


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2. Между объясняющими переменными не должно существовать строгой линейной зависимости, т. е. предполагается отсутствие мультиколлинеарности.
3. Зависимая переменная Y и объясняющие параметры Хi распределены нормально.
4. Регрессоры являются неслучайными величинами.
5. При построении функции регрессии предполагается, что результативный признак Y зависит только от объясняющих переменных Хi, которые включены в регрессию. Таким образом, предполагается, что на переменную Y не оказывают влияния никакие другие систематически действующие факторы. Суммарный эффект от воздействия на зависимую переменную неучтенных факторов учитывается возмущающей переменной ε. При этом предполагается, что математическое ожидание возмущающей переменной ε равно ![]() .
.
6. Объясняющие переменные не коррелируют с возмущающей переменной ε, т. е. ![]() =0. Отсюда следует, что переменные Хi объясняют переменную Y, а переменная Y не объясняет переменные Хi.
=0. Отсюда следует, что переменные Хi объясняют переменную Y, а переменная Y не объясняет переменные Хi.
7. Распределение возмущающей переменной подчиняется нормальному закону распределения.
8. Возмущаюшая переменная ε имеет постоянную дисперсию ![]() . Это свойство возмущающей переменной называется гомоскедастичностью.
. Это свойство возмущающей переменной называется гомоскедастичностью.
9. Значения возмущающей переменной ε попарно некоррелированы, т. е. ![]() для s≠0. Иначе это свойство называется отсутствием автокорреляции возмущающей переменной ε.
для s≠0. Иначе это свойство называется отсутствием автокорреляции возмущающей переменной ε.
Для нахождения оценок неизвестных параметров ![]() и
и ![]() двумерного линейного уравнения регрессии
двумерного линейного уравнения регрессии ![]() используется метод наименьших квадратов. В соответствии с МНК оценки
используется метод наименьших квадратов. В соответствии с МНК оценки ![]() и
и ![]() можно получить из условия минимизации суммы квадратов ошибок оцениваемых параметров, т. е. суммой квадратов отклонений фактических значений зависимой переменной от ее расчетных значений, полученных на основе уравнения регрессии:
можно получить из условия минимизации суммы квадратов ошибок оцениваемых параметров, т. е. суммой квадратов отклонений фактических значений зависимой переменной от ее расчетных значений, полученных на основе уравнения регрессии:
![]() , (11.22)
, (11.22)
где ![]() и
и ![]() - оценки неизвестных параметров
- оценки неизвестных параметров ![]() и
и ![]() соответственно;
соответственно;
![]() - расчетные значения зависимой переменной
- расчетные значения зависимой переменной ![]() .
.
Разность ![]() называется остатком и дает количественную оценку воздействия возмущающей переменной ε.
называется остатком и дает количественную оценку воздействия возмущающей переменной ε.
Дифференцируя функционал S по ![]() и
и ![]() и приравнивая нулю частные производные, получаем следующую систему уравнений:
и приравнивая нулю частные производные, получаем следующую систему уравнений:
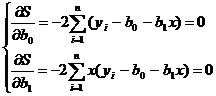 (11.23)
(11.23)
После соответствующих преобразований имеем:
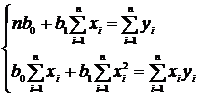 (11.24)
(11.24)
Решив данную систему относительно![]() и
и ![]() , окончательно получим:
, окончательно получим:
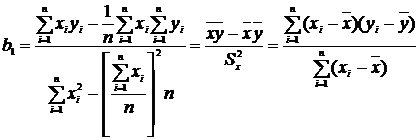 ; (11.25)
; (11.25)
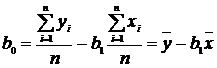 . (11.26)
. (11.26)
Свободный член уравнения регрессии ![]() определяет точку пересечения линии регрессии с осью ординат.
