


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Среднеквадратическое отклонение случайной величины выражается в тех же единицах, что и сама случайная величина и ее математическое ожидание.
Приведем без доказательств основные свойства дисперсии. Свойства среднеквадратического отклонения непосредственно вытекают из соответствующих свойств дисперсии.
1) Дисперсия постоянной с равна нулю: D(c)=0.
2) Дисперсия произведения случайной величины Х на постоянную с равна произведению дисперсии случайной величины Х на квадрат постоянной: ![]() .
.
3) Если случайные величины X иY независимы, то дисперсия их суммы равна сумме их дисперсий: ![]() .
.
4) Дисперсия случайной величины Х не изменится, если к ней прибавить постоянную с, т. е. ![]() .
.
Моменты случайной величины обобщают понятия математического ожидания и дисперсии.
Моментом k – порядка называется математическое ожидание k –й степени отклонения случайной величины Х от некоторой постоянной с.
Если в качестве с берется нуль, моменты называют начальными, то есть
![]() . (8.8)
. (8.8)
Если с=М(Х), то моменты называются центральными, то есть
. (8.9)
Таким образом, математическое ожидание – ни что иное, как первый начальный момент, а дисперсия – второй центральный момент.
Существует формула, связывающая центральные моменты с начальными:
![]() . (8.10)
. (8.10)
Для первых четырех моментов эта формула дает следующие равенства:
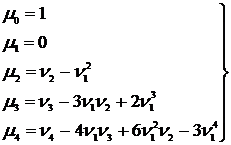 (8.11)
(8.11)
Формула ![]() может быть использована для нахождения дисперсии случайной величины:
может быть использована для нахождения дисперсии случайной величины: 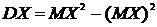 (8.12)
(8.12)
В теории и практических приложениях используют две числовые характеристики случайной величины, основанные на центральных моментах третьего и четвертого порядков соответственно – коэффициент асимметрии ![]() и эксцесс
и эксцесс ![]() . Данные коэффициенты дают представление о форме плотности распределения или многоугольника распределения.
. Данные коэффициенты дают представление о форме плотности распределения или многоугольника распределения.
Коэффициентом асимметрии случайной величины Х называется число, равное отношению третьего центрального момента к кубу среднеквадратического отклонения случайной величины Х:
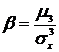 (8.13)
(8.13)
Коэффициент асимметрии случайной величины, закон распределения которой симметричен относительно математического ожидания, равен нулю, поскольку в этом случае ![]()
![]() . Если распределение вероятностей несимметрично, причем «длинная часть» распределения расположена справа от центра группирования, то
. Если распределение вероятностей несимметрично, причем «длинная часть» распределения расположена справа от центра группирования, то ![]() >0 и асимметрию называют положительной, если же «длинная часть» расположена слева, то
>0 и асимметрию называют положительной, если же «длинная часть» расположена слева, то ![]() <0 и асимметрию называют отрицательной.
<0 и асимметрию называют отрицательной.
В качестве характеристики большей или меньшей степени «сглаженности» плотности или многоугольника распределения по сравнению с нормальной плотностью используют понятие эксцесса. Эксцессом случайной величины Х называется число, равное разности отношения четвертого центрального момента к четвертой степени среднеквадратического отклонения случайной величины и числа 3:
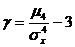 (8.14)
(8.14)
Эксцесс нормального закона распределения вероятностей равен нулю. Если распределение вероятностей случайной величины Х одномодально и плотность распределения ![]() более «островершинна», чем плотность распределения нормальной случайной величины с той же дисперсией, то
более «островершинна», чем плотность распределения нормальной случайной величины с той же дисперсией, то ![]() >0, если же
>0, если же ![]() менее «островершинна» и более «сглажена» по сравнению с плотностью соответствующего нормального распределения, то
менее «островершинна» и более «сглажена» по сравнению с плотностью соответствующего нормального распределения, то ![]() <0.
<0.
В математической статистике широко используются понятия q-квантилей ![]() и Q-процентных точек
и Q-процентных точек 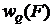 распределения F(x).
распределения F(x).
