


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Полученные главные компоненты позволяют классифицировать множество исходных признаков на группы, обобщающими показателями которых и являются главные компоненты. В силу ортогональности (независимости) главные компоненты удобны для построения на них уравнения регрессии ввиду отсутствия мультиколлинеарности главных компонент. Для построения уравнения регрессии на главных компонентах в качестве исходных данных следует взять вектор наблюдаемых значений результативного признака y и вместо матрицы значений исходных показателей X – матрицу вычисленных значений главных компонент F.![]()
6.Темы практических и семинарских занятий,
тематических дискуссий
Тема 1. Основные понятия, определения и теоремы теории вероятностей
• автокорреляция в наблюдениях за одной и более переменными;
• автокорреляция ошибок или автокорреляция в отклонениях от тренда.
При изучении развития явления во времени часто возникает необходимость оценить взаимосвязи в изменениях уровней двух или более рядов динамики различного содержания, но связанных между собой.
Эта задача решается методами коррелирования:
• уровней ряда динамики;
• отклонений физических уровней от тренда;
• последовательных разностей, т. е. путем исчисления парного коэффициента корреляции.
Для обобщающей характеристики особенностей формы распределения применяются кривые распределения. Кривая распределения выражает графически (полигон, гистограмма) закономерность распределения единиц совокупности по величине варьирующего признака. Различают эмпирические и теоретические кривые распределения.
Эмпирическая кривая распределения - это фактическая кривая распределения, полученная по данным наблюдения, в которой отражаются как общие, так и случайные условия, определяющие распределение.
Теоретическая кривая распределения - это кривая, выражающая функциональную связь между изменениями варьирующего признака и изменением частот и характеризующая определенный тип распределения. При этом теоретическое распределение играет роль некоторой идеализированной модели эмпирического распределения, а сам анализ вариационного ряда сводится к сопоставлению эмпирического и теоретического распределения. Для подробного описания особенностей распределения в характеристики, в частности определяются моменты распределения. Способ моментов был разработан русским математиком и успешно применен для рассмотрения возможностей использования закона нормального распределения при изучении сумм большого, но конечного числа независимых случайных величин.
Задача 1. Вероятность того, что покупатель, собирающийся приобрести компьютер и пакет прикладных программ, приобретет только компьютер, равна 0,15. Вероятность, что покупатель купит только пакет программ, равна 0,1. Вероятность того, что будут куплены и компьютер, и пакет программ, равна 0,05. Чему равна вероятность того, что будут куплены или компьютер, или пакет программ, или компьютер и пакет программ вместе?
Задача 2. В корпорации обсуждается маркетинг нового продукта, выпускаемого на рынок. Исполнительный директор корпорации желал бы, чтобы новый товар превосходил по своим характеристикам соответствующие товары конкурирующих фирм. Основываясь на предварительных оценках экспертов, он оценивает вероятность более высокой конкурентной способности нового товара по сравнению с аналогичными в 0,5; одинаковой – в 0,3, а вероятность того, что новый товар окажется хуже по качеству, – в 0,2. Опрос рынка показал, что новый товар более высокого качества и конкурентоспособен. Из предыдущего опыта проведения таких опросов следует, что если товар действительно конкурентоспособный, то предсказание такого же вывода имеет вероятность, равную 0,7. Если товар такой же, как другие аналогичные, то вероятность того, что опрос укажет на его превосходство, равна 0,4. И если товар более низкого качества, то вероятность того, что опрос укажет на товар более высокого качества, равна 0,2. С учетом результата опроса оцените вероятность того, что товар действительно конкурентоспособный?
Литература: 1, 5, 6.
Тема 2. Формула полной вероятности и формула Байеса
В анализе данных наряду со статистическими таблицами применяются и другие виды таблиц, одним из которых являются.
Матрицей - называется прямоугольная таблица числовой информации, состоящая из m строк и n столбцов. Таким образом, матрица имеет размерность m x n:
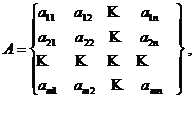
где ![]() ij-элемент матрицы, состоящей на i-й строки и J-й столбца.
ij-элемент матрицы, состоящей на i-й строки и J-й столбца.
Различают два вида матриц:
• прямоугольную (размерность m x n);
• квадратную
Таблицей сопряженности называется таблица, которая содержит сводную числовую характеристику изучаемой совокупности по двум и более атрибутным (качественным) признакам или комбинаций количественных и атрибутных признаков.
