

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рис. 5.3. Фазовый портрет социально-экономического развития региона
Подобные рассуждения приводят к тому, что среди мультиколлинеарных признаков ![]() , согласно цепочке зависимости, следует оставить признак
, согласно цепочке зависимости, следует оставить признак ![]() , основываясь на рассуждениях об отборе информативных признаков, приведенных выше. Следует особо подчеркнуть, что мы не выявляем вид зависимости признаков: является ли она причинно-следственной или статистической.
, основываясь на рассуждениях об отборе информативных признаков, приведенных выше. Следует особо подчеркнуть, что мы не выявляем вид зависимости признаков: является ли она причинно-следственной или статистической.
Однако не стоит забывать, что качественный анализ признаков, проведенный исследователем, не позволяет исключать признаки, которые не оказались информативными, но информация о поведении объекта в разрезе этих показателей представляет исследовательский интерес. Кроме того, веса признаков ![]() достаточно высоки, поэтому даже по этим соображениям их исключать нецелесообразно. В связи с этим система информативных признаков в окончательном варианте представляется признаками
достаточно высоки, поэтому даже по этим соображениям их исключать нецелесообразно. В связи с этим система информативных признаков в окончательном варианте представляется признаками ![]() .
.
В заключение следует отметить, что предложенная методология легко реализуется в разрезе каждой из четырех методик и дает возможность выявить латентные связи и оценки на основе анализа данных, представленных эмпирической информацией, сведенной в информационный массив.
5.6. Алгоритм решения задачи таксономии
Одним из разделов многомерного статистического анализа является таксономия (кластер-анализ, теория распознавания образов). В течение достаточно длительного периода времени для статистического анализа и моделирования в основном использовались два вида статистических методов — группировки (главным образом комбинационная группировка) и корреляционно-регрессионного анализа. Последний примыкает к табличным, группировочным способам изучения связи, представляет их обобщение. Широкая разработка в шестидесятые годы новой области научных исследований — таксономии — значительно расширила арсенал методов статистического изучения связей.
В последние годы большое внимание уделяется использованию алгоритмов таксономии в социально-экономических исследованиях. Их применение позволяет решить ряд острых проблем статистического моделирования связей, таких как формирование однородных совокупностей, выбор существенных признаков, учет влияния качественных признаков и скачкообразного характера развития многомерных объектов, оценка устойчивости зависимостей во времени и т. п. Кроме того, при использовании методов таксономии снимаются ограничения на форму связи.
Все это расширяет сферу применения экономико-математических моделей, повышает их адекватность реальным процессам.
Суть же задач таксономии заключается в следующем: имеется некоторое множество объектов, необходимо разделить его с помощью определенного решающего правила на заранее заданное или незаданное число классов.
Трудность построения методов автоматического разделения «простых» групп в пространстве высокой размерности заключается в том, что группировка является некоторой «целостной» операцией, соответствующей человеческой возможности рассматривать одномоментно на изображении множества отношений. При анализе многомерных данных способность человека к такому «целостному» восприятию резко снижается, поскольку необходимо детально проанализировать все относящиеся к делу зависимости между парами объектов.
Исторически методам таксономии предшествовали методы комбинационной группировки. При использовании методов комбинационной группировки классификация осуществляется путем последовательного логического деления совокупности по отдельным признакам: сначала по одному, затем каждую из полученных групп по другому признаку и т. д. Сформированные в результате этого процесса логических делений группы характерны тем, что все их элементы обладают одинаковыми значениями комплекса признаков группировки. Другими словами, достаточным и необходимым условием принадлежности единицы совокупности к данной группе является обладание соответствующими значениями комплекса группировочных признаков. В пределах набора признаков группировки элементы групп неразделимы.