Квантилью уровня q (или q-квантилью) непрерывной случайной величины Х, обладающей непрерывной функцией распределения F(x), называется такое возможное значение ![]() этой случайной величины, для которого вероятность события Х <
этой случайной величины, для которого вероятность события Х <![]() равна заданной величине q, т. е.
равна заданной величине q, т. е.
![]() . (8.15)
. (8.15)
Очевидно, чем больше заданное значение q (0<q<1), тем больше будет и соответствующая величина квантили ![]() . Частным случаем квантили - 0.5 –квантилью является характеристика центра группирования - медиана.
. Частным случаем квантили - 0.5 –квантилью является характеристика центра группирования - медиана.
Для дискретной случайной величины функция q-квантиль определяется как любое число ![]() , лежащее между двумя значениями
, лежащее между двумя значениями ![]() и
и ![]() , такими, что
, такими, что ![]() < q, но
< q, но 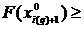 q.
q.
Под Q-процентной точкой (0< Q<100) случайной величины Х понимается такое ее возможное значение ![]() , для которого вероятность события Х
, для которого вероятность события Х ![]() , равна Q/100:
, равна Q/100:
![]() . (8.16)
. (8.16)
Для дискретной случайной величины это определение корректируется аналогично тому, как это делалось при определении квантилей.
Между квантилями и процентами точками существует следующее соотношение: ![]() .
.
Нормальное распределение (закон Гаусса) занимает центральное место в теории и практике статистических исследований. Распределение задается плотностью:
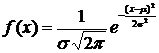 , (8.17)
, (8.17)
где ![]() - математическое ожидание;
- математическое ожидание; ![]() - среднеквадратическое отклонение.
- среднеквадратическое отклонение.
Кривая нормального распределения симметрична относительно прямой, параллельной оси ординат и проходящей через точку ![]() , и имеет в этой точке единственный максимум, равный
, и имеет в этой точке единственный максимум, равный![]() . С уменьшением
. С уменьшением ![]() кривая становится более вытянутой по отношению к прямой
кривая становится более вытянутой по отношению к прямой ![]() . Изменение
. Изменение ![]() при постоянном
при постоянном ![]() не меняет формы кривой, а вызывает лишь ее смещение вдоль оси абсцисс. Таким образом, нормальное распределение зависит от двух параметров:
не меняет формы кривой, а вызывает лишь ее смещение вдоль оси абсцисс. Таким образом, нормальное распределение зависит от двух параметров:![]() и
и ![]() . Площадь, заключенная под кривой нормального распределения, равна единице. Коэффициент асимметрии и эксцесс равны нулю.
. Площадь, заключенная под кривой нормального распределения, равна единице. Коэффициент асимметрии и эксцесс равны нулю.
Логарифмически-нормальное распределение (логнормальное распределение) – распределение положительной случайной величины, логарифм которой распределен по нормальному закону. Таким образом, если случайная величина Х распределена по нормальному закону, то случайная величина ![]() имеет логнормальное распределение. Распределение является асимметричным.
имеет логнормальное распределение. Распределение является асимметричным.
Плотность вероятности задается следующим выражением:
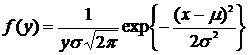 . (8.18)
. (8.18)
Математическое ожидание и дисперсия определяются по следующим формулам:
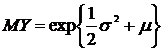 ; (8.19)
; (8.19)
![]() , (8.20)
, (8.20)
где ![]() - математическое ожидание Х;
- математическое ожидание Х; ![]() - среднеквадратическое отклонение Х.
- среднеквадратическое отклонение Х.
Биномиальное распределение – распределение вероятностей дискретной случайной величины X=m, принимающей значение 0,1,2,…, n и задаваемой функцией вероятностей :
![]() , (8.20)
, (8.20)
где ![]() - вероятность появления события А m раз в n независимых испытаниях, в каждом из которых событие А появляется с одно и той же вероятностью p и не появляется с вероятностью
- вероятность появления события А m раз в n независимых испытаниях, в каждом из которых событие А появляется с одно и той же вероятностью p и не появляется с вероятностью ![]() ;
;
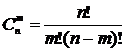 - число сочетаний из n по m.
- число сочетаний из n по m.