Таблицы сопряженности получили наиболее распространение при изучении социальных явлений и процессов: общественного мнения, уровня и образа жизни, общественного - политического строя и т. д.
Задача 1. Вероятность того, что выпускник финансового факультета защитит диплом на «отлично», равна 0,6. Вероятность того, что он защитит диплом «на отлично» и получит приглашение на работу в банк, равна 0,4. Предположим, что студент защитил диплом. Чему равна вероятность того, что он получит приглашение на работу в банк?
Задача 2. Медицинский тест на возможность вирусного заболевания дает следующие результаты:
1. Если проверяемый болен, то тест даст положительный результат с вероятностью 0,92.
2. Если проверяемый не болен, то тест может дать положительный результат с вероятностью 0,04.
Поскольку заболевание редкое, то ему подвержено только 0,1% населения. Предположим, что некоторому случайно выбранному человеку сделан анализ и получен положительный результат. Чему равна вероятность того, что человек действительно болен?
Литература: 1, 2, 7
Тема 3 Случайные величины
Графический метод есть метод условных изображений статистических данных при помощи геометрических фигур, линий, точек и разнообразных символических образов.
Для построения графика необходимо определить, для каких целей он составляется, и тщательно изучить исходный материал. Но самое главное условие – это овладение ме6тодологией графических изображений. В статистическом графике различают следующие основные элементы: поле графика; пространственные ориентиры, масштабные ориентиры; экспликация графика.
Существует множество графических изображений. Их классификация основана на ряде признаков, а основе которых:
• способ построения графического образа;
• геометрические знаки, изображающие статистические показатели;
• задачи, решаемые с помощью графического изображения.
По способу построения статистические графики делятся на диаграммы и статистические карты.
Геометрические знаки, как было сказано выше, представляют собой точки, либо линии или плоскости, либо геометрические фигуры. В соответствии с этим различают графики точечные, линейные, плоскостные и пространственные.
В зависимости от круга решаемых задач выделяют диаграммы сравнения, структурные диаграммы, и диаграммы динамики.
Задача 1. Стандарт заполнения счетов, установленный фирмой, предполагает, что не более 5% счетов будет заполняться с ошибками. Время от времени компания проводит случайную выборку счетов для проверки правильности их заполнения. Исходя из того, что допустимый уровень ошибок 5% и 10 счетов отобраны в случайном порядке, определите, чему равна вероятность того, что среди них нет ошибок?
Задача 2. Нефтеразведочная экспедиция проводит исследования для определения вероятности наличия нефти на месте предполагаемого бурения скважины. Исходя из результатов предыдущих исследований, нефтеразведчики считают, что вероятность наличия нефти на проверяемом участке равна 0,4. На завершающем этапе разведки проводится сейсмический тест, который имеет определенную степень надежности: если на проверяемом участке есть нефть, то тест укажет на нее в 85% случаев; если нефти нет, то в 10% случаев тест может ошибочно указать на ее наличие. Сейсмический тест указал на присутствие нефти. Чему равна вероятность того, что запасы нефти на этом участке существуют реально?
Литература: 1, 8, 16
Тема 4. Законы распределения дискретных случайных величин
Наиболее распространенной формой статистических показателей, используемых в социально-экономических исследованиях, является средняя величина, представляющая собой обобщенную количественную характеристику признака в статистической совокупности в конкретных условиях места и времени. Показатель в форме средней величины выражает типичные черты и дает обобщенную характеристику однотипных явлений по одному из варьирующих признаков. Он отражает уровень этого признака, отнесенный к единице совокупности. Широкое применение средних величин объясняется тем, что они имеют ряд положительных свойств, делающих их незаменимыми в анализе явлений и процессов общественной жизни.
Важнейшие свойство средней величины заключается в том, что оно отражается то общее, что присуще всем единицам исследуемой совокупности. Значений признака отдельных единиц совокупности могут колебаться в ту или иную сторону под влиянием множества факторов, среди которых есть как основные, так и случайные.
Сущность средней единицы в том заключается, что в ней взаимопогашаются отклонения значений признака отдельных единиц совокупности, обусловленные действием случайных факторов, и учитываются изменения, вызванные действием фактором основных. Это позволяет средней отражать типичный уровень признака и абстрагироваться от индивидуальных особенностей, присущих отдельным единицам.