определяет точку пересечения линии регрессии с осью ординат. ![]() является средним значением Y в точке Х=0 и задает масштаб изменения зависимой переменной Y. Коэффициент
является средним значением Y в точке Х=0 и задает масштаб изменения зависимой переменной Y. Коэффициент ![]() имеет размерность зависимой переменной. Его экономическая интерпретация очень затруднительна или вообще невозможна. Коэффициент
имеет размерность зависимой переменной. Его экономическая интерпретация очень затруднительна или вообще невозможна. Коэффициент ![]() показывает среднюю величину изменения зависимой переменной Y при изменении объясняющей переменной Х на одну единицу своего измерения. Знак при
показывает среднюю величину изменения зависимой переменной Y при изменении объясняющей переменной Х на одну единицу своего измерения. Знак при ![]() показывает направление изменения. При положительном коэффициенте регрессии увеличение значений объясняющей переменной ведет к увеличению значений зависимой переменной. При отрицательном коэффициенте увеличение значений объясняющей переменной ведет к убыванию значений зависимой переменной.
показывает направление изменения. При положительном коэффициенте регрессии увеличение значений объясняющей переменной ведет к увеличению значений зависимой переменной. При отрицательном коэффициенте увеличение значений объясняющей переменной ведет к убыванию значений зависимой переменной.
После нахождения оценок ![]() и
и ![]() неизвестных параметров
неизвестных параметров ![]() и
и ![]() необходимо осуществить проверку значимости параметров регрессии и всего уравнения в целом, а также построить доверительные интервалы для оцениваемых параметров и интервал прогнозирования для независимой переменной.
необходимо осуществить проверку значимости параметров регрессии и всего уравнения в целом, а также построить доверительные интервалы для оцениваемых параметров и интервал прогнозирования для независимой переменной.
Для проверки значимости уравнения регрессии в случае двумерной модели выдвигается гипотеза Н0: ![]() =0. В основе проверки лежит идея дисперсионного анализа, состоящая в разложении дисперсии на составляющие. Общая сумма Sобщ квадратов отклонений зависимой переменной разлагается на сумму квадратов SR отклонений, обусловленных регрессией, которая характеризует воздействие объясняющей переменной, и сумму квадратов Sост отклонений относительно плоскости регрессии, характеризующую воздействие неучтенных в модели факторов.
=0. В основе проверки лежит идея дисперсионного анализа, состоящая в разложении дисперсии на составляющие. Общая сумма Sобщ квадратов отклонений зависимой переменной разлагается на сумму квадратов SR отклонений, обусловленных регрессией, которая характеризует воздействие объясняющей переменной, и сумму квадратов Sост отклонений относительно плоскости регрессии, характеризующую воздействие неучтенных в модели факторов.
Sобщ = SR + Sост, (11.27)
где Sобщ = 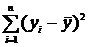 ; SR =
; SR = 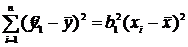 ; Sост
; Sост 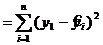 .
.
Проверка гипотеза основана на критерии 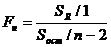 , (11.28)
, (11.28)
имеющем распределение Фишера-Снедекора.
Нулевая гипотеза отвергается, если ![]() оказывается больше, чем значение
оказывается больше, чем значение ![]() , найденное для уровня значимости α и числа степеней свободы
, найденное для уровня значимости α и числа степеней свободы ![]() =2 и n-2. В противном случае гипотеза принимается.
=2 и n-2. В противном случае гипотеза принимается.
Стоит отметить, что только для частного случая двумерной модели проверка значимости уравнения регрессии фактически сводится к проверке значимости единственного коэффициента регрессии ![]() (проверка значимости свободного члена, как правило, не проводится). В случае же многомерной модели, необходимо проверять как значимость отдельных коэффициентов, так и всего уравнения.
(проверка значимости свободного члена, как правило, не проводится). В случае же многомерной модели, необходимо проверять как значимость отдельных коэффициентов, так и всего уравнения.
Используя значение Sост, можно получить оценку остаточной дисперсии ![]() по формуле:
по формуле: 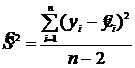 . (11.29)
. (11.29)
Остаточная дисперсия является одной из важных характеристик качества регрессионной модели. Чем меньше значение ![]() , тем ближе расчетные значения к фактическим, и, следовательно, тем точнее модель описывает изучаемый процесс.
, тем ближе расчетные значения к фактическим, и, следовательно, тем точнее модель описывает изучаемый процесс.
Еще одним важным показателем качества регрессионной модели является коэффициент детерминации, который для двухмерной рассчитывается по формуле:
![]() . (11.30)
. (11.30)
Если уравнение регрессии значимо, то представляет интерес определение с надежностью γ доверительных интервалов для ![]() ,
,![]() и
и ![]() .
