

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Существенным недостатком метода Ньютона является зависимость сходимости для невыпуклых функций от начального приближения х[0]. Если х[0] находится достаточно далеко от точки минимума, то метод может расходиться, т. е. при проведении итерации каждая следующая точка будет более удаленной от точки минимума, чем предыдущая. Сходимость метода, независимо от начального приближения, обеспечивается выбором не только направления спуска р[k] ![]() H-1(x[k])f’(x[k]), но и величины шага а вдоль этого направления. Соответствующий алгоритм называют методом Ньютона с регулировкой шага. Итерационный процесс в таком случае определяется выражением
H-1(x[k])f’(x[k]), но и величины шага а вдоль этого направления. Соответствующий алгоритм называют методом Ньютона с регулировкой шага. Итерационный процесс в таком случае определяется выражением
x[k+l] x[k] - akH-1(x[k])f’(x[k]).
Величина шага аk выбирается из условия минимума функции f(х) по а в направлении движения, т. е. в результате решения задачи одномерной минимизации:
f(x[k] – ak H-1(x[k])f’(x[k]) ![]()
![]() (f(x[k] - aH-1(x[k])f’(x[k])).
(f(x[k] - aH-1(x[k])f’(x[k])).
Вследствие накопления ошибок в процессе счета матрица Гессе на некоторой итерации может оказаться отрицательно определенной или ее нельзя будет обратить. В таких случаях в подпрограммах оптимизации полагается H-1(x[k]) ![]() Е, где Е — единичная матрица. Очевидно, что итерация при этом осуществляется по методу наискорейшего спуска.
Е, где Е — единичная матрица. Очевидно, что итерация при этом осуществляется по методу наискорейшего спуска.
5.2. Методы линейной аппроксимации.
Для оценки градиента функции ![]() в точке х составим конечно-разностные отношения
в точке х составим конечно-разностные отношения
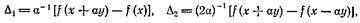 (1)
(1)
где у Rп — произвольный вектор.
Лемма 1. а) Если f дифференцируема в х, то
![]() (2)
(2)
б) Если f удовлетворяет условию Липшица с константой L в окрестности х, то при достаточно малых α
![]() (3)
(3)
в) Если f дважды дифференцируема и ![]() 2f удовлетворяет условию Липшица в окрестности х, то при достаточно малых α
2f удовлетворяет условию Липшица в окрестности х, то при достаточно малых α
![]() (4)
(4)
г) Если f(x) квадратична, то при любом α
![]() (5)
(5)
Таким образом, разностные отношения 1 и 2 могут служить приближением для линейной аппроксимации f(x). Рассмотрим методы вида
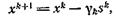 (6)
(6)
где γk≥0 - длина шага, a sk вычисляется по одной из двух формул
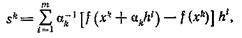 (7)
(7)
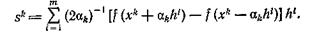 (8)
(8)
Здесь hі, i= 1, ..., m, — векторы, задающие направления пробных шагов, αk — длина пробного шага. Выбирая различные hі и т, получим те или иные алгоритмы.
а) Градиентный спуск — метод нахождения локального минимума (максимума) функции с помощью движения вдоль градиента. Для минимизации функции в направлении градиента используются методы одномерной оптимизации, например, метод золотого сечения. Также можно искать не наилучшую точку в направлении градиента, а какую-либо лучше текущей. Сходимость метода градиентного спуска зависит от отношения максимального и минимального собственных чисел матрицы Гессе в окрестности минимума (максимума). Чем больше это отношение, тем хуже сходимость метода.
Пусть целевая функция имеет вид:
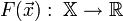 .
.
И задача оптимизации задана следующим образом:
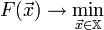
Основная идея метода заключается в том, чтобы идти в направлении наискорейшего спуска, а это направление задаётся антиградиентом ![]() :
:
![]()
где λ[j] выбирается
- постоянной, в этом случае метод может расходиться; дробным шагом, т. е. длина шага в процессе спуска делится на некоторое число; наискорейшим спуском:
Алгоритм
Задают начальное приближение и точность расчёта х-0, ε Рассчитывают- Если
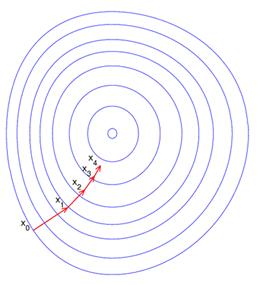
Рис. 1
На рис. 1 приведена иллюстрация последовательных приближений к точке экстремума в направлении наискорейшего спуска (в направлении стрелок) в случае дробного шага. Линии уровня изображены неправильной формы овалами.
Пример
Применим градиентный метод к функции 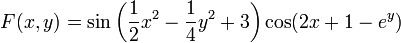 Тогда последовательные приближения будут выглядеть так (рис. 2):
Тогда последовательные приближения будут выглядеть так (рис. 2):
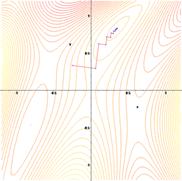
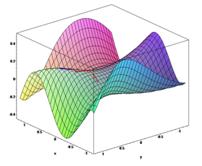
Рис. 2
Упомянем, что метод наискорейшего спуска может иметь трудности в патологических случаях овражных функций, так, к примеру, в случае функции Розенброка.
б) Метод наискорейшего спуска (метод градиента)
Выбирают ![v^{[j]}_i = -\frac{\partial F}{\partial x_i}](/text/80/174/images/image771.gif) , где все производные вычисляются при
, где все производные вычисляются при ![x_i = x^{[j]}_i](/text/80/174/images/image772.gif) , и уменьшают длину шага λ[j] по мере приближения к минимуму функции F.
, и уменьшают длину шага λ[j] по мере приближения к минимуму функции F.
Для аналитических функций F и малых значений fi тейлоровское разложение F(λ[j]) позволяет выбрать оптимальную величину шага
![\lambda^{[j]}=\frac{\sum_{k=1}^n(\frac{\partial F}{\partial x_k})^2}{\sum_{k=1}^n\sum_{h=1}^n\frac{\partial^2 F}{\partial x_kdx_h}\frac{\partial F}{\partial x_k}\frac{\partial F}{\partial x_h}}](/text/80/174/images/image773.gif)
где все производные вычисляются при ![]() . Параболическая интерполяция функции F(λ[j]) может оказаться более удобной.
. Параболическая интерполяция функции F(λ[j]) может оказаться более удобной.
Алгоритм
Задаются начальное приближение и точность расчёта х-0, ε Рассчитывают- Если
а) Разностный аналог градиентного метода: m = n, hі = еі, і = l, ..., п, где еі — координатные орты. Иначе говоря, пробные шаги делаются по координатным осям, так что метод (6), (7) в координатной записи имеет вид
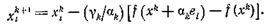 (9)
(9)
В соответствии с леммой 1
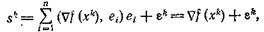 (10)
(10)
где остаточный член εk может быть оценен для каждой из формул (7), (8) в зависимости от гладкости f(x).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