Типичность средней непосредственным образом связана с однородностью статистической совокупности. Средняя величина только тогда будет отражать типичный уровень признака, когда она рассчитана по качественно однородной совокупности. Теория средних достаточно подробно разработана в отечественных и зарубежных исследованиях. Среди ученых, внесших свой клад в ее развитие необходимо отметить И. Зюсмильха, А. Кетле, А. Боули, К. Джини, , В. Е, Овсиенко и д. р.
Задача 1. Одна из наиболее сложных проблем рыночных исследований – отказ потребителей отвечать на вопросы о потребительских предпочтениях, либо, если опрос проводится по месту жительства, – отсутствие их дома на момент опроса. Предположим, что исследователь рынка с вероятностью 0,94 верит, что респондент согласится отвечать на вопросы анкеты, если окажется дома. Он также полагает, что этот же человек будет дома, равна 0,65. Имея такие данные, оцените процент заполненных анкет.
Задача 2. На химическом заводе установлена система аварийной сигнализации. Когда возникает аварийная ситуация, звуковой сигнал срабатывает с вероятностью 0,95. Звуковой сигнал может сработать случайно и без аварийной ситуации с вероятностью 0,02. Реальная вероятность аварийной ситуации равна 0,004. Предположим, что звуковой сигнал сработал. Чему равна вероятность реальной аварийной ситуации?
Литература: 5, 6, 8
Тема 5. Непрерывные случайные величины
Выборки, при которых наблюдением охватывается небольшое число единиц (n<30), принято называть малыми выборками. Они обычно применяются в том случае, когда невозможно или нецелесообразно использовать большую выборку (исследование качества продукции, если связано с ее разрушением, в частности на прочность, на продолжительность срока службы т. д.) Предельная ошибка определяется по формуле:
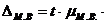
Средняя ошибка малой выборки:
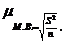
где ![]() - дисперсия малой выборки.
- дисперсия малой выборки.
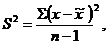
где ![]() - среднее число признака по выборке;
- среднее число признака по выборке;
![]() - число степеней свободы
- число степеней свободы ![]() ;
;
![]() - коэффициент доверия малой выборки, зависящий не только от заданной доверительной вероятности, но и от численности единиц выборки.
- коэффициент доверия малой выборки, зависящий не только от заданной доверительной вероятности, но и от численности единиц выборки.
Задача 1. Иностранная фирма, производящая автомобили, интересуется российским рынком. Для изучения вкуса потенциальных покупателей производится опрос, в котором выясняют наиболее желательные свойства автомобиля. Предположим, что результаты опроса показали: 35% потенциальных покупателей в основном оценивают автомобиль по его техническим характеристикам; 50% – по его дизайну; 25% считают одинаково важным и то и другое. Из группы потенциальных покупателей случайно выбраны трое. Чему равна вероятность того, что все трое полагают наиболее важными при покупке автомобиля его высокие технические характеристики? Чему равна вероятность того, что хотя бы один из них считает технические характеристики наиболее важными? Объясните свои расчеты. Предполагается, что выбор одного покупателя не слишком заметно уменьшит вероятность (в данном случае частоту т/п=0,35).
Задача 2. Перед тем как начать маркетинг нового товара по всей стране, компании-производители часто проверяют его на выборке потенциальных покупателей. Методы проведения выборочных процедур уже проверены и имеют определенную степень надежности. Для некоторого товара известно, что проверка укажет на возможный его успех на рынке с вероятностью 0,75, если товар действительно удачный; проверка может также показать возможность успеха товара в случае, если он неудачен, с вероятностью 0,15. Из прошлого опыта известно, что новый товар может иметь успех на рынке с вероятностью 0,6. Если новый товар прошел выборочную проверку, и ее результаты указали на возможность успеха, то чему равна вероятность того, что это действительно так?
Литература: 8, 9, 11
Тема 6. Законы распределения непрерывных случайных величин
Выборочный метод получил широкое распространение в государственной и ведомственной статистике (например, бюджетные семей обследования рабочих, крестьян, служащих, обследование жилищных условий, заработной платы и др.). В торговле с помощью выборочного метода изучается качество поступивших товаров, эффективность новых норм торговли, спрос населения на определенные виды товаров, степень его удовлетворения и др.