.
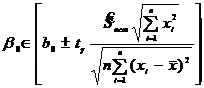 ; (11.31)
; (11.31)
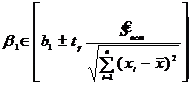 ; (11.32)
; (11.32)
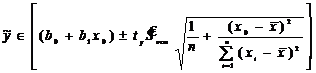 . (11.33)
. (11.33)
где ![]() определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы
определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы ![]() =2;
=2; ![]() - заданное значение Х, для которого находится интервальная оценка параметра
- заданное значение Х, для которого находится интервальная оценка параметра ![]() .
.
Доверительную оценку для интервала предсказания в точке Х= х0 определяют из условия 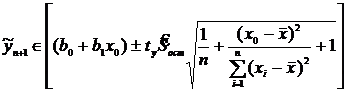 , (11.34)
, (11.34)
где ![]() определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы
определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы ![]() =n-2.
=n-2.
На практике для сравнительного анализа влияния разных факторов, входящих в регрессионную модель, используют коэффициенты эластичности и стандартизованные ![]() - коэффициенты. Их применение помогает устранить различие в единицах измерения объясняющих переменных. В многомерных моделях с большим количеством регрессоров с помощью данных коэффициентов можно ранжировать объясняющие переменные по степени их относительного влияния на зависимую переменную.
- коэффициенты. Их применение помогает устранить различие в единицах измерения объясняющих переменных. В многомерных моделях с большим количеством регрессоров с помощью данных коэффициентов можно ранжировать объясняющие переменные по степени их относительного влияния на зависимую переменную.
Коэффициент эластичности вычисляется по формуле: 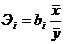 . (11.35)
. (11.35)
и показывает, на сколько процентов в среднем изменится результативный признак, если факторный признак (объясняющая переменная) увеличится на один процент при условии, что все другие факторные признаки равны своим средним значениям.
Стандартизованные коэффициенты ![]() помогают устранить различия в степени колеблемости объясняющих переменных:
помогают устранить различия в степени колеблемости объясняющих переменных: ![]() =
= ![]() . (11.36)
. (11.36)
Величина ![]() показывает, на сколько среднеквадратических отклонений изменится зависимая переменная при изменении объясняющей переменной на одно среднеквадратическое отклонение.
показывает, на сколько среднеквадратических отклонений изменится зависимая переменная при изменении объясняющей переменной на одно среднеквадратическое отклонение.
Множественная линейная модель. Для оценки неизвестных параметров линейной многомерной модели методом наименьших квадратов используется аппарат матричной алгебры.
В матричной форме уравнение ![]() имеет вид
имеет вид ![]() ,
,
где 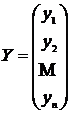 - вектор-столбец наблюдений размерности n;
- вектор-столбец наблюдений размерности n;
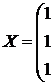
![]()
![]()
![]()
![]() - матрица факторных признаков размерности (n (m+1));
- матрица факторных признаков размерности (n (m+1));
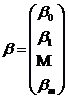 - вектор неизвестных параметров размерности (m+1).
- вектор неизвестных параметров размерности (m+1).
Оценка наименьших квадратов вектора ![]() имеет вид
имеет вид
![]() , (11.37)
, (11.37)
где 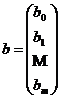 - вектор-столбец оценок размерности (m+1);
- вектор-столбец оценок размерности (m+1);
![]() - транспонированная матрица Х;
- транспонированная матрица Х;
![]() - матрица, обратная матрице
- матрица, обратная матрице ![]() .
.
Вектор ![]() является несмещенной оценкой
является несмещенной оценкой ![]() , т. е.
, т. е. ![]() .
.
Дисперсия оценки ![]() определяется из выражения
определяется из выражения
![]()
![]() , (11.38)
, (11.38)
где ![]() - диагональной элемент матрицы
- диагональной элемент матрицы ![]() , соответствующий l-строке и l-столбцу, l=
, соответствующий l-строке и l-столбцу, l= ![]() +1.
+1.
