеет место неравенство
![]() (24)
(24)
Иными словами, существует нижняя граница точности произвольных несмещенных оценок. Используя (24), приходим к следующему результату.
Теорема 4. Пусть помехи ξi имеют плотность р(z), причем p(z) регулярна и
существует, 0 < J< ∞. Тогда для любой несмещенной оценки ![]() k точки минимума х* функции (22), построенной по измерениям
k точки минимума х* функции (22), построенной по измерениям ![]() в k точках, справедливо неравенство
в k точках, справедливо неравенство
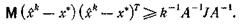 (25)
(25)
Важно, что сюда не входят точки измерения х1, ..., xk. Таким образом, при любом способе выбора k точек измерения градиента нельзя найти минимум с точностью, большей чем задаваемая неравенством (25).
Остается построить метод, для которого указанная нижняя граница достигается. Если ограничиться линейными алгоритмами
![]() (26)
(26)
где Н > 0 — некоторая матрица, то получаем, что асимптотически оптимальный выбор γk и Н таков:
![]() (27)
(27)
при этом
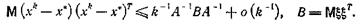 (28)
(28)
Oтсюда получаем, что если ξi распределены нормально, то правая часть (25) совпадает с правой частью (28). Таким образом, для случая нормальных помех алгоритм (26), (27) является асимптотически оптимальным (не только среди линейных или рекуррентных алгоритмов). Для других распределений помехи алгоритм (26), (27), вообще говоря, не оптимален. Более того, можно показать, что правая часть (25) строго меньше правой части (28) для любого распределения, отличного от нормального. В этом случае оптимальный алгоритм можно получить, введя нелинейность в итерационный процесс
![]() (29)
(29)
где функция![]() и γk выбираются следующим образом:
и γk выбираются следующим образом:
![]() (30)
(30)
Для нормальных помех метод (29), (30) переходит в (26), (27).
Можно показать, что при определенных условиях на p(z) распределение величины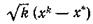 для метода (29), (30)
для метода (29), (30)
стремится к нормальному со средним 0 и матрицей ковариаций А-1JА-1. Сопоставляя это с правой частью (25), получаем, что метод (29), (30) является асимптотически оптимальным.
Практическая реализация метода (29), (30) затруднительна, так как в нем нужно знать матрицу А-1, а также плотность распределения помехи. Мы не будем останавливаться на способах преодоления этих трудностей. Здесь более важен принципиальный факт — возможность построения асимптотически оптимального алгоритма решения задачи минимизации при наличии случайных помех, причем этот алгоритм оказывается рекуррентным.
Подчеркнем еще, что все выводы здесь носили асимптотический характер. Оптимальный алгоритм для конечных k в случае нормальных помех дается выражением (21). Видно, что на начальных шагах 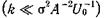 Гk примерно постоянно: Гk ≈σ2U0A, а для больших k Гk убывает как k-1:
Гk примерно постоянно: Гk ≈σ2U0A, а для больших k Гk убывает как k-1: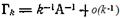 .
.
Отметим также, что оптимальные алгоритмы предполагают точное знание закона распределения помехи и неустойчивы к отклонению истинного распределения от предполагаемого. Существуют способы преодоления этой трудности (так называемые робастные алгоритмы минимизации).
9.6. Псевдоградиентный метод с возмущением на входе для нестационарной задачи безусловной оптимизации
Проблема оптимизации того или иного функционала встает во многих практических приложениях. Хотя иногда экстремальные значения можно найти аналитически, зачастую инженерные системы имеют дело с неизвестным функционалом, значение которого или его градиента можно вычислять в задаваемых точках. Также встречаются задачи, в которых оптимизируемый функционал может изменяться во времени и сама точка экстремума может дрейфовать. В таком случае постановки задачи могут отличаться в зависимости от цели оптимизации и информации доступной для измерения. Обычно рассматривают два варианта поведения дрейфа функции: когда есть некоторый асимптотический функционал, к которому другие сходятся со временем или когда такого функционала нет. Мы рассмотрим более сложный второй случай.
Задачи оптимизации можно рассматривать в постановках с дискретным и непрерывным временем. Здесь мы ограничимся рассмотрением моделей первого типа. Пусть f(x,n) - функционал, который необходимо минимизировать в момент времени п (п ![]() N). для решения подобных проблем детально рассматривал методы Ньютона и градиентный, которые применимы в случае дважды дифференцируемого функционала при условии l <
N). для решения подобных проблем детально рассматривал методы Ньютона и градиентный, которые применимы в случае дважды дифференцируемого функционала при условии l < ![]() 2fk(x) < L. Оба метода полагаются на возможность прямого измерения градиента функционала в произвольной точке
2fk(x) < L. Оба метода полагаются на возможность прямого измерения градиента функционала в произвольной точке

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
