

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
К сожалению, большинство распределений торговых P&L плохо описываются функциями нормального и других распределений. В этой главе мы сначала обратимся к проблеме неопределенной природы распределения торговых P&L и далее изучим метод планирования сценария — естественное продолжение идеи оптимального/. Этот метод широко применяется и позволяет находить оптимальное f по ячеистым распределениям. Далее мы перейдем к следующей главе, посвященной опционам и одновременной торговле по нескольким позициям. Прежде чем смоделировать реальное распределение торговых P&L, мы должны найти метод сравнения двух распределений.
Тест Колмогорова-Смирнова (К-С)
Хи-квадрат тест, без сомнения, является наиболее популярным из всех методов сравнения двух распределений. Так как многие ориентированные на рынок приложения, помимо рассматриваемых в этой главе, часто используют хи-квадрат тест, то он описан в Однако для наших целей наилучшим методом будет тест К-С. Этот очень эффективный тест применим к неячеистым распределениям, которые являются функцией одной независимой переменной (в нашем случае, прибыль за одну сделку).
Все функции распределения вероятности имеют минимальное значение 0 и максимальное значение 1. То, как они ведут себя между ними, и отличает их. Тест К-С измеряет очень простую переменную D, которая определяется как максимальное абсолютное значение разности между двумя функциями распределения вероятности. Тест К-С достаточно прост. N объектов (в нашем случае сделок) нормируются (вычитается среднее значение, и полученная разность делится на стандартное отклонение) и сортируются в порядке возрастания. Когда мы проходим эти отсортированные и нормированные сделки, накопленная вероятность рассматриваемого количества сделок делится на N. Когда мы берем первую сделку в отсортированной последовательности с наименьшим стандартным значением, функция распределения вероятности (cumulative density function, далее — ФРВ) равна 1/N. Для каждого стандартного значения, которое мы проходим, приближаясь к наибольшему стандартному значению, к числителю прибавляется единица. В конце последовательности наша ФРВ будет равна N/N, или 1. Для каждого стандартного значения мы можем рассчитать теоретическое распределение. Таким образом, мы можем сравнить фактическую функцию распределения вероятности с любой теоретической функцией распределения вероятности. Переменная D, или статистика К-С (К-С statistic), равна наибольшему расстоянию между значением нашей фактической функции распределения вероятности и значением теоретического распределения ФРВ при этом же стандартном значении. При сравнении фактической ФРВ для данного стандартного значения с теоретической ФРВ для этого же стандартного значения мы должны также сравнить теоретическую ФРВ предыдущего стандартного значения с фактической ФРВ текущего стандартного значения.
Для того чтобы прояснить эту ситуацию, посмотрим на рисунок 4-1. Отметьте. что в точке А фактическая кривая находится выше теоретической. Поэтому мы сравниваем текущее значение фактической ФРВ с текущим теоретическим значением для нахождения наибольшей разности. Однако в точке В фактическая кривая находится ниже теоретической. Поэтому мы сравниваем предыдущее фактическое значение с текущим теоретическим значением. Идея состоит в том, что в результате мы выберем наибольшую разность.
Для каждого стандартного значения нам надо взять абсолютное значение разности между текущим значением фактической ФРВ и текущим значением теоретической ФРВ. Нам также надо взять абсолютное значение разности между предыдущим значением фактической ФРВ и текущим значением теоретической ФРВ. Повторив эту операцию для всех стандартных значений точек, где фактическая ФРВ делает скачок вверх на 1/N, и взяв наибольшую разность, мы определим переменную D.
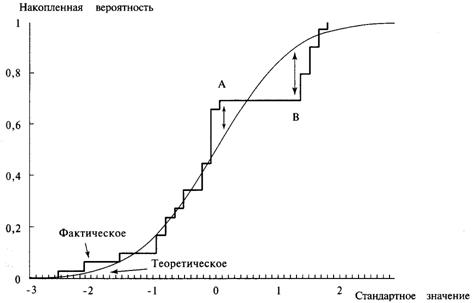
Рисунок 4-1 Тест К-С
Чем ниже значение D, тем больше похожи два распределения. Мы можем преобразовать значение D в уровень значимости с помощью следующей формулы:
![]()
где SIG = уровень значимости для данного D и N;
D = статистика К-С;
N = количество сделок, по которым определена статистика К-С;
% = оператор, означающий остаток после деления. Здесь J%2 дает остаток после деления J на 2;
ЕХР() = экспоненциальная функция.
Нет необходимости суммировать значения J от 1 до бесконечности. Уравнение сходится (обычно очень быстро) к определенному значению. После того как предел достигнут (согласно допуску, установленному пользователем), нет необходимости продолжать суммирование значений.