Значимость уравнения регрессии, т. е. гипотеза 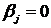 , проверяется с помощью критерия, основанного на статистике:
, проверяется с помощью критерия, основанного на статистике: 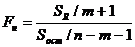 , (11.39)
, (11.39)
имеющей распределение Фишера-Снедекора с числом степеней свободы ![]() =m+1 и n – m – 1,
=m+1 и n – m – 1,
где ![]() - сумма квадратов отклонений, обусловленных регрессией;
- сумма квадратов отклонений, обусловленных регрессией;
![]() - сумма квадратов отклонений, характеризующая воздействие неучтенных в модели факторов.
- сумма квадратов отклонений, характеризующая воздействие неучтенных в модели факторов.
Нулевая гипотеза отвергается, если ![]() оказывается больше чем
оказывается больше чем ![]() , найденное для уровня значимости α и числа степеней свободы и
, найденное для уровня значимости α и числа степеней свободы и ![]() . В противном случае гипотеза принимается.
. В противном случае гипотеза принимается.
Значимость отдельных коэффициентов можно проверить с помощью критерия, основанного на статистике
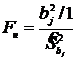 , где
, где ![]() =
=![]() , (11.40)
, (11.40)
имеющей распределение Фишера-Снедекора с числом степеней свободы ![]() =
=![]() и n – m – 1.
и n – m – 1.
Доверительный интервал для параметра ![]() имеет вид:
имеет вид: ![]() , (11.41)
, (11.41)
где ![]() определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы
определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы ![]() = n – m – 1.
= n – m – 1.
Интервальная оценка для ![]() в точке, определяемой вектором
в точке, определяемой вектором ![]() начальных условий, равна
начальных условий, равна
![]() , (11.42)
, (11.42)
где ![]() определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы
определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы ![]() = n – m – 1.
= n – m – 1.
Доверительная оценка для интервала предсказания ![]() определяется как
определяется как
![]() , (11.43)
, (11.43)
где ![]() определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы
определяется по таблице распределения Стьюдента для уровня значимости α=1-γ и числа степеней свободы ![]() = n – m – 1.
= n – m – 1.
12 Корреляционный анализ
Многомерный статистический анализ – раздел математической статистики, посвященный математическим методам построения оптимальных планов сбора, систематизации и обработки многомерных статистических данных, направленным на выявление характера и структуры взаимосвязей между компонентами исследуемого многомерного признака и предназначенным для получения научных и практических выводов. Под многомерным признаком понимается р-мерный вектор 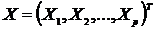 признаков
признаков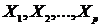 , среди которых могут быть количественные, порядковые и классификационные. Результаты измерения этих показателей
, среди которых могут быть количественные, порядковые и классификационные. Результаты измерения этих показателей ![]() на каждом из n объектов исследуемой совокупности образуют последовательность многомерных наблюдений, или исходный массив многомерных данных для проведения многомерного статистического анализа. В рамках многомерного статистического анализа многомерный признак х интерпретируется как многомерная случайная величина, и соответственно, последовательность многомерных наблюдений как выборка из генеральной совокупности.
на каждом из n объектов исследуемой совокупности образуют последовательность многомерных наблюдений, или исходный массив многомерных данных для проведения многомерного статистического анализа. В рамках многомерного статистического анализа многомерный признак х интерпретируется как многомерная случайная величина, и соответственно, последовательность многомерных наблюдений как выборка из генеральной совокупности.
К основным методам многомерного статистического анализа можно отнести кластерный анализ, дискриминантный анализ, компонентный анализ, факторный анализ и метод канонических корреляций. Данные методы имеют достаточно сложный математический аппарат и обычно являются частью статистических пакетов прикладных программ.
Кластерный анализ – это совокупность методов классификации многомерных наблюдений или объектов, основанных на определении понятия расстояния между объектами с последующим выделением из них групп, «сгустков» наблюдений (кластеров, таксонов). При этом не требуется априорной информации о распределении генеральной совокупности. Выбор конкретного метода кластерного анализа зависит от цели классификации. Кластерный анализ используется при исследовании структуры совокупностей социально-экономических показателей или объектов: предприятий, регионов, социологических анкет и т. д.