В ходе развития научных исследований обнаружилось, что принципы чистой логики, лежащие в основе метода комбинационной группировки, нелегко применять к эмпирическому материалу. Опыт множества эмпирических исследований свидетельствует о существовании естественных типов явлений, каждый из которых объединяет индивидуальные явления, обладающие большим числом признаков, и что ни для какого естественного типа невозможно найти жесткого определения, выраженного через небольшой набор совпадающих признаков. В некоторых случаях те или иные объекты можно без сомнений отнести к определенному типу, несмотря на то, что у них отсутствуют или совпадают несколько признаков из числа использованных при формировании групп. Все это обусловило необходимость разработки новых принципов многомерной классификации, отличных от классических.
Сущность этих новых принципов классификации, лежащих в основе задач таксономии, сводится к следующему: классификация объектов производится не последовательно по отдельным признакам, а одновременно по большому их числу. Этот фиксированный набор признаков образует так называемое «признаковое пространство»; каждому признаку придается смысл координаты. Если исследователь оперирует n признаками, то любой объект рассматривается как точка в n-мерном признаковом пространстве, и задача классификации сводится к выделению сгущений точек (объектов) в данном пространстве. Выделение этих сгущений в разных алгоритмах таксономии производится по-разному, но общим для всех является то, что группы (таксоны, кластеры) формируются на основании «близости» объектов по большому числу признаков. При этом ни один из признаков, входящих в набор, не является необходимым или достаточным условием принадлежности объекта к данной группе, то есть классификация происходит одновременно по всему комплексу признаков, описывающих объект.
Представляется, что подходы к формированию групп, используемые в таксономии, лучше, чем комбинационные группировки, согласуются с ранее сформулированным положением о существовании естественных типов объектов, близких по комплексу признаков. Действительно, при использовании комбинационной группировки объект, отклоняющийся от нормы, характерной для группы, по одному единственному признаку набора будет автоматически исключен из группы. Более того, если этот признак используется на первом шаге группировки, то объект может легко попасть в группу, очень далеко от той, с которой он действительно имеет наибольшее сходство. Если использовать понятие признаковых пространств, то группы, получаемые при комбинационной группировке, представляют собой сектора такого пространства свойств. При этом границы между секторами-группами обычно параллельны осям признакового пространства. Осуществляя классификацию методом комбинационных группировок, исследователь зачастую искусственно «рубит» признаковые пространства, подчас разрушая реально существующие в нем обособленно-однородные классы жестко заданными интервалами признаков. Этот основной недостаток делает комбинационные группировки неэффективными для выделения типов объектов по комплексу признаков, так как с добавлением каждого нового признака опасность разрушения объективно существующих однородных групп возрастает. Следовательно, основное преимущество методов таксономии заключается в том, что они позволяют с той или иной степенью приближения «нащупать» и выделить реально существующие в признаковом пространстве скопления точек-объектов, что связано с одновременной группировкой по большому числу признаков и использованием в качестве границ сложных поверхностей.
В настоящее время отечественными и зарубежными исследователями разработан обширный класс алгоритмов таксономии. Из всего многообразия алгоритмов можно сформировать два типа, наиболее отражающих классический прием в решении задач таксономии.
Первый тип алгоритмов предназначен для разбиения исходной совокупности на непересекающиеся гиперсферические области наиболее близких в некотором роде объектов. В результате работы алгоритма получается несколько вариантов разбиения. Выбор лучшего из них производится самим исследователем, что свидетельствует о превалировании экспертных оценок в решении задач таксономии наряду с использованием аналитических методов, предполагающих применение критериев в оценке качества полученных таксонов.
Поскольку результатом работы алгоритмов данного типа является набор вариантов разбиения, то это создает некоторые неудобства в практической работе, так как приходится выбирать подходящее разбиение. Указанные неудобства, а также специфика таксонов заставляют искать другие алгоритмы таксономии.
В отличие от алгоритмов первого типа алгоритмы второго типа не являются многовариантными, и в результате их применения по заданному критерию качества получается наилучший вариант таксономии. Кроме того, здесь не накладывается жесткого условия на форму таксонов.