Параметрами распределения являются величины n и р. Математическое ожидание и дисперсия задаются следующим образом:
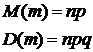 (8.21)
(8.21)
Равномерное распределение – распределение вероятностей непрерывной случайной величины на каком-либо отрезке ![]() , где
, где ![]() , имеющее плотность:
, имеющее плотность:
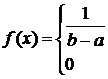 при
при ![]() (8.22)
(8.22)
Математическое ожидание и дисперсия соответственно равны:
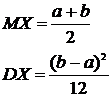 (8.23)
(8.23)
9. Описательная статистика
В самом общем смысле статистическое оценивание параметров можно рассматривать как совокупность методов, позволяющих делать научно обоснованные выводы о числовых параметрах генеральной совокупности по случайной выборке из нее.
Генеральной совокупностью называют множество результатов всех мыслимых наблюдений, которые могут быть получены при данном комплексе условий.
Выборочной совокупностью (выборкой) называют множество результатов, случайно отобранных из генеральной совокупности.
Задачи математической статистики практически сводятся к обоснованному суждению об объективных свойствах генеральной совокупности по результатам случайной выборки.
Любая функция θ(Х1, Х2,…,Хn) от результатов наблюдения Х1, Х2,…,Хn случайной величины Х называется статистикой.
Статистика ![]() , используемая в качестве приближенного значения неизвестного параметра θ, называется статистической оценкой. Основная задача теории оценивания состоит в том, чтобы произвести выбор оценки
, используемая в качестве приближенного значения неизвестного параметра θ, называется статистической оценкой. Основная задача теории оценивания состоит в том, чтобы произвести выбор оценки ![]() параметра θ, позволяющей получить хорошее приближение оцениваемого параметра.
параметра θ, позволяющей получить хорошее приближение оцениваемого параметра.
Все статистики и статистические оценки являются случайными величинами: при переходе от одной выборки к другой (даже в рамках одной и той же генеральной совокупности) конкретные значения статистической оценки будут подвержены неконтролируемому разбросу. Параметры генеральной совокупности есть постоянные величины.
Методы статистического оценивания состоят из двух больших разделов: точечное оценивание параметров и интервальное оценивание.
Точечной оценкой называют некоторую функцию результатов наблюдения θ(Х1, Х2,…,Хn), значение которой принимается за наиболее приближенное в данных условиях к значению параметра θ генеральной совокупности. Точечная оценка должна отвечать требованиям состоятельности, несмещенности и эффективности.
Существуют следующие основные методы точечного оценивания случайных величин: метод максимального (наибольшего) правдоподобия; метод моментов; метод наименьших квадратов.
Метод максимального правдоподобия. В соответствии с этим методом оценка 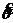 мп неизвестного параметра θ по наблюдениям Х1, Х2,…,Хn случайной величины Х (подчиненной закону распределения f (X,
мп неизвестного параметра θ по наблюдениям Х1, Х2,…,Хn случайной величины Х (подчиненной закону распределения f (X,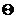 ), где f – плотность вероятности) определяется из условия
), где f – плотность вероятности) определяется из условия
L(Х1, Х2,…,Хn; ![]() мп )=
мп )=![]() L(Х1, Х2,…,Хn;
L(Х1, Х2,…,Хn; ![]() ) (9.1)
) (9.1)
где L – функция правдоподобия.
Если переписать функцию L в виде L = ![]() , (9.2)
, (9.2)
тогда логарифм этой функции L = - (9.3)
есть логарифмическая функция максимального правдоподобия.
Функция максимального правдоподобия максимизирует количественную оценку ![]() для оценки истинного параметра θ. При этом оценка
для оценки истинного параметра θ. При этом оценка ![]() выбирается таким образом, что реализация функции (2.2) или эквивалентной ей функции (2.3) будет иметь наибольшее значение. Доказано, что оценки максимального правдоподобия являются состоятельными, асимптотически-несмещенными, асимпточески-нормальными и асимптотически-эффективными.
выбирается таким образом, что реализация функции (2.2) или эквивалентной ей функции (2.3) будет иметь наибольшее значение. Доказано, что оценки максимального правдоподобия являются состоятельными, асимптотически-несмещенными, асимпточески-нормальными и асимптотически-эффективными.