Рассмотрим уравнение (4.01) на примере. Допустим, у нас есть 100 сделок, а значение статистики К-С равно 0,04:
J1 = (1 % 2) * 4 - 2 * ЕХР(-2 * 1^2 * (100^(1/2) * 0,04) л 2) =1*4-2* ЕХР(-2 * ^ 2 * (10 * 0,04)^ 2) = 2 * ЕХР(-2 * 1^2 * 0,^ 2) = 2*ЕХР(-2*1*0,16) = 2 * ЕХР(-0,32) = 2 * 0,726149 = 1,452298
Таким образом, нашим первым значением является 1,452298. Теперь прибавим следующее значение:
J2 = (2 % 2) * 4 - 2 * ЕХР(-2 * 2^ 2 * (100^ (1/2) * 0,04)^2) =0*4-2* ЕХР(-2 * 2^ 2 * (10 * 0,04)^ 2) = -2 * ЕХР(-2 * 2^ 2 * 0,4^ 2) = -2*ЕХР(-2*4*0,16) = -2*ЕХР(-1,28) = -2 * 0,2780373 = -0,5560746
Прибавив -0,5560746 к нашей текущей сумме 1,452298, мы получим новую текущую сумму 0,8962234. Затем снова увеличим J на 1, теперь оно будет равно 3, и решим уравнение. Получившееся значение прибавим к текущей сумме 0,8962234. Следует поступать таким образом и дальше, пока текущая сумма в пределах допуска не перестанет изменяться. В нашем примере предельное значение будет равно 0,997. Этот ответ означает, что при 100 сделках и значении статистики К-С 0,04 мы можем быть уверены на 99,7%, что фактическое распределение генерировано функцией теоретического распределения. Другими словами, мы можем быть на 99,7% уверены, что функция теоретического распределения представляет фактическое распределение. В данном случае это очень хороший уровень значимости.
Создание характеристической функции распределения
Нормальное распределение вероятности далеко не всегда является хорошей моделью распределения торговых прибылей и убытков. Более того, ни одно из распространенных распределений вероятности не является идеальной моделью. Поэтому мы должны сами создать функцию для моделирования распределения наших торговых прибылей и убытков.
Распределение изменений цены в общем случае относится к распределениям Парето (см. приложение В). Распределение торговых P&L можно считать трансформацией распределения цен. Эта трансформация является результатом торговых методов, когда трейдеры пытаются понизить свои убытки и увеличить прибыли, следовательно, распределение торговых P&L можно отнести к распределениям Парето. Однако распределение, которое мы будем изучать, не является распределением Парето. Распределение Парето, как и все другие функции распределения, моделирует определенное вероятностное явление. Оно моделирует распределение сумм независимых, идентично распределенных случайных переменных. Функция распределения, которую мы будем изучать, не моделирует конкретное вероятностное явление. Она моделирует многие унимодальные функции распределения. Поэтому она может повторить форму и плотность вероятности распределения Парето, а также любого другого унимодального распределения.
Теперь мы создадим эту функцию. Для начала рассмотрим следующее уравнение:
(4.02) Y=1/(X^ 2+1)
График этого уравнения — обычная колоколообразная кривая, симметричная относительно оси Y, как показано на рисунке 4-2.
Таким образом, мы будем строить свои рассуждения, используя это общее уравнение. Переменную Х можно представить как число стандартных единиц с каждой стороны от среднего, т. е. от оси Y. Мы можем использовать первый момент этого «распределения», расположение его среднего значения, добавив значение для изменения расположения на оси X. Уравнение изменится следующим образом:
(4.03) Y=1/(X-LOC^2+1),
где Y = ордината характеристической функции;
Х = количество стандартных отклонений;
LOC = переменная, задающая расположение среднего значения, первый момент распределения.

Рисунок 4-2 LOC = 0 SCALE = I SKEW = 0 KURT = 2
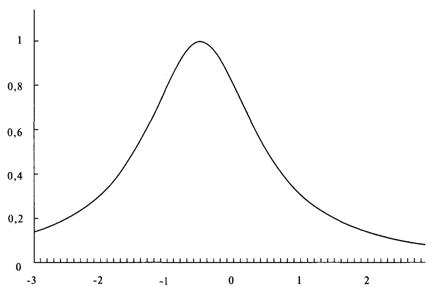
Рисунок 4-3 LOC =0,5, SCALE = 1, SKEW = 0, KURT= 2
Таким образом, если бы мы хотели изменить расположение, передвинув график влево на 0,5 единицы, мы бы установили LOC на -0.5. Этот график изображен на рисунке 4-3.
Таким же образом, если бы мы хотели сместить кривую вправо, то использовали бы положительное значение для переменной LOC. LOC с нулевым значением не будет смещать график, как показано на рисунке 4-2.
Показатель в знаменателе влияет на эксцесс. До настоящего момента эксцесс был равен 2, но мы можем изменить его, изменив значение показателя. Теперь формулу нашей характеристической функции можно записать следующим образом:
(4.04) Y = 1 / ((X - LOC)^ KURT + 1),
где Y == ордината характеристической функции;
Х = количество стандартных отклонений;
LOC = переменная, задающая расположение среднего значения, первый момент распределения;
KURT = переменная, задающая эксцесс, четвертый момент распределения.
Рисунки 4-4 и 4-5 показывают влияние эксцесса на нашу характеристическую функцию. Отметьте: чем выше показатель, тем более плосковерхое и тонкохвостое распределение (эксцесс меньше нормального), и чем меньше показатель, тем более острый верх и тем толще хвосты распределения (эксцесс больше нормального). Чтобы не получить иррациональное число, когда KURT < 1, мы будем использовать абсолютное значение коэффициента в знаменателе. Это не повлияет на форму кривой. Таким образом, мы можем переписать уравнение (4.04) следующим образом:
(4.04) Y = 1/(ABS(X - LOC)^ KURT + 1)
Мы можем добавить множитель в знаменателе, чтобы контролировать ширину, второй момент распределения. Характеристическая функция будет выглядеть следующим образом:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
