
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
39,64% £ π £ 40,36%
или
39,6% £ π £ 40,4%.
Если бы мы использовали для расчета доверительных границ генерального параметра таблицу интеграла вероятностей, то t было бы равно 1,96 и ∆p - ± 0,31, т. е. доверительный интервал был бы несколько уже.
Малые выборки широко используются для решения задач, связанных с испытанием статистических гипотез, особенно гипотез о средних величинах.
7.8. Статистическая проверка гипотез
(общие понятия)
Оценку генерального параметра получают на основе выборочного показателя с учетом ошибки репрезентативности. В другом случае в отношении свойств генеральной совокупности выдвигается некоторая гипотеза о величине средней, дисперсии, характере распределения, форме и тесноте бвязи между переменными. Проверка гипотезы осуществляется на основе выявления согласованности эмпирических данных с гипотетическими (теоретическими). Если расхождение между сравниваемыми величинами не выходит за пределы случайных ошибок, гипотезу принимают. При этом не делается никаких заключений о правильности самой гипотезы, речь идет лишь о согласованности сравниваемых данных. Основой проверки статистических гипотез являются данные случайных выборок. При этом безразлично, оцениваются ли гипотезы в отношении реальной или гипотетической генеральной совокупности. Последнее открывает путь применения этого метода за пределами собственно выборки: при анализе результатов эксперимента, данных сплошного наблюдения, но малой численности. В этом случае рекомендуется проверить, не вызвана ли установленная закономерность стечением случайных обстоятельств, насколько она характерна для того комплекса условий, в которых находится изучаемая совокупность.
Особенно часто процедура проверки статистических гипотез применяется для оценки существенности расхождений сводных характеристик отдельных совокупностей (групп): средних, относительных величин. Такого рода задачи, как правило, возникают в социальной статистике. Трудоемкость статистико-социологических исследований приводит к тому, что почти все они строятся на несплошном учете. Поэтому проблема 'доказательности выводов в социальной статистике стоит особенно остро. Применяя процедуру проверки статистических гипотез, следует помнить, что она может гарантировать результаты с определенной вероятностью лишь по «беспристрастным» выборкам, на основе объективных данных.
Статистической гипотезой называется предположение о свойстве генеральной совокупности, которое можно проверить, опираясь на данные выборки. Обозначается гипотеза буквой Н от латинского слова hypothesis. Так, может быть выдвинута гипотеза о том, что средняя в генеральной совокупности равна некоторой величине Н : μ = а, или о том, что генеральная средняя больше некоторой величины Н : μ > b.
Различают простые и сложные гипотезы. Гипотеза называется простой, если она однозначно характеризует параметр распределения случайной величины. Например, Н : ц = а.'Сложная гипотеза состоит из конечного или бесконечного числа простых гипотез, при этом указывается некоторая область вероятных значений параметра. Например, Н : μ > b. Эта гипотеза состоит из множества простых гипотез Н :μ = с, где с — любое число, большее b.
Гипотезы о параметрах генеральной совокупности называются параметрическими, о распределениях - непараметрическими.
Гипотеза о том, что две совокупности, сравниваемые по одному или нескольким признакам, не отличаются, называется нулевой гипотезой (или нуль-гипотезой). Она обозначается Н0. При этом предполагается, что действительное различие сравниваемых величин равно нулю, а выявленное по данным отличие от нуля носит случайный характер. Например, Н0 : μ1 = μ2. Нулевая гипотеза отвергается тогда, когда по выборке получается результат, который при истинности выдвинутой нулевой гипотезы маловероятен. Границей невозможного или маловероятного обычно считают α = 0,05, т. е. 5%, или 0,01, 0,001. Если ориентироваться на правило «трех сигм», то вероятность ошибки α должна быть. равна 0,0027. Однако для этого уровня вероятности ошибки значения критериев редко табулируются: как правило, значения критериев в статистико-математических таблицах рассчитаны для вероятностей ошибки 0,05; 0,01; 0,001.
Статистическим критерием называют определенное правило, устанавливающее условия, при которых проверяемую нулевую гипотезу следует либо отклонить, либо не отклонить. Критерий проверки статистической гипотезы определяет, противоречит ли выдвинутая гипотеза фактическим данным или нет.
