

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Ответы на вопросы, касающиеся онлайн-купоны, показали, что респонденты, в целом, сравнительно плохо осведомлены об использовании онлайн-купонов: чуть больше трети указали (31%) указали, что впервые слышат про онлайн-купоны, другая треть (32%) отметила, что слышала про онлайн-купоны, но их не получала (Рис.25). Среднее значение на вопрос о том, подтолкнет ли полученный купон примерить одну из вещей бренда Zara, составлял 3,3, однако среднее по уровню готовности респондента купить одну из вещей по полученному промокоду, составляло 3 (Рис.26).
Следующий раздел был посвящен исследованию влияния SMM на формирование отношения к бренду. В социальной сети «Вконтакте» большинство (86% респондентов) отметили, что не знакомы с официальной группой бренда (Рис.27). Если в вопросах, касающихся имиджа бренда, отметок «нравится» и воспринимаемого качества, средние оказались больше 3 (3,5; 3,0; 3,0 - соответственно), то вопросы, которые затрагивали уже более высокий уровень вовлечения потребителей – «я бы активно следил(а) за новостями группы /поделил (ся/лась) бы постами на своей странице», средние уже были меньше 3 (2,3; 1,7) (Рис.28). Примерно такая же статистика наблюдалась и в социальной сети «Instagram» (Рис.29,30).
Респонденты не дали однозначного ответа на вопрос о том, обращают ли они внимание на видео рекламу понравившихся им брендов (39% респондентов – «скорее да, чем нет», 25,5% - «скорее нет, чем да») (Рис.31). Средние в утверждениях, посвященных оценке имиджа бренда, воспринимаемого качества и подписки на канал бренда, были распределены аналогичным образом, как и в социальных сетях «Вконтакте» и «Instagram» (Рис.33).
Увиденная цифровая вывеска оказывает влияние следующим образом: респонденты скорее были «согласны», нежели «затруднялись ответить» на вопрос о том, обратили ли бы они внимание на подобную цифровую вывеску (среднее значение – 3,3), и если среднее значение на вопрос о том, возникнет ли у респондента желание зайти в этот отдел было равно 2,8, то среднее для утверждения: «я бы заш(ел/ла), если бы мне понравилась конкретно вещь на баннере» достигало 3,2 (Рис.34,35,36).
В конце опроса (шкала Лайкерта, 1- полностью не согласен, 3 - затрудняюсь ответить, 5 - полностью согласен), цель которых была изучить, насколько хорошо респонденты осведомлены о бренде, его имидже, насколько высоко оценивают качество товара, готовы ли рекомендовать данный бренд своим друзьям, и насколько сильно намерение о покупке ответы распределились следующим образом.
В конце опроса респондентам было предложено оценить осведомленность о бренде, его уровень качества, то, насколько хорошо они его знают и в какой степени ему привержены, то (Рис.37):
- уровень осведомленности был равен 3,8;
- уровень воспринимаемого качества - 3,1;
- уровень лояльности бренду Zara респонденты оценили, как 2,6;
- в утверждении, где оценивалось желание потребителя примерить одну из вещей Zara после просмотра предложенных цифровых решений, было равно 3,6.
Создание агрегированных переменных
Так как некоторые переменные измерялись несколькими вопросами, то в начале необходимо было агрегировать наблюдаемые переменные.
Переменные были агрегированы следующим образом:
- были отобраны переменные, которые измеряют латентную;
- была проведена проверка пригодности и валидности шкалы, используемой для измерения латентной переменной;
Для проверки пригодности был проведен анализ надежности. Одним из главных критериев являлся коэффициент Альфа Кронбаха (больше 0,7) для того, чтобы обеспечить достаточный уровень согласованности элементов, характеризующих один фактор. Вывод проверки надежности и валидности шкал представлен в Приложении 5. Создание агрегированных переменных в SPSS. Все шкалы оказались надежными, и поэтому все элементы были включены при создании агрегированных переменных.
- создание усредненной переменной.
После проверки валидности и надежности были созданы усредненные переменные. Эти переменные представлены в Приложении 5. Создание агрегированных переменных в SPSS.
Регрессионный анализ и проверка гипотез
Затем был проведен регрессионный анализ на основе данных опроса.
Перед проведением множественной регрессии следует сказать о том, что проводимое исследование соответствует следующим необходим условиям:
- анализ регрессии проводится для связанных по смыслу величин, в отношении которых уже выдвинуты гипотезы и предположения, а также проведен ряд исследований;
- достаточные размеры выборки для признания существующих корреляций значимыми;
- распределение значений предикторов, независимых переменных, которыми выступают рассматриваемые цифровые решения, близки к нормальному.
