

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() (29)
(29)
для всех x ![]() Rn и λ≥0.
Rn и λ≥0.
Ниже приведены примеры однородных функций.
1. Аффинная функция f(x) = (а, х)— β однородна с γ = 1 для любого х*.
2. Квадратичная функция ![]() где А-1 существует, является однородна относительно х* = А-1b с γ = 2.
где А-1 существует, является однородна относительно х* = А-1b с γ = 2.
3. Пусть существует решение х* системы ![]()
![]() Функция
Функция
однородна относительно х* с показателем γ.
4. Если![]() то f(x) вида (36) — однородная относительно х* с показателем 2α.
то f(x) вида (36) — однородная относительно х* с показателем 2α.
Дифференцируемая однородная функция удовлетворяет важному соотношению
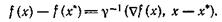 (30)
(30)
Чтобы доказать (30), возьмем в (29) λ = 1+ε
![]()
Устремляя ε к 0, получаем (30),
Точка х* не обязательно является минимумом f(x) (см. примеры 2 и 3). Однако если f(x) достигает минимума, то х* — точка глобального минимума f(x). Действительно, пусть 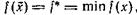 тогда
тогда ![]() f(x)=0. Подставляя
f(x)=0. Подставляя ![]() вместо х в (30), получаем, что
вместо х в (30), получаем, что![]() т. е. х* — точка глобального минимума. Именно этот случай и будет рассматриваться далее.
т. е. х* — точка глобального минимума. Именно этот случай и будет рассматриваться далее.
С помощью (30) можно найти точку минимума х*, вычислив f(x) и ![]() f(x) в конечном числе точек. Действительно, если γ известно, то, взяв п + 1 точек х0, ..., хп, мы получаем систему
f(x) в конечном числе точек. Действительно, если γ известно, то, взяв п + 1 точек х0, ..., хп, мы получаем систему
![]() (31)
(31)
линейную относительно п + 1 переменных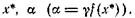
Исключая переменную α, получаем п линейных уравнений для
определения![]()
![]() (32)
(32)
Если же γ неизвестно, то можно взять п+2 точек х0, ..., xn+1 и определить п + 1 переменных γ, х* из линейной системы (32), в которой следует взять п+ 1 уравнений.
Аналогичный подход можно применить для минимизации функций общего вида подобно тому, как это делалось в методе секущих. В самом деле, пусть уже построены приближения х0.....xk, k > п. Взяв последние п + 1 из них (или п + 2, если γ неизвестно), решим систему (относительно х, α, γ, либо х, α)
![]() (33)
(33)
а решение х выберем в качестве xk+1. Для γ = 2 получаем метод, близкий к методу секущих, но отличающийся от него (в нем, в отличие от метода секущих, используются не только ![]() f(xі), но и значения функции f(хі)).
f(xі), но и значения функции f(хі)).
Такой процесс следует модифицировать с помощью тех же приемов, что и метод секущих (бороться с вырождением точек хk путем добавления новых точек, линейно независимых от предыдущих; регулировать длину шага и т. д.). Полезно также сравнивать фактическое значение f(xk+1) с «предсказанным» (равным α/γ). Это может служить проверкой предположения о близости функции к однородной. При решении систем линейных уравнений целесообразно использовать близость этих уравнений на соседних итерациях (см. лемму 4).
Для минимизации однородных и близких к ним функций можно применять и другие методы. Так, в градиентном методе можно применять специальные способы выбора длины шага. Пусть функция f(x) удовлетворяет условию (30), причем величины f*=f(x*) и γ известны. Рассмотрим градиентный метод
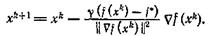 (34)
(34)
Выбор шага ![]() здесь сделан так, чтобы для
здесь сделан так, чтобы для
![]() удовлетворялось равенство
удовлетворялось равенство
![]()
ср. с (30). Тогда
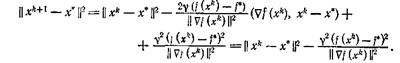
Отсюда следует, что если ![]() ограничена на множестве
ограничена на множестве
![]() Нетрудно видеть, что этот же результат остается справедливым, если в (30) равенство заменить на неравенство
Нетрудно видеть, что этот же результат остается справедливым, если в (30) равенство заменить на неравенство
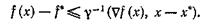 (35)
(35)
Несколько иной класс (по сравнению с однородными) задается формулой
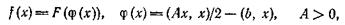 (36)
(36)
где F: R1→ R1 — монотонная на [φ *, ∞) функция,![]()
![]() Очевидно, что х* является точкой минимума f(x).