Проверка статистических гипотез складывается из следующих этапов:
• формулируется в виде статистической гипотезы задача исследования;
• выбирается статистическая характеристика гипотезы;
• выбираются испытуемая и альтернативная гипотезы на основе анализа возможных ошибочных решений и их последствий;
• определяются область допустимых значений, критическая область, а также критическое значение статистического критерия (t, F, χ2 ) по соответствующей таблице;
• вычисляется фактическое значение статистического критерия;
• проверяется испытуемая гипотеза на основе сравнения фактического и критического значений критерия, и в зависимости от результатов проверки гипотеза либо отклоняется, либо не отклоняется.
При проверке гипотез по одному из критериев возможны два ошибочных решения:
1) неправильное отклонение нулевой гипотезы: ошибка 1-го рода;
2) неправильное принятие нулевой гипотезы: ошибка 2-го рода. В то время, как фактически нулевая гипотеза верна (1) и нулевая гипотеза не верна (2), принимают два ошибочных решения: 1) нулевая гипотеза отклоняется и принимается альтернативная гипотеза; 2) нулевая гипотеза не отклоняется. Возможные решения представлены в табл. 7.4.
Таблица 7.4
Возможные выводы при проверке гипотез
Решение | Фактически | |
по критерию | H0 верна | H0 не верна |
H0 отклоняется | Ошибка 1-го рода | Правильное решение |
H0 не отклоняется | Правильное решение | Ошибка 2-го рода |
Если, например, установлено, что новое минеральное удобрение лучше, хотя на самом деле его действие не отличается от старого, то это ошибка 1-го рода. Если мы решили, что оба вида удобрений одинаковы, то допущена ошибка 2-го рода.
Вероятности, соответствующие неверным решениям, называются риском 1 и риском 2. Риск 1 равен вероятности ошибки а (уровню значимости), риск 2 равен вероятности ошибки р. Поскольку а всегда больше нуля, то всегда есть риск ошибки β. При заданных α и объеме выборки п значение β будет тем больше, чем меньше принятое α. Если п велико, то α и β могут быть сколь угодно малыми, т. е. решения будут более обоснованными. При малом объеме выборки и малом а возможность установить фактически существующие различия мала.
Обычно задают значение а и пытаются сделать возможно β малым. Вероятность 1 - β называется мощностью критерия: чем она больше, тем меньше вероятность ошибки второго рода.
Альтернативная гипотеза Н1 может быть сформулирована по-разному в зависимости от того, какие отклонения от гипотетической величины нас особенно беспокоят: положительные, отрицательные либо и те, и другие. Соответственно альтернативные гипотезы могут быть записаны как
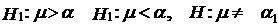 .
.
От того, как формулируется альтернативная гипотеза, зависят границы критической области и области допустимых значений.
Критической областью называется область, попадание значения статистического критерия в которую приводит к отклонению Н0. Вероятность попадания значения критерия в эту область равна принятому уровню значимости.
Область допустимых значений дополняет критическую область. Если значение критерия попадает в область допустимых значений, это свидетельствует о том, что выдвинутая гипотеза Нц не противоречит фактическим данным ( H0 не отклоняется).
Точки, разделяющие критическую область и область допустимых значений, называются критическими точками или границами критической области. В зависимости от формулировки альтернативной гипотезы критическая область может быть двухсторонняя или односторонняя (левосторонняя либо правосторонняя).
Если вычисляемое значение критерия попадает в критическую область, нулевая гипотеза отклоняется, она противоречит фактическим данным.
7.9. Проверка гипотезы о законе распределения
Одна из важнейших задач анализа вариационных рядов заключается в выявлении закономерности распределения и определении ее характера. Основной путь в выявлении закономерности распределения - построение вариационных рядов для достаточно больших со-вокупностей. Большое значение для выявления закономерностей распределения имеет правильное построение самого вариационного ряда: выбор числа групп и размера интервала варьирующего признака.