Всякая таксономия преследует определенные цели. Они бывают внешними или, как их иногда называют, «суперцелями» и внутренними. Под «суперцелью» обычно понимают тот формализованный содержательный критерий, которому должна отвечать таксономия, ибо исследователя удовлетворяет не всякая группировка, а такая, которая отражает закономерности рассматриваемой задачи. Когда сформулирована «суперцель», то можно искать вариант таксономии, который максимально удовлетворяет внутренним целям, а именно: «близости» объектов в группах, «удаленности» таксонов, «одинаковости» распределения объектов внутри таксона и др.
Необходимо отметить, что таксономия как сравнительно молодая отрасль науки находится в стадии становления и имеет много нерешенных проблем. В частности, одним из нерешенных вопросов является неоднородность решения. Разные алгоритмы и программы могут давать на одном и том же материале различные результаты.
В распоряжении исследователя пока нет эффективных формальных критериев для оценки и сравнения разных алгоритмов и программ таксономии. Поэтому необходимо осторожно, критически относиться к результатам формального анализа. При решении конкретных социально-экономических задач методы таксономии выступают в качестве хотя и мощного, но вспомогательного инструмента исследования, поскольку результат разбиения совокупности на формальные элементы в значительной мере зависит от заданного пространства признаков, выбранных критериев остановки процесса разбиения и т. д. Все эти вопросы в настоящее время решаются исследователем на основе личного опыта, обобщения априорных знаний специалистов, изучения теории конкретного явления и т. д.
Обобщая идеи алгоритмов и программ для решения задач таксономии, можно прийти к следующему выводу. Все или большинство из них предполагают решение задачи в два этапа. На первом этапе задается заранее количество таксонов, которые исследователь намерен получить. На втором же этапе задаются центры искомых таксонов, исходя из предварительного анализа эмпирических данных.
Задачи как первого, так и второго этапов достаточно сложны. Во-первых, задавая изначально количество таксонов, мы тем самым получаем рассогласование между заданным числом таксонов и их объективно существующим количеством. Во-вторых, задавая центры таксонов, мы рискуем получить не объективно существующие сгущения объектов в признаковом пространстве, а те объекты, которые близки к тому или иному центру. Однако существуют алгоритмы, которые путем пошаговой итерации переводят изначально заданный центр того или иного класса в центр объективно существующего таксона, но при этом опять же априорно заданное количество таксонов может нарушить выявление объективно существующих.
Нами предлагается следующий подход в решении задач таксономии, который преодолевает недостатки типов алгоритмов, приведенных выше.
Пусть многомерные объекты описываются признаками 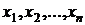 . Исходная информация для N объектов по этим признакам сведена в матрицу «объект-признак», элементами
. Исходная информация для N объектов по этим признакам сведена в матрицу «объект-признак», элементами ![]() которой выступают значения j-го признака, присущие i-му объекту. В n-мерном признаковом пространстве состояние любого объекта представляет собой точку, координатами которой являются значения признаков, описывающих его.
которой выступают значения j-го признака, присущие i-му объекту. В n-мерном признаковом пространстве состояние любого объекта представляет собой точку, координатами которой являются значения признаков, описывающих его.
Если вести речь об объективно существующих таксонах, то в этом признаковом пространстве они представляют собой сгущения точек. Задача таксономии заключается в выявлении этих сгущений. В отличие от типов алгоритмов таксономии, описанных выше, нами предлагается построить ось в этом n-мерном признаковом пространстве с началом, совпадающим с началом координат признакового пространства, и ввести масштаб на построенной оси.
Однако центр оси еще не задает ее направления. Следовательно, нужно взять еще одну точку, через которую пройдет искомая ось. В качестве второй точки может выступать та, которая имеет в качестве своих координат эталонные значения признаков ![]() , а сам объект, обладающий эталонными значениями признаков, назовем эталонным. Согласно предлагаемому подходу эталонный объект может быть виртуальным, что в подавляющем большинстве случаев таковым и является, и все остальные объекты сравниваются с ним.