Метод моментов. Метод моментов заключается в приравнивании определенного количества выборочных моментов к соответствующим теоретическим (т. е. вычисленным с использованием функции f (X,![]() )) моментам исследуемой случайной величины, причем последние являются функциями от неизвестных параметров θ(1),…, θ(k). Рассматривая количество моментов, равное числу k подлежащих оценки параметров, и решая полученные уравнения относительно этих параметров, получаются искомые оценки. Доказывается, что оценки неизвестных параметров, полученные методом моментов, являются состоятельными. В силу сравнительно простой вычислительной реализации метод моментов удобен на практике.
)) моментам исследуемой случайной величины, причем последние являются функциями от неизвестных параметров θ(1),…, θ(k). Рассматривая количество моментов, равное числу k подлежащих оценки параметров, и решая полученные уравнения относительно этих параметров, получаются искомые оценки. Доказывается, что оценки неизвестных параметров, полученные методом моментов, являются состоятельными. В силу сравнительно простой вычислительной реализации метод моментов удобен на практике.
Метод наименьших квадратов используется в регрессионном анализе для нахождения оценок параметров уравнения регрессии. Метод состоит в том, чтобы определить оценку неизвестного параметра из решения следующей задачи:
![]()
![]() min , (9.4)
min , (9.4)
где xi – результаты выборочных наблюдений.
Можно показать, что данный функционал достигает своего минимума при таком значении ![]() , при котором обращается в нуль первая производная:
, при котором обращается в нуль первая производная: 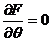 .
.
В случае линейных связей, когда наблюдения содержат лишь случайные ошибки (без систематических), оценки, полученные методом наименьших квадратов, являются несмещенными линейными функциями от наблюденных значений. Если ошибки наблюдения независимы и подчиняются нормальному распределению, оценки, полученные данным методом, являются также эффективными.
Несмещенность. Оценка неизвестного параметра θ называется несмещенной, если при любом объеме выборки n результат ее осреднения по всем возможным выборкам данного объема приводит к точному истинному значению оцениваемого параметра, т. е. М=θ. (2.5)
Выполнение требования несмещенности гарантирует отсутствие систематической ошибки в оценке параметра. Разность М![]() и θ называется смещением оценки.
и θ называется смещением оценки.
Оценка называется асимптотически несмещенной, если ее смещенность исчезает при условии n, т.е. справедливо следующее равенство
![]() (М
(М![]() ) = θ. (9.6)
) = θ. (9.6)
Эффективность. Эффективной оценкой ![]() неизвестного параметра θ называется такая несмещенная оценка, которая обладает наименьшей дисперсией среди всех возможных несмещенных оценок параметра θ для данного объема выборки n.
неизвестного параметра θ называется такая несмещенная оценка, которая обладает наименьшей дисперсией среди всех возможных несмещенных оценок параметра θ для данного объема выборки n.
Данное выше определение опирается на понятие абсолютной эффективности. Несмещенная оценка ![]() является абсолютно эффективной, если она достигает нижнюю границу эффективности, задаваемую неравенством Крамера-Рао.
является абсолютно эффективной, если она достигает нижнюю границу эффективности, задаваемую неравенством Крамера-Рао.
Var![]()
![]() M
M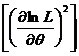 , (9.7)
, (9.7)
где M - количество информации, содержащейся в выборке. ![]() - несмещенная оценка параметра θ, L – функция правдоподобия, Var – знак дисперсии, M – знак математического ожидания.
- несмещенная оценка параметра θ, L – функция правдоподобия, Var – знак дисперсии, M – знак математического ожидания.
Очевидно, что для абсолютно эффективной оценки неравенство (2.7) превращается в равенство. Можно также ввести понятие относительной эффективности.