Когда мы говорим о характере, типе закономерности распределения, то имеем в виду отражение в нем общих условий, определяющих вариацию. При этом речь всегда идет о распределениях качественно однородных явлений. Общие условия, определяющие тип закономерности распределения, познаются анализом сущности явления, тех его свойств, которые определяют вариацию изучаемого признака. Следовательно, должна быть выдвинута какая-то научная гипотеза, обосновывающая определенный тип теоретической кривой распределения.
Под теоретической кривой распределения понимается графическое изображение ряда в виде непрерывной линии изменения частот в вариационном ряду, функционально связанного с изменением вариантов (значений признака). Теоретическое распределение может быть выражено аналитически - формулой, которая связывает частоты вариационного ряда и соответствующие значения признака. Такие алгебраические формулы носят название законов распределения.
Большое познавательное значение имеет сопоставление фактических кривых распределения с теоретическими.
Как уже отмечалось, часто пользуются типом распределения, которое называется нормальным. Формула функции плотности нормального распределения:
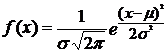 .
.
Следовательно, кривая нормального распределения может быть построена по двум параметрам - средней арифметической ц и среднему квадратическому отклонению ст.
Гипотезы о распределениях заключаются в том, что выдвигается предположение о том, что распределение в генеральной совокупности подчиняется какому-то определенному закону. Проверка гипотезы состоит в том, чтобы на основании сравнения фактических (эмпирических) частот с предполагаемыми (теоретическими) частотами сделать вывод о соответствии фактического распределения гипотетическому распределению. Может проводиться и сравнение частостей.
Под гипотетическим распределением необязательно понимается нормальное распределение. Может быть выдвинута гипотеза о биномиальном распределении, распределении Пуассона и т. д. Причина частого обращения к нормальному распределению в том, что в этом типе распределения выражается закономерность, возникающая при взаимодействии множества случайных причин, когда ни одна из них не имеет преобладающего влияния. Закон нормального распределения лежит в основе многих теорем математической статистики, применяемых для оценки репрезентативности выборок, при измерении связей и т. д. В социально-экономической статистике нормальное распределение встречается редко, но сравнение с ним важно для выяснения степени и характера отклонения от него фактического распределения.
В главе 5 отмечалось, что близость средней арифметической величины, медианы и моды указывает на вероятное соответствие изучаемого распределения нормальному закону. Но более полная и точная проверка соответствия распределения гипотезе о нормальном законе производится с использованием специальных критериев, из которых рассмотрим наиболее употребимый критерий c2 (хи-квадрат) К. Пирсона.
Для проверки гипотезы о соответствии эмпирического распределения закону нормального распределения необходимо частоты (частости) фактического распределения сравнить с частотами (частостями) нормального распределения. Значит, нужно по фактическим данным вычислить теоретические частоты кривой нормального распределения f̂ по формуле (для дискретных рядов):
![]() , (7.27)
, (7.27)
где п - объем выборки;
i - величина интервала вариационного ряда.
Значение ординат кривой нормального распределения f(t) можно получить по таблицам значения функции:
![]() .
.
Проверяемая гипотеза формулируется как Н0: fj = f̂j альтернаивная - как Н1: fj ≠ f̂j.
Проверка гипотезы требует, чтобы был построен теоретический ряд распределения с частотами f̂j, соответствующими нормальному закону, при тех же значениях параметров распределения
![]()
Методика построения теоретического ряда такова:
1. По фактическому интервальному ряду (табл. 5.6) вычисляются значения / для каждой группь< хозяйств по формуле (для интервальных рядов):
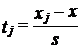 - для начала и конца интервала.
- для начала и конца интервала.
2. Вычисляется вероятность попадания единицы наблюдения в данный интервал при выполнении гипотезы о нормальном законе:
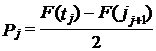 ,
,
где |tj| > |tj+1|
3. Определяется теоретическая частота в данной группе, равная произведению объема совокупности на вероятность попадания в данный интервал:
![]()
4. Находится значение критерия c2 по формуле
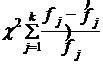 (7.28)
(7.28)
где k — число категорий ряда распределения;
j - номер категории;
fj - частота эмпирического распределения;
f̂j - частота теоретического распределения.
При расчете c2 частоты можно заменить частостями:
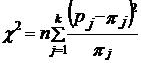 (7.29)
(7.29)
где pj - частости эмпирического распределения;
pj - вероятности теоретического распределения.