В статистической практике нередко осуществляется выборочная разработка экономической информации, полученной методом сплошного наблюдения.
Большую актуальность имеет выборочный метод в условиях переходного периода и функционирования рыночной экономики. Изменения в характере экономических отношений, аренда, собственность отдельных коллективов и лиц обусловливают изменений функций учета и статистики, сокращение и упражнение отчетности. Вместе с тем возрастающие требование к менеджменту усиливают потребность в обеспечении надежной информации, дальнейшего повышения ее оперативности. Все это обуславливает более широкое применение выборочного метода в экономике, прежде всего в торговле, порождающей и потребляющей огромные массивы информации.
По сравнению с другими методами, применяющими несплошное наблюдение, выборочный метод имеет важную особенность. В основе отбора единиц для обследования положены принципы равных возможностей попадания в выборку каждой единицы генеральной совокупности. Именно в результате соблюдений этих принципов исключается образования выборочной совокупности только за счет лучших или худших образцов. Это предупреждает появление систематических (тенденциозных) ошибок и делает возможность проводить количественную оценку ошибки правительства (репрезентативности).
Задача 1. В большом универмаге установлен скрытый «электронный глаз» для подсчета числа входящих покупателей. Когда два покупателя входят в магазин вместе, и один идет перед другим, то первый из них будет учтен 0,98, второй – с вероятностью 0,94, оба – с вероятностью 0,93.чему равна вероятность того, что устройство сканирует по крайней мере одного из двух входящих вместе покупателей?
Задача 2. Исследователь рынка заинтересован в проведении интервью с супружескими парами для выяснения их предпочтений к некоторым видам товаров. Исследователь приходит по выбранному адресу и попадает в трехквартирный дом. По надписям на почтовых ящиках он выясняет, что в первой квартире живут двое мужчин, во второй – супружеская пара, в третьей – двое женщин. Когда исследователь поднимается по лестнице, то выясняется, что на дверях квартир нет никаких указателей. Исследователь звонит в случайно выбранную дверь, и на его звонок выходит женщина. Предположим, что если бы исследователь позвонил в дверь квартиры, где живут двое мужчин, то к двери мог подойти только мужчина; если бы он позвонил в дверь квартиры, где живут только женщины, то к двери подошла бы только женщина; если бы он позвонил в дверь супружеской пары, то мужчина или женщина имели бы равные шансы подойти к двери. Имея эту информацию, оцените вероятность того, что исследователь выбрал нужную ему дверь.
Литература: 1, 15, 16
Тема 7. Закон больших чисел
Исследование объективно существующих связей между явлениями - важнейшая задача общей теории статистики. В процессе статистического исследования зависимостей вскрывается причинно-следственные отношения между явлениями, что позволяет выявлять факторы (признаки), оказывающие существенное влияние на вариацию изучаемых явлений и процессов. Причинно-следственные отношения – это связь явлений и процессов, при которых изменения одного из них – причины - ведет к изменению другого – следствия.
На первом этапе статистического изучения связи осуществляется качественный анализ изучаемого явления методами экономической теории, социологии, конкретной экономики.
На втором этапе строится модель связи на основе методов статистики: группировок, средних величин, таблиц т. д.
На третьем, последнем этапе интерпретируются результаты; анализ вновь связан с качественными особенностями изучаемого явления.
Задача 1. Телефонная компания организует рекламу спутниковой связи. Один из рекламных роликов компании представляет собой сюжет, в котором бизнесмен звонит в город Урюпинск, а попадает на острова Фиджи, откуда ему отвечает на полинезийском диалекте абориген, лежащий на пляже. Конечно, это выдуманный сюжет, но подобные ситуации зачастую возникают. Предположим, что в среднем в одном из 200 наборов номера абонентом спутниковой связи происходит ошибочное соединение. Чему равна вероятность хотя бы одного ошибочного соединения при 5 междугородных звонках по спутниковой связи? Предполагается, что все пять наборов номеров независимы.
Задача 2. Экономист-аналитик условно подразделяет экономическую ситуацию в стране на «хорошую», «посредственную» и «плохую» и оценивает их вероятности для данного момента времени в 0,15, 0,70 и 0,15 соответственно. Некоторый индекс экономического состояния возрастает с вероятностью 0,6, когда ситуация «хорошая»; с вероятностью 0,3, когда ситуация «посредственная», и с вероятностью 0,1, когда ситуация «плохая». Пусть в настоящий момент индекс экономического состояния изменился. Какова вероятность того, что экономика страны на подъеме?