Очевидно, что х* является точкой минимума f(x).
Если задан явный вид F и φ, то в соответствии с последним замечанием вместо минимизации f(x) можно решать более простую задачу минимизации φ(х). Однако часто доступна меньшая информация о задаче. Тогда можно применить следующий вариант метода сопряженных градиентов:
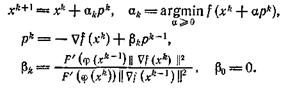 (37)
(37)
Нетрудно проверить, что метод (37) порождает ту же последовательность точек, что и метод сопряженных градиентов для минимизации φ (х), а потому является конечным.
Величину![]() входящую в формулу
входящую в формулу
для βk, можно оценивать приближенно, аппроксимируя F(z) квадратичной или степенной функцией. При этом метод (37) можно применять и для минимизации функций, не обязательно имеющих вид (36).
Пример. Для дважды дифференцируемой однородной функции справедливо соотношение ![]()
В целом методы, основанные на однородных и близких к ним аппроксимациях функций, пока мало исследованы.
5. Методы минимизации второго порядка
5.1. Особенности методов второго порядка
Методы безусловной оптимизации второго порядка используют вторые частные производные минимизируемой функции f(х). Суть этих методов состоит в следующем.
Необходимым условием экстремума функции многих переменных f(x) в точке х* является равенство нулю ее градиента в этой точке:
f’(х*) 0.
Разложение f’(х) в окрестности точки х[k] в ряд Тейлора с точностью до членов первого порядка позволяет переписать предыдущее уравнение в виде
f'(x) ![]() f’(x[k]) + f"(x[k]) (х - х[k]) 0.
f’(x[k]) + f"(x[k]) (х - х[k]) 0.
Здесь f"(x[k]) ![]() Н(х[k]) - матрица вторых производных (матрица Гессе) минимизируемой функции. Следовательно, итерационный процесс для построения последовательных приближений к решению задачи минимизации функции f(x) описывается выражением
Н(х[k]) - матрица вторых производных (матрица Гессе) минимизируемой функции. Следовательно, итерационный процесс для построения последовательных приближений к решению задачи минимизации функции f(x) описывается выражением
x[k+l] x[k] - H-1(x[k]) f’(x[k]) ,
где H-1(x[k]) - обратная матрица для матрицы Гессе, а H-1(x[k])f’(x[k]) ![]() р[k] - направление спуска.
р[k] - направление спуска.
Полученный метод минимизации называют методом Ньютона. Очевидно, что в данном методе величина шага вдоль направления р[k] полагается равной единице. Последовательность точек {х[k]}, получаемая в результате применения итерационного процесса, при определенных предположениях сходится к некоторой стационарной точке х* функции f(x). Если матрица Гессе Н(х*) положительно определена, точка х* будет точкой строгого локального минимума функции f(x). Последовательность x[k] сходится к точке х* только в том случае, когда матрица Гессе целевой функции положительно определена на каждой итерации.
Если функция f(x) является квадратичной, то, независимо от начального приближения х[0] и степени овражности, с помощью метода Ньютона ее минимум находится за один шаг. Это объясняется тем, что направление спуска р[k] ![]() H-1(x[k])f’(x[k]) в любых точках х[0] всегда совпадает с направлением в точку минимума х*. Если же функция f(x) не квадратичная, но выпуклая, метод Ньютона гарантирует ее монотонное убывание от итерации к итерации. При минимизации овражных функций скорость сходимости метода Ньютона более высока по сравнению с градиентными методами. В таком случае вектор р[k] не указывает направление в точку минимума функции f(x), однако имеет большую составляющую вдоль оси оврага и значительно ближе к направлению на минимум, чем антиградиент.
H-1(x[k])f’(x[k]) в любых точках х[0] всегда совпадает с направлением в точку минимума х*. Если же функция f(x) не квадратичная, но выпуклая, метод Ньютона гарантирует ее монотонное убывание от итерации к итерации. При минимизации овражных функций скорость сходимости метода Ньютона более высока по сравнению с градиентными методами. В таком случае вектор р[k] не указывает направление в точку минимума функции f(x), однако имеет большую составляющую вдоль оси оврага и значительно ближе к направлению на минимум, чем антиградиент.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