Для двух несмещенных оценок 1 и 2 оценка 1 будет более эффективной, если при прочих равных условиях выполняется неравенство:
var( 1 ) < var( 2) (9.8)
Мерой эффективности оценки служит средняя квадратическая ошибка, задаваемая следующей формулой: σ = М{( - θ)2} (2.9)
Оценку 1 называют асимптотически более эффективной, чем оценка 2, если:
![]() var( 1)
var( 1)![]()
![]() var( 2) (9.10)
var( 2) (9.10)
Cостоятельность. Оценка ![]() неизвестного параметра θ называется состоятельной, если по мере роста числа наблюдений n (т. е. при n ) она стремится по вероятности к оцениваемому значению θ, т. е. если для любого сколь угодно малого ε>0 выполняется условие P
неизвестного параметра θ называется состоятельной, если по мере роста числа наблюдений n (т. е. при n ) она стремится по вероятности к оцениваемому значению θ, т. е. если для любого сколь угодно малого ε>0 выполняется условие P![]()
![]() > ε
> ε ![]() . (9.11)
. (9.11)
В теории доказывается, что средняя арифметическая ![]() является несмещенной, состоятельной и эффективной оценкой математического ожидания
является несмещенной, состоятельной и эффективной оценкой математического ожидания ![]() .
.
Выборочная дисперсия ![]() является состоятельной, эффективной, но смещенной оценкой генеральной дисперсии
является состоятельной, эффективной, но смещенной оценкой генеральной дисперсии ![]() . Несмещенной оценкой дисперсии генеральной совокупности будет исправленная выборочная дисперсия
. Несмещенной оценкой дисперсии генеральной совокупности будет исправленная выборочная дисперсия ![]() :
:
![]() =
=![]() , (9.12)
, (9.12)
где дробь ![]() - является поправкой Бесселя. C ростом
- является поправкой Бесселя. C ростом ![]() поправка стремится к нулю и уже при
поправка стремится к нулю и уже при ![]() >50 практически нет никакой разницы между
>50 практически нет никакой разницы между ![]() и
и ![]() .
.
Законы распределения выборочных характеристик
Распределение Пирсона (![]() распределение). Если Х1, Х2,…,Хn есть ряд независимых, нормированных, нормально распределенных случайных величин
распределение). Если Х1, Х2,…,Хn есть ряд независимых, нормированных, нормально распределенных случайных величин 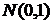 , т. е.
, т. е.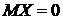 и
и 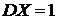 для
для 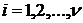 , то случайная величина
, то случайная величина
![]() (9.13)
(9.13)
имеет распределение ![]() с
с ![]() степенями свободы, где
степенями свободы, где ![]() -единственный параметр распределения, характеризующий число случайных величин в выражении ().
-единственный параметр распределения, характеризующий число случайных величин в выражении ().
Математическое ожидание и дисперсия (![]() распределения) задаются следующими выражениями:
распределения) задаются следующими выражениями: 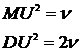 (9.14)
(9.14)
Распределение Стьюдента (![]() - распределение). Если случайная величина Z имеет нормированное нормальное распределение , а величина
- распределение). Если случайная величина Z имеет нормированное нормальное распределение , а величина ![]() имеет распределение
имеет распределение ![]() с
с ![]() степенями свободы, причем Z и U взаимно независимы, то случайная величина
степенями свободы, причем Z и U взаимно независимы, то случайная величина
![]() (9.15)
(9.15)
имеет ![]() - распределение с
- распределение с ![]() степенями свободы.
степенями свободы.
Математическое ожидание и дисперсия (![]() -распределения) задаются следующими выражениями:
-распределения) задаются следующими выражениями: 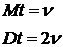 (9.16)
(9.16)
Распределение Фишера-Снедекора. Пусть имеется две независимые случайные величины X и Y, подчиняющиеся нормальному закону распределения. Произведены две независимые выборки объемами ![]() и
и![]() и вычислены выборочные дисперсии
и вычислены выборочные дисперсии ![]() и
и![]() . Известно, что случайные величины
. Известно, что случайные величины 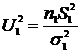 и
и 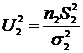 имеют распределение
имеют распределение ![]() с соответственно
с соответственно ![]() и
и ![]() степенями свободы. Случайная величина
степенями свободы. Случайная величина
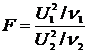 (2.17)
(2.17)
имеет F-распределение с ![]() и
и ![]() , причем
, причем 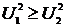 .
.
F-распределение не зависит от неизвестных параметров 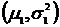 и
и 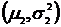 , а зависит от числа наблюдений в выборках
, а зависит от числа наблюдений в выборках ![]() и
и![]() .
.