Литература: 2, 9, 13
Тема 8. Первичная обработка данных
Показатели корреляционной связи, вычисленные по ограниченной совокупности (по выборке), являются лишь оценками той или иной статистической закономерности, поскольку в любом параметре сохраняется элемент не полностью погасившейся случайности, присущей индивидуальным значениям признаков. Поэтому необходима статистическая оценка степени точности и надежности параметров корреляции. Под надежностью здесь понимается вероятность того, что значение проверяемого параметра не равна нулю, не включает в себя величины противоположных знаков.
Вероятностная оценка параметров корреляции производится по общим правилам проверки статистических гипотез, разработанными математической статистикой, в частности путем сравнения оцениваемой величины со средней случайной ошибкой оценки.
Задача 1. Секрет увеличения доли определенного товара на рынке состоит в привлечении новых потребителей и их сохранении. Сохранение новых потребителей товара называется brand loyalty (приверженность потребителя к данной марке или разновидности товара), и это одна из наиболее ответственных областей рыночных исследований. Производители нового сорта товара знают, что вероятность того, что потребители сразу примут новый продукт, и создание brand loyalty потребует, по крайней мере, шести месяцев, равна 0,02. Производитель также знает, что вероятность того, что случайно отобранный потребитель примет новый сорт, равна 0,05. Предположим, что потребитель только что изменил марку товара. Какова вероятность того, что он сохранит свои предпочтения в течение шести месяцев?
Задача 2. Два автомата производят одинаковые детали, которые поступают на общий конвейер. Производительность первого автомата вдвое больше производительности второго автомата. Первый автомат производит в среднем 60% деталей отличного качества, а второй – 84% деталей отличного качества. Наудачу взятая, с конвейера деталь оказалась отличного качества. Найти вероятность того, что эта деталь изготовлена первым автоматом? Вторым автоматом?
Литература: 1, 3, 9
Тема 9. Описательная статистика
Компонентные связи показателей коммерческой деятельности характеризуются тем, что изменения статистического показателя определяется изменением компонентов, входящих в этот показатель, как множители:
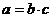
В статистике коммерческой деятельности компонентные связи используют в индексном методе выявления роли отдельных факторов в совокупности изменении сложного показателя.
Факторные связи в коммерческой деятельности характеризуются тем, что они проявляются в согласованной вариации изучаемых показателей. При этом одни показатели выступают как факторные, а другие как – результативные. По своему характеру этот вид связи является причинно-следственной (детерминированной) зависимостью.
В свою очередь, факторные связи могут рассматриваться как функциональные и корреляционные.
Задача 1. Вероятность того, что судоходная компания получит разрешение для захода в определенный порт назначения, зависит от того, будет принят или нет необходимый для этого закон. Компания оценивает, что вероятность того, что произойдут оба события (принят соответствующий закон и получено разрешение на посещение порта), равна 0,5, а вероятность того, что необходимый закон будет принят, равна 0,75. Предположим, что компания получила сведения, что закон принят. Чему равна вероятность того, что разрешение на заход в порт назначения будет получено?
Задача 2. Среди студентов института по результатам зимней сессии 30% первокурсников имеют только отличные оценки, среди второкурсников таких студентов 35%, на третьем и четвертом курсе их 20% и 15% соответственно. По данным деканатов известно, что на первом курсе 20% студентов сдали сессию только на отличные оценки, на втором – 30%, на третьем – 35%, на четвертом – 40% отличников. Наудачу вызванный студент оказался отличником. Чему равна вероятность того, что он (или она) – третьекурсник.
Литература: 5, 9, 10
Тема 10. Предварительный анализ данных
Дисперсионный анализ является одним из методов изучения влияния одного или нескольких факторных признаков на результативный признак. В зависимости от количества факторов дисперсионный анализ подразделяется на однофакторный и многофакторный. Ниже рассмотрено применение дисперсионного анализа для случая однофакторного комплекса.
В основе дисперсионного анализа лежит расчленение общей вариации изучаемого признака по истокам ее происхождения на два вида вариации:
• систематическую вариацию, которая обусловлена изменением признака фактора;
• остаточную (случайную) вариацию, обусловленную действием прочих, случайных, не связанных с данным фактором обстоятельств.