, а сам объект, обладающий эталонными значениями признаков, назовем эталонным. Согласно предлагаемому подходу эталонный объект может быть виртуальным, что в подавляющем большинстве случаев таковым и является, и все остальные объекты сравниваются с ним.
Значения длин проекций объектов на ось будут представлять собой интегральный показатель оценки уровня объекта по комплексу исходных показателей. Интегральная оценка уровня эталонного объекта соответствует 100, а значения этого показателя для любого объекта исследуемой совокупности будут измеряться значением на шкале данной оси в масштабе, построенном при условии, что нулевой уровень соответствует объекту, имеющему нулевые значения признаков, а 100 — эталонному объекту.
Основной задачей предлагаемого подхода является построение формулы, описывающей ось, на которую проецируются объекты совокупности. Нами предлагается
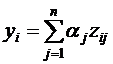 ,
,
где ![]() — значение потенциальной функции для i-го объекта, оцененное по комплексу признаков;
— значение потенциальной функции для i-го объекта, оцененное по комплексу признаков;
![]() — стандартизованные значения исходных признаков, рассчитываемые по формуле
— стандартизованные значения исходных признаков, рассчитываемые по формуле
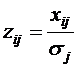 ,
,
где ![]() — среднее квадратическое отклонение признака xj;
— среднее квадратическое отклонение признака xj;
![]() — вес j-го признака в потенциальной функции, рассчитываемый по формуле
— вес j-го признака в потенциальной функции, рассчитываемый по формуле
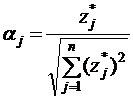 ,
,
где ![]() — стандартизованное значение эталонного значения признака
— стандартизованное значение эталонного значения признака ![]() , рассчитываемое по формуле
, рассчитываемое по формуле
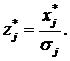
Уровень потенциала эталонного объекта определяется как
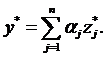
Чтобы дать комплексную оценку уровня потенциала i-го объекта, необходимо сопоставить его состояние с эталонным значением. Иначе комплексная оценка уровня потенциала ![]() находится из пропорции
находится из пропорции
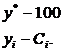
Откуда
 .
.
Формулу можно представить в развернутом виде:
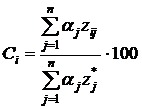 ,
,
или в терминах исходных признаков
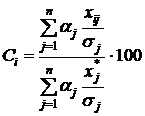 .
.
Величина ![]() соответствует значению потенциала i-го объекта на построенной шкале. Предложенная шкала позволяет наглядно представить комплексную оценку потенциала многомерного объекта.
соответствует значению потенциала i-го объекта на построенной шкале. Предложенная шкала позволяет наглядно представить комплексную оценку потенциала многомерного объекта.
Далее задачу таксономии нами предлагается осуществить по одному классификационному и самому информативному признаку — уровню потенциала. И, таким образом, задача многомерной классификации сводится к одномерной. При этом, существенно упрощая решение задачи, мы избегаем потери информации об объектах исследования и достигаем высокого уровня корректности в решении задачи таксономии.
Практически предлагаемую одномерную классификацию можно осуществить путем упорядочения объектов по уровню потенциала в порядке возрастания, или убывания. Поскольку уровень потенциала, согласно данному подходу, представляет собой длину проекции объекта в n-мерном признаковом пространстве на ось, то, построив геометрически ось с началом и масштабом, наносятся на эту ось значения уровней потенциалов объектов совокупности. Сгущения точек, отражающих уровни потенциалов объектов, на построенной оси представляют собой объективно существующие таксоны. Пронумеровав точки на оси согласно номерам объектов совокупности, легко восстанавливаются объекты, попавшие в тот или иной таксон. Таким образом, по одномерной классификации осуществляется выявление таксонов-классов многомерных объектов.