При этом, согласно Ф. Йейтсу (Jates), группы с теоретическими частотами менее 5 принято объединять, что снижает влияние случайных ошибок (см. [6]).
Если все эмпирические частоты равны соответствующим теоретическим частотам, то c2 равно нулю. Очевидно, что чем больше отличаются эмпирические и теоретические частоты, тем c2 больше; если расхождение несущественно, то c2 должно быть малым. Имеются специальные таблицы критических значений c2 при 5%-ном и 1%-ном уровнях значимости. Критические значения зависят от числа степеней свободы (d. f. - degrees of freedom) и уровня значимости.
Число степеней свободы рассчитывается так: если эмпирический ряд распределения имеет k категорий, то k эмпирических частот f1, f2, …, fk должны быть связаны следующим соотношением: ![]() Если параметры теоретического распределения известны, то только k - 1 частот могут принимать произвольные значения, т. е. свободно варьировать, а последняя частота может быть найдена из указанного соотношения. Поэтому говорят, что система из k частот благодаря наличию одной связи теряет одну «степень свободы» и имеет только k — 1 степеней свободы. Кроме того, если при нахождении теоретических частот р параметров теоретического распределения неизвестны, то они должны быть найдены по данным эмпирического ряда. Это накладывает на эмпирические частоты еще р связей, благодаря чему система теряет еще р степеней свободы. Таким образом, число свободно варьируемых частот (а значит, и число степеней свободы) становится равным:
Если параметры теоретического распределения известны, то только k - 1 частот могут принимать произвольные значения, т. е. свободно варьировать, а последняя частота может быть найдена из указанного соотношения. Поэтому говорят, что система из k частот благодаря наличию одной связи теряет одну «степень свободы» и имеет только k — 1 степеней свободы. Кроме того, если при нахождении теоретических частот р параметров теоретического распределения неизвестны, то они должны быть найдены по данным эмпирического ряда. Это накладывает на эмпирические частоты еще р связей, благодаря чему система теряет еще р степеней свободы. Таким образом, число свободно варьируемых частот (а значит, и число степеней свободы) становится равным:
d. f. = (k - 1) - р = k - (р + 1). (7.30)
Полученное значение критерия c2 сравнивается с табличным при числе степеней свободы, равном числу групп (с условием Ф. Йейтса), за минусом трех - по числу фиксированных параметров в формуле нормального закона распределения и с учетом равенства сумм теоретических и фактических частот (см. приложение, табл. 4).
В первой графе этой таблицы дано число степеней свободы, а в заголовках граф - уровни значимости. Если фактическое значение c2 превышает табличное при том же числе степеней свободы, то вероятность соответствия распределения нормальному закону меньше указанной. Результаты расчета c2 по данным табл. 5.6 (глава 5) приведены в табл. 7.5 при х = 30,3; s = 8,44.
Сумма теоретических частот нормального распределения меньше суммы фактических частот, так как нормальный закон не ограничен рамками фактических минимума и максимума.
Число групп после объединения малочисленных составило 7. Критическое значение c2 по табл. 4 приложения при 7-3 = 4 степеням свободы и значимости 0,05 составляет 9,49. Значит, вероятность расхождения распределения с нормальным меньше 0,05, и вероятность соответствия его нормальному закону больше 0,95. Табличное значение c2 для значимости 0,1 равно 7,78, что также больше фактического.
Таблица 7.5
Проверка соответствия распределения хозяйств по урожайности
зерновых культур нормальному закону
Группы хозяйств | fj | tj | tj + i | Рj | f̂j | (fj - f̂j)2/ f̂̂2j |
1 | 6 | -2,41 | -1,81 | 0,0235 | 3 | 0,071 |
2 | 9 | -1,81 | -1,22 | 0,0798 | 11 | |
3 | 20 - | -1,22 | -0,63 | 0,1531 | 22 | 0,182 |
4 | 41 | -0,63 | -0,04 | 0,2197 | 32 | 2,531 |
5 | 26 | -0,04 | 0,56 | 0,2282 | 33 | 1,485 |
6 | 21 | 0,56 | 1,15 | 0,1627 | 23 | 0,174 |
7 | 14 | 1,15 | 1,74 | 0,0842 | 12 | 0,333 |
8 | 5 | 1,74 | 2,33 | 0,0310 | 4 | 0,200 |
9 | 1 | 2,33 | 2,93 | 0,0082 | 1 | |
S | 143 | ´ | ´ | 0,9904 | 141 | 4,976 |
Ясно, что гипотеза о соответствии распределения хозяйств по урожайности нормальному закону не может быть отклонена.