Для разграничения этих вариаций всю совокупность наблюдавшихся единиц разбивают на группы, (классы) по факторному признаку и исчисляют средние результативного признака по группам.
Групповые средние:
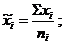
общая средняя величина:
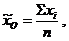
где ![]() - индивидуальные значения признака в группе;
- индивидуальные значения признака в группе;
![]() - число единиц, входящих в группу;
- число единиц, входящих в группу;
![]() - общее число наблюдений.
- общее число наблюдений.
Задача 1. Какова вероятность того, что последняя цифра наугад набранного телефонного номера окажется равной или кратной 3?
Задача 2. Директор фирмы имеет 2 списка с фамилиями претендентов на работу. В первом списке – фамилии 5 женщин и 2 мужчин. Во втором списке оказались 2 женщины и 6 мужчин. Фамилия одного из претендентов случайно переносится из первого списка во второй. Затем фамилия одного из претендентов случайно выбирается из второго списка. Если предположить, что эта фамилия принадлежит мужчине, чему равна вероятность того, что из первого списка была извлечена фамилия женщины?
Литература: 5, 8, 12
Тема 11. Анализ статистической связи
Уравнение регрессий применимо и для прогнозирования возможных ожидаемых значений результативного признака. При этом следует учесть, что перенос закономерности связи, измеренной в варьирующей совокупности, в статистике за динамику не является, строго говоря, корректным и требует проверки условий допустимости такого переноса, (экстраполяции), что выходит за рамки статистики и может быть сделано только специалистом, хорошо знающем объект (систему) и возможности его развития в будущем.
Прогнозируя значение результативного показателя, получается при подстановке в уравнение регрессии ожидаемой величины факторного признака.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения фактора, называют точечным прогнозом. Вероятность точной реализации такого прогноза крайне мала. Необходимо сопроводить его значение средней ошибки прогноза или доверительным интервалом прогноза с достаточно большой вероятностью.
Задача 1. Алмазы, возможно, вскоре станут использоваться в качестве полупроводников в спутниках связи. Теория предсказывает, что алмазные микросхемы будут более быстродействующими, термо - и радиационностойкими, что особенно важно для приборов, работающих в космосе. По оценкам экспертов, вероятности этих трех событий равны соответственно 0,9; 0,9 и 0,95. Предполагается, что обсуждение проекта по разработке алмазных микросхем стоит вести лишь в случае, если имеется хотя бы 70% уверенности в том, что они будут обладать всеми тремя указанными выше свойствами. Должен ли обсуждаться проект?
Задача 2. Исследованиями психологов установлено, что мужчины и женщины по-разному реагируют на некоторые жизненные обстоятельства. Результаты исследований показали, что 70% женщин позитивно реагируют на эти ситуации, в то время как 40% мужчин реагируют на них негативно. 15 женщин и 5 мужчин заполнили анкету, в которой отразили свое отношение к предлагаемым ситуациям. Случайно извлеченная анкета содержит негативную реакцию. Чему равна вероятность того, что её заполнял мужчина?
Литература: 1, 5, 8, 9
Тема 12. Корреляционный анализ
Признаки – факторы должны находиться в причинной связи с результативным признаком (следствием). Поэтому, недопустимо, например, в модель себестоимости ![]() вводить в качестве одного из факторов
вводить в качестве одного из факторов ![]() коэффициент рентабельности, хотя включение такого «фактора» значительно повышает коэффициент детерминации.
коэффициент рентабельности, хотя включение такого «фактора» значительно повышает коэффициент детерминации.
Признаки - факторы не должны быть составными частями результативного признака или его функциями, о чем уже сказано ранее.
Признаки - факторы не должны дублировать друг друга, т. е. быть коллинеарными (с коэффициентом корреляции более 0,8). Так, не следует в модель производительности включать и энерговооруженность рабочих, и их фондовооруженность, так как эти факторы тесно связаны друг с другом в большинстве объектов.
Не следует включать в модель факторы разных уровней иерархии, т. е. фактор ближнего порядка и его субфакторы. Например урожайность в моделях себе стоимости зерна не следует включать в урожайность зерновых культур, и дозу удобрений под них или затраты на обработку гектара, показатели качества семян, плодородия почвы, т. е. субфакторы самой урожайности.