Упорядочив приведенные выше рассуждения, можно построить алгоритм решения задачи таксономии.
Пусть совокупность из N многомерных объектов исследования описывается системой показателей ![]() . Информация по всем N объектам в разрезе n признаков сводится в информационный массив «объект-признак», элементами
. Информация по всем N объектам в разрезе n признаков сводится в информационный массив «объект-признак», элементами ![]() которого являются значения j-го признака, присущие i-му объекту. Для решения задачи таксономии необходимо осуществить следующие действия.
которого являются значения j-го признака, присущие i-му объекту. Для решения задачи таксономии необходимо осуществить следующие действия.
Алгоритм решения задачи таксономии
1. Рассчитать средние значения признаков
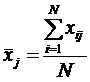 .
.
2. Рассчитать средние квадратические отклонения признаков
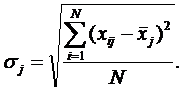
3. Рассчитать стандартизованные значения признаков
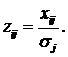
4. Определить экспертным путем эталонные значения показателей
![]() .
.
5. Рассчитать стандартизованные значения эталонов
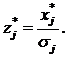
6. Рассчитать веса признаков в потенциальной функции
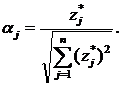
7. Построить потенциальную функцию
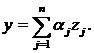
8. Рассчитать значения потенциальной функции для каждого объекта совокупности
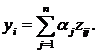
9. Рассчитать эталонное значение потенциальной функции
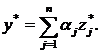
10. Рассчитать потенциалы для каждого объекта
![]()
11. Построить ось с началом и масштабом.
12. Нанести на ось значения потенциалов, пронумеровав точки на оси согласно нумерации объектов в совокупности.
13. По сгущению точек выявляются номера объектов, попавших в таксоны.
14. По данной нумерации восстанавливаются объекты, попавшие в тот или иной таксон, и полная информация по каждому объекту в разрезе исходных признаков.
Однако предлагаемый алгоритм требует иллюстрации в применении. Другими словами, требуется проиллюстрировать механизм реализации алгоритма решения задачи таксономии на конкретной совокупности многомерных объектов.
Механизм реализации алгоритма решения
задачи таксономии
Для примера в качестве совокупности объектов исследования нами взяты потребительские общества Якутского союза потребительских обществ. Исходные данные для составления информационного массива использованы из материалов, разработанных [1].
В качестве объектов взяты 46 районных потребительских обществ, а в качестве признаков использовано пять, отражающих социальную миссию потребительской кооперации. В частности, их состав следующий:
![]() — сумма социальных льгот, тыс. руб.;
— сумма социальных льгот, тыс. руб.;
![]() — сумма закупок на душу населения, руб.;
— сумма закупок на душу населения, руб.;
![]() — сумма услуг населению, тыс. руб.;
— сумма услуг населению, тыс. руб.;
![]() — число вновь созданных рабочих мест;
— число вновь созданных рабочих мест;
![]() — численность привлеченных на временную работу, чел.
— численность привлеченных на временную работу, чел.
Для иллюстрации применения алгоритма взято пять признаков, хотя увеличение количества признаков не вызывает существенных затруднений в осуществлении расчетов.
Поскольку в качестве признаков, описывающих объекты, используются показатели, отражающие социальное содержание, то и интегральная оценка будет отражать уровень социального потенциала объектов — организаций потребительской кооперации. Исходные данные представлены табл. 5.7. Сами же расчеты представлены табл. 5.8—5.10.