Математическое ожидание и дисперсия (![]() -распределения) задаются следующими выражениями:
-распределения) задаются следующими выражениями: 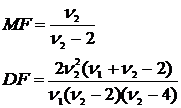 (9.18)
(9.18)
Интервальной оценкой называют доверительный интервал (![]() -
-![]() ,
,![]() +
+![]() ), определяемый по результатам выборки, относительно которого можно утверждать с определенной, близкой к единице вероятностью, что он заключает в себе истинное значение оцениваемого параметра генеральной совокупности, т. е.
), определяемый по результатам выборки, относительно которого можно утверждать с определенной, близкой к единице вероятностью, что он заключает в себе истинное значение оцениваемого параметра генеральной совокупности, т. е.
Р(![]() -
-![]()
![]() θ
θ![]()
![]() +
+![]() ) =γ, (9.19)
) =γ, (9.19)
где ![]() -
-![]() и
и ![]() +
+![]() и – соответственно нижняя и верхняя границы доверительного интервала. Вероятность γ называется доверительной вероятностью.
и – соответственно нижняя и верхняя границы доверительного интервала. Вероятность γ называется доверительной вероятностью.
Параметр ![]() задает точность интервальной оценки. Ширина доверительного интервала h определяется по формуле: h = 2
задает точность интервальной оценки. Ширина доверительного интервала h определяется по формуле: h = 2![]() . (9.20)
. (9.20)
Доверительный интервал по своей природе случаен. Ширина доверительного интервала существенно зависит от объема выборки n (уменьшается с ростом n) и от величины доверительной вероятности (увеличивается с приближением доверительной вероятности к единице).
Интервальные оценки для генеральной средней
Дисперсия генеральной совокупности известна. Пусть из генеральной совокупности Х с нормальным законом распределения N(μ;σ) и известным генеральным средним квадратическим отклонением взята случайная выборка Х1, Х2,…,Хn объемом n . Для нахождения интервальной оценки μ используем среднюю арифметическую, которая имеет нормальное распределение с параметрами N(μ;![]() ).
).
Статистика ![]()
![]() имеет нормированное нормальное распределение с параметрами N(0;1). Вероятность любого отклонения
имеет нормированное нормальное распределение с параметрами N(0;1). Вероятность любого отклонения ![]() может быть вычислена по интегральной теореме Лапласа для интервала, симметричного относительно μ по формуле:
может быть вычислена по интегральной теореме Лапласа для интервала, симметричного относительно μ по формуле:
Р{(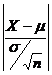 )<t γ }=Ф(t) (9.21)
)<t γ }=Ф(t) (9.21)
Задавая определенную доверительную вероятность γ по таблице интегральной функции Лапласа Ф(t), можно определить значение t γ.
Преобразовав формулу (1.13), будем иметь доверительный интервал для математического ожидания: Р{![]() t γ
t γ ![]()
![]()
![]() + t γ
+ t γ ![]() }= Ф(t) (9.22)
}= Ф(t) (9.22)
Точность оценки равна ![]() = t γ
= t γ![]() (9.23)
(9.23)
Дисперсия генеральной совокупности неизвестна. Пусть имеется генеральная совокупность Х, распределенная по нормальному закону N(μ;σ), c неизвестным средним квадратическим отклонением σ. По результатам выборки объема n из генеральной совокупности вычислены средняя арифметическая х и выборочное среднее квадратическое отклонение S. В этом случае для построения интервальной оценки генеральной средней μ используется статистика ![]()
![]() , имеющая распределение Стьюдента с числом степеней свободы ν=n-1.
, имеющая распределение Стьюдента с числом степеней свободы ν=n-1.
По таблице t – распределения Стьюдента для ν=n-1 степеней свободы находим значение tα,η , для которого справедливо равенство
Р{![]() tα,η
tα,η ![]()
![]() + tα,η
+ tα,η ![]() }= γ (9.24)
}= γ (9.24)
Точность оценки равна ![]() = tα,η
= tα,η ![]() (9.25)
(9.25)
Интервальные оценки для генеральной дисперсии и среднего квадратического отклонения
Пусть из генеральной совокупности Х, распределенной по нормальному закону N(μ;σ), взята случайная выборка объемом n и вычислена выборочная дисперсия S2. Требуется определить с надежностью γ интервальные оценки для генеральной дисперсии σ2 и среднего квадратического отклонения σ.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