Желательно, чтобы между результативным признаком и факторами соблюдалась единство единицы совокупности, к которой они отнесены. Например, если ![]() - валовой доход предприятия, то и все факторы должны относится к предприятию: стоимость производственных фондов, уровень специализации, численность работников, и. т.д. Если же
- валовой доход предприятия, то и все факторы должны относится к предприятию: стоимость производственных фондов, уровень специализации, численность работников, и. т.д. Если же ![]() - средняя заработная плата рабочего на предприятии, то факторы должны относится к рабочему: разряд или классность, стаж работы, возраст, уровень образования, энерговооруженность и т. д. Правило это не категоричное, в модель зарплаты рабочего можно включить, и уровень специализации предприятия
- средняя заработная плата рабочего на предприятии, то факторы должны относится к рабочему: разряд или классность, стаж работы, возраст, уровень образования, энерговооруженность и т. д. Правило это не категоричное, в модель зарплаты рабочего можно включить, и уровень специализации предприятия
Математическая формула уравнения регрессии должна соответствовать логике связи факторов с результатом в реальном объекте.
Проверка практической значимости синтезированных в корреляционно - регрессионном анализе математических моделей осуществляется посредством показателей тесноты связи между признаками ![]() и.
и. ![]()
Для статистической оценки тесноты связи применяются следующие
показатели вариации:
1.) общая дисперсия результативного признака ![]() , отображающая совокупность влияние всех факторов:
, отображающая совокупность влияние всех факторов:
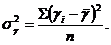
В формуле (1) отклонения ![]() обусловлены тем, что сочетание значений факторов, влияющих на вариацию признака
обусловлены тем, что сочетание значений факторов, влияющих на вариацию признака ![]() , для отдельных единиц анализируемой совокупности различно;
, для отдельных единиц анализируемой совокупности различно;
2.) факторная дисперсия результативного признака ![]() , отображающая вариацию
, отображающая вариацию ![]() только от воздействия изучаемого фактора
только от воздействия изучаемого фактора ![]() :
:
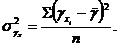
в формуле (2) отклонения ![]() характеризует колеблемость выровненных общих значений
характеризует колеблемость выровненных общих значений ![]() , от средней величины
, от средней величины ![]() ;
;
2.) остаточная дисперсия ![]() , отображающая вариацию результативного признака
, отображающая вариацию результативного признака ![]() от всех прочих кроме
от всех прочих кроме ![]() факторов:
факторов:
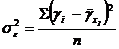
В формуле (3) отклонения ![]() характеризует колеблемость эмпирических (фактических) значений результативного признака
характеризует колеблемость эмпирических (фактических) значений результативного признака ![]() от их выровненных значений
от их выровненных значений ![]() ;
;
Соотношение между факторной ![]() и общей
и общей ![]() дисперсиями характеризует меру тесноты связи между признаками
дисперсиями характеризует меру тесноты связи между признаками ![]() и.
и. ![]()
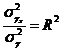
Показатель ![]() называется индексом детерминации (причинности). Он выражает долю факторной дисперсии в общей дисперсии т. е. характеризует, какая часть общей вариации результативного признака
называется индексом детерминации (причинности). Он выражает долю факторной дисперсии в общей дисперсии т. е. характеризует, какая часть общей вариации результативного признака ![]() объясняется изучаемым фактором
объясняется изучаемым фактором ![]() .
.
На основе формулы (4) определяется индекс корреляции ![]() :
:
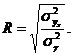
Задача 1. Отдел маркетинга фирмы проводит опрос для выяснения мнений потребителей по определенному типу продуктов. Известно, что в местности, где проводятся исследования, 10% населения являются потребителями интересующего фирму продукта и могут дать ему квалифицированную оценку. Компания случайным образом отбирает 10 человек из всего населения. Чему равна вероятность того что, по крайней мере, один человек из них может квалифицированно оценить продукт?
Задача 2. Из числа авиалиний некоторого аэропорта 60% – местные, 30% – по СНГ и 10% – в дальнее зарубежье. Среди пассажиров местных авиалиний 50% путешествуют по делам, связанным с бизнесом, на линиях СНГ таких пассажиров – 60%, на международных – 90%. Из прибывших в аэропорт пассажиров случайно выбирается один. Чему равна вероятность того, что он:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