Какое практическое значение может иметь произведенная проверка гипотезы? Во-первых, соответствие нормальному закону позволяет прогнозировать, какое число хозяйств (или доля совокупности) попадает в тот или иной интервал значений признака. Во-вторых, нормальное распределение возникает при действии на вариацию изучаемого показателя множества независимых факторов. Из этого следует, что нельзя существенно снизить вариацию урожайности, воздействуя только на один-два управляемых фактора, скажем удобрения или энергозатраты.
С помощью критерия c2 можно проверять не только гипотезу о согласии эмпирического распределения с нормальным законом, но и с любым другим известным законом распределения - равномерным распределением, распределением Пуассона и т. д. Например, суд рассматривает жалобу посетителей казино на то, что, по их мнению, игральная кость, которой там пользуются, фальшива, некоторые числа очков, якобы, выпадают чаще, чем другие, и этим пользуются крупье, обирающие игроков.
Суд назначает экспертизу игральной кости: эксперт делает 600 бросков и записывает число выпавших единиц, двоек, троек и т. д.
Полученное эмпирическое распределение сравнивается с теоретическим, т. е. равномерным: в правильной кости вероятность выпадения каждого числа очков должна быть равна 1/6, при 600 бросках это даст по 100 выпадений каждого числа очков. С помощью критерия c2 проверяется нулевая гипотеза о том, что различия эмпирического и теоретического распределений случайны, т. е. не являются систематическим результатом фальсификации формы кости или положения центра тяжести в ней; H0 : fфакт = fтеор. Результаты испытания и расчет у приводятся в табл. 7.6.
Таблица 7.6
Результаты испытания игральной кости
Число очков 1 2 3. 4 5 6 Итого | Количество выпадений, fфакт 101 86 107 94 97 117 600 | fтеор 100 100 100 100 100 100 600 | fфакт - fтеор 1 -14 7 -6 -3 17 0 | (fфакт- fтеор)2= fтеор 0,01 1,96 0.49 0,36 0.09 2,89 5,80 |
Табличное значение c2 при уровне значимости 0,05 (это вероятность ошибочного отклонения нулевой гипотезы при условии, что она верна) и при 6-2=4 степенях свободы (фиксировано 2 параметра: сумма числа бросков 600 и вероятность каждого числа очков - 1/6) составляет 9,49. Вычисленное значение c2 =5,8, что значительно ниже табличного. Следовательно, нулевая гипотеза не отклоняется: распределение бросков по числу выпавших очков нельзя считать неравномерным. Обвинение игроков против служащих казино не подтверждено достаточно надежно, но не доказано и то, что кость правильная. Можно назначить более дорогую экспертизу - сделать бросков кости, но можно и согласиться, что вероятность ошибочного признания правильности кости мала - всего 5% - и отклонить обвинение.
Выбор закона распределения проводится на основе теоретического анализа. Кроме того, целесообразно руководствоваться следующей рекомендацией: выражение, определяющее функцию плотности распределения, должно зависеть от возможно меньшего числа параметров. Например, экспоненциальное распределение зависит от одного параметра - средней величины; нормальное и логнормальное распределение - от двух параметров.
7.10. Проверка гипотезы о связи на на основе
критерия c2 (хи-квадрат)
Одним из основных приложений критерия c2 является его использование при анализе таблиц сопряженности двух переменных для установления факта наличия и уровня значимости взаимосвязи. Как правило, критерий у2 применяется для анализа таблиц сопряженности номинальных признаков, однако" он может быть использован и при анализе взаимосвязи порядковых или интервальных (количественных) переменных, несмотря на то, что для последних. случаев существуют более мощные тесты.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