Таблица 5.7
Данные для расчета социального потенциала организаций
Организация | Сумма социальных льгот, тыс. руб.
| Сумма закупок на душу населения, руб.
| Сумма услуг населению, тыс. руб.
| Число вновь созданных рабочих мест
| Численность привлеченных на временную работу, чел.
|
1 | 26,62 | 0,00 | 0,00 | 0,00 | 0,00 |
2 | 25,33 | 209,58 | 0,00 | 0,00 | 0,00 |
3 | 103,85 | 609,63 | 60,70 | 14,00 | 27,00 |
4 | 55,74 | 158,90 | 58,30 | 7,00 | 3,00 |
5 | 44,79 | 252,91 | 17,00 | 7,00 | 10,00 |
6 | 87,54 | 282,98 | 76,40 | 6,00 | 7,00 |
7 | 70,04 | 0,00 | 0,00 | 0,00 | 0,00 |
8 | 35,58 | 545,45 | 0,00 | 9,00 | 3,00 |
9 | 120,53 | 0,00 | 0,00 | 8,00 | 0,00 |
10 | 92,18 | 409,78 | 11,80 | 9,00 | 5,00 |
11 | 87,02 | 439,80 | 5,00 | 9,00 | 19,00 |
12 | 88,90 | 485,90 | 8,40 | 4,00 | 0,00 |
13 | 96,28 | 445,52 | 46,70 | 8,00 | 0,00 |
14 | 99,15 | 656,67 | 8,70 | 6,00 | 12,00 |
15 | 101,38 | 500,42 | 1,60 | 1,00 | 5,00 |
16 | 62,39 | 301,82 | 10,20 | 13,00 | 3,00 |
17 | 65,89 | 348,89 | 9,70 | 4,00 | 13,00 |
18 | 88,16 | 246,77 | 0,00 | 12,00 | 35,00 |
19 | 73,24 | 412,94 | 0,00 | 3,00 | 4,00 |
20 | 79,29 | 647,39 | 0,00 | 6,00 | 7,00 |
21 | 48,22 | 268,40 | 14,70 | 2,00 | 7,00 |
22 | 44,43 | 188,65 | 0,00 | 4,00 | 0,00 |
23 | 129,10 | 373,93 | 547,00 | 42,00 | 270,00 |
24 | 100,22 | 602,91 | 0,00 | 14,00 | 15,00 |
25 | 99,37 | 1207,62 | 16,00 | 7,00 | 5,00 |
26 | 127,30 | 300,00 | 0,00 | 1,00 | 3,00 |
27 | 43,63 | 55,00 | 0,00 | 0,00 | 0,00 |
28 | 77,31 | 75,23 | 0,00 | 10,00 | 10,00 |
29 | 78,23 | 330,04 | 203,10 | 26,00 | 101,00 |
Продолжение табл. 5.7 | |||||
30 | 82,86 | 1329,29 | 8,00 | 0,00 | 0,00 |
31 | 120,70 | 445,23 | 2,00 | 3,00 | 0,00 |
32 | 91,94 | 117,50 | 0,00 | 2,00 | 13,00 |
33 | 95,61 | 465,52 | 4,00 | 3,00 | 16,00 |
34 | 106,80 | 1060,59 | 0,00 | 1,00 | 4,00 |
35 | 57,33 | 239,39 | 38,50 | 7,00 | 8,00 |
36 | 117,63 | 270,51 | 177,60 | 33,00 | 34,00 |
37 | 88,21 | 345,53 | 0,00 | 3,00 | 0,00 |
38 | 91,54 | 563,04 | 0,00 | 14,00 | 3,00 |
39 | 103,35 | 649,67 | 5,20 | 8,00 | 0,00 |
40 | 109,25 | 219,85 | 43,60 | 18,00 | 22,00 |
41 | 63,75 | 698,44 | 0,00 | 4,00 | 0,00 |
42 | 63,82 | 727,37 | 0,00 | 12,00 | 5,00 |
43 | 88,83 | 831,11 | 0,00 | 0,00 | 0,00 |
44 | 124,99 | 311,10 | 90,80 | 21,00 | 8,00 |
45 | 68,74 | 526,67 | 0,00 | 6,00 | 0,00 |
46 | 26,92 | 45,67 | 0,00 | 3,00 | 0,00 |
|
Таблица 5.8

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