Таким образом, регрессионный анализ выполнялся следующим образом:
- Проведение корреляционного анализа для выявления значимых факторов;
- Линейная регрессия, анализ качества модели до корректировки;
- Анализ выбросов, если есть такая необходимость, и проведение повторного регрессионного анализа;
- Анализ качества модели после корректировки;
- Интерпретация коэффициентов.
Кроме того, важно отметить, что для каждой модели выполняются условия отсутствия мультиколлинеарности, гомоскедатичность, нормальное распределение ошибок и независимость наблюдений.
Так, при проверке условий генерализации был проведен первоначальный корреляционный анализ. На основе корреляционной таблицы, были оставлены только сильно коррелирующие независимые переменные. Те, которые оказались незначимыми, не присутствовали в дальнейшем в регрессионной модели и были исключены из нее, а анализ был проведен еще раз. Для отсутствия мультиколлинеарности допуски и показатели VIF во всех моделях соответствовали допустимым: > 0,2 и <10, соответственно. Показатели обусловленности являлись < 15.
Гомоскедастичность оценивалась по диаграмме рассеяния, а нормальное распределение ошибок во всех моделях показало, что распределение остатков близко к нормальному. Независимость наблюдений оценивалась по коэффициенту Дарбина-Ватсона (от 1,5 до 2,5).
После проверки условий генерализации были построены четыре регрессионные модели, где в каждой модели было удалено по одному выбросу для улучшения скорректированного R^2. Однако, учитывая, что в данных моделях рассматривались только определенные цифровые инструменты из всего множества цифровых решений, и оценивались только данные эффекты, скорректированные R^2 в моделях были небольшими, и модели получились не слишком высокого качества.
Так как в выборке 99% стандартных остатков должны лежать в пределах +/- 2,5 среднеквадратического отклонения, а выборка составляла 105 респондентов, то в каждой модели было удалено по одному выбросу (1% от выборки), который был больше, чем 2,5. Затем, после удаления выбросов, анализ был проведен еще раз, после чего скорректированный R^2 был улучшен.
Подробные результаты указаны в Приложении 6. Построение регрессионных моделей в SPSS. С помощью регрессионного анализа в SPSS, соответствующее уравнению множественной регрессии, выявлены те предикторы, влияние которых является наиболее значимо. Кроме того, в уравнение в качестве предиктора были включены и контрольные переменные (пол, доход, опыт использования брендом), чтобы посмотреть их (не)значимый эффект влияния. Однако эти контрольные переменные оказали незначимый эффект влияния, поэтому были исключены из основных моделей.
В Таб. 7 указаны результаты по всем четырем моделям по каждой из независимых переменных: осведомленность о бренде (BR_AW), воспринимаемое качество (BR_PQ), лояльность бренду (BR_BL) и намерение о покупке (BR_PI), где значимость (p) у коэффициентов – указана, как p < 0,001 ***, 0,001 < p < 0,05 **, p > 0,05 *, а в скобках дана t-статистика. То есть в моделях те коэффициенты, которые имели значимость p < 0,001, имели значимый эффект влияния.
Так, регрессионные уравнения выглядят следующим образом (знаком (*) отмечены статистически значимые коэффициенты):
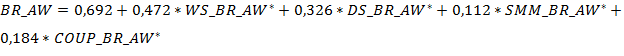
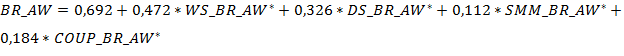 (2), где
(2), где
![]()
![]() – осведомленность о бренде,
– осведомленность о бренде, ![]()
![]() – измерение осведомленности бренда на основе веб-сайта,
– измерение осведомленности бренда на основе веб-сайта, ![]()
![]() - измерение осведомленности бренда на основе цифровых вывесок,
- измерение осведомленности бренда на основе цифровых вывесок, ![]()
![]() - измерение осведомленности бренда на основе SMM,
- измерение осведомленности бренда на основе SMM, ![]()
![]() - измерение осведомленности бренда на основе онлайн-купонов.
- измерение осведомленности бренда на основе онлайн-купонов.
Подтвердились гипотезы о положительном влиянии цифровых вывесок (H1б) и (Н1в). Гипотеза о положительном влиянии SMM (H1a) и предположение о положительном влиянии онлайн-купонов (Р1д) не подтвердились.
![]()
![]() (3), где
(3), где
![]()
![]() – воспринимаемое качество,
– воспринимаемое качество, ![]()
![]() – измерение воспринимаемого качества на основе веб-сайта,
– измерение воспринимаемого качества на основе веб-сайта, ![]()
![]() – измерение воспринимаемого качества на основе SMM.
– измерение воспринимаемого качества на основе SMM.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