От матрицы исходных данных 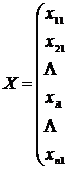
![]()
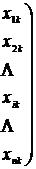 (12.1)
(12.1)
переходим к матрице нормированных значений Z c элементами 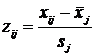 , (12.2)
, (12.2)
где j =1,2,…,k – номер показателя, i=1,2,…,n – номер наблюдения;
![]() =
=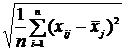 =
=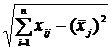 . (12.3)
. (12.3)
В качестве расстояния между двумя наблюдениями ![]() и
и ![]() используют «взвешенное» евклидово расстояние, определяемое по формуле:
используют «взвешенное» евклидово расстояние, определяемое по формуле:
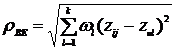 , где
, где ![]() -«вес» показателя;
-«вес» показателя; ![]() .
.
Если ![]() =1 для всех l=1,2,.k, то получаем обычное евклидово расстояние:
=1 для всех l=1,2,.k, то получаем обычное евклидово расстояние:
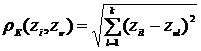 (12.4)
(12.4)
Полученные значения удобно представить в виде матрицы расстояний
![]()
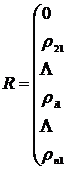
![]()
![]()
![]()
![]() (12.5)
(12.5)
Так как матрица R симметрическая, т. е. ![]() , то достаточно ограничиться записью наддиагональных элементов матрицы.
, то достаточно ограничиться записью наддиагональных элементов матрицы.
Используя матрицу расстояний, можно реализовать агломеративную иерархическую процедуру кластерного анализа. Расстояния между кластерами определяют по принципу «ближайшего соседа» или «дальнего соседа». В первом случае за расстояние между кластерами принимают расстояние между ближайшими элементами этих кластеров, а во втором - между наиболее удаленными друг от друга.
Принцип работы иерархических агломеративных процедур состоит в последовательном объединении групп элементов сначала самых близких, а затем все более отдаленных друг от друга. На первом шаге алгоритма каждое наблюдение ![]() ,
, ![]() , рассматривается как отдельный кластер. В дальнейшем на каждом шаге работы алгоритма происходит объединение двух самых близких кластеров, и вновь строится матрица расстояний, размерность которой снижается на единицу.
, рассматривается как отдельный кластер. В дальнейшем на каждом шаге работы алгоритма происходит объединение двух самых близких кластеров, и вновь строится матрица расстояний, размерность которой снижается на единицу.
Компонентный анализ предназначен для преобразования системы k исходных признаков в систему k новых показателей (главных компонент). Главные компоненты не коррелированны между собой и упорядочены по величине их дисперсий, причем первая главная компонента имеет наибольшую дисперсию, а последняя, k – я, - наименьшую.
В задачах снижения размерности и классификации обычно используется m первых компонент (![]() ). При наличии результативного показателя Y может быть построено уравнение регрессии на главных компонентах.
). При наличии результативного показателя Y может быть построено уравнение регрессии на главных компонентах.
Для простоты изложения алгоритма ограничимся случаем трех переменных.
На основании матрицы исходных данных
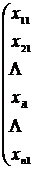
![]()
![]()
![]() ,
, ![]() (12.6)
(12.6)
вычисляем оценки параметров распределения трехмерной генеральной совокупности 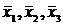 ,
, 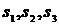 ,
, 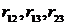 , где
, где ![]() =
=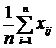 ;
; 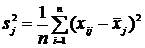 ;
;
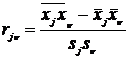 ;
; 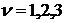 . (12.7)
. (12.7)
Получаем оценку матрицы парных коэффициентов корреляции: 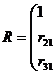
![]()
![]() .
.
Преобразуем матрицу R в диагональную матрицу ![]() собственных значений характеристического многочлена
собственных значений характеристического многочлена 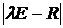 .
.
Характеристический многочлен имеет вид
![]() =
=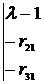
![]()
![]() =
=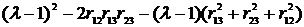 , (12.8)
, (12.8)
где E – единичная матрица.
Приняв ![]() , получим неполное кубическое уравнение
, получим неполное кубическое уравнение 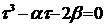 , (12.9)
, (12.9)
где 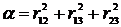 ,
, 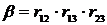 .
.
Решая это уравнение и учитывая выполнение неравенства 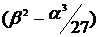 <0, получим:
<0, получим: 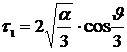 ,
, 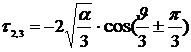 , (12.10)
, (12.10)
где 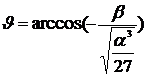 . (12.11)
. (12.11)
Отсюда получаем собственные значения ![]() , причем
, причем ![]() и матрицу собственных значений
и матрицу собственных значений 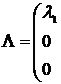
![]()
![]() . (12.12)
. (12.12)
Собственные значения характеризуют вклады соответствующих главных компонент в суммарную дисперсию исходных признаков ![]() . Таким образом, первая главная компонента оказывает наибольшее влияние на общую вариацию, а третья – наименьшее. При этом должно выполняться равенство
. Таким образом, первая главная компонента оказывает наибольшее влияние на общую вариацию, а третья – наименьшее. При этом должно выполняться равенство ![]() . Вклад l-й главной компоненты в суммарную дисперсию определяется по формуле
. Вклад l-й главной компоненты в суммарную дисперсию определяется по формуле 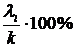 .
.
Найдем теперь матрицу преобразования V - ортогональную матрицу, составленную из собственных векторов матрицы R. Собственный вектор ![]() , отвечающий собственному числу
, отвечающий собственному числу ![]() , находим как отличное от нуля решение уравнения
, находим как отличное от нуля решение уравнения ![]() . Так как определитель
. Так как определитель ![]() =0, то можно считать, что третья строка есть линейная комбинация первых двух строк. Составим два уравнения
=0, то можно считать, что третья строка есть линейная комбинация первых двух строк. Составим два уравнения
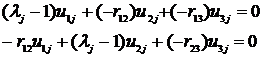 (12.13)
(12.13)
Примем ![]() и получим решение системы двух уравнений с двумя неизвестными.
и получим решение системы двух уравнений с двумя неизвестными.
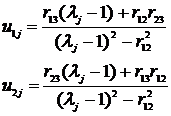 (12.14)
(12.14)
Тогда окончательно собственный вектор ![]() имеет вид
имеет вид
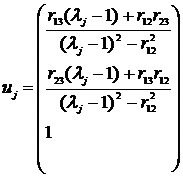 для
для ![]() j=1,2,3. (12.15)
j=1,2,3. (12.15)
Находим норму вектора ![]() . Тогда матрица V, составленная из нормированных векторов
. Тогда матрица V, составленная из нормированных векторов 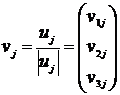 , (12.16)
, (12.16)
имеет вид 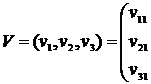
![]()
![]() (12.17)
(12.17)
и является ортогональной ![]() .
.
Матрица факторных нагрузок получается по формуле
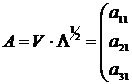
![]()
![]()
![]() , (12.18)
, (12.18)
где ![]() - диагональная матрица:
- диагональная матрица: 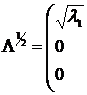
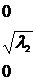
![]() (12.19)
(12.19)
Таким образом, нагрузка l-й главной компоненты ![]() на j-ю переменную
на j-ю переменную ![]() вычисляется по формуле:
вычисляется по формуле: ![]() ; j =1,2,3; l=1,2,3.
; j =1,2,3; l=1,2,3.
Элемент матрицы факторных нагрузок ![]() есть коэффициент корреляции, который измеряет тесноту связи между l-й главной компонентой и
есть коэффициент корреляции, который измеряет тесноту связи между l-й главной компонентой и ![]() -м признаком
-м признаком ![]() . При этом имеет место соотношение:
. При этом имеет место соотношение: ![]() .
.
Матрица факторных нагрузок A используется для экономической интерпретации главных компонент, которые представляют собой линейный функции исходных признаков. Значения главных компонент для каждого i-объекта ![]() задаются матрицей F. Матрицу значений главных компонент можно получить по формуле:
задаются матрицей F. Матрицу значений главных компонент можно получить по формуле:
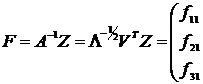
![]()
![]()
![]() , где (12.20)
, где (12.20)
Z- матрица нормированных значений наблюдаемых переменных ![]() размером
размером ![]() .
.
Таким образом, значения главных компонент получаем из выражения
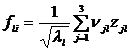 , (12.21)
, (12.21)
где 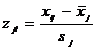 ,
, ![]() ; l=1,2,3.
; l=1,2,3.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
