


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
P4,0 = C400.20× 0,84 = 0,4096, P4,1 = C410.21× 0,83 = 0,4096,
P4,2 = C42× 0.22× 0,82 = 0,1536, P4,3 = C43× 0.23× 0,81 = 0,0256,
P4,4 = C44× 0.44× 0,80 = 0,0016.
Таблица 4.12
Гипергеометрическое распределение
m | 0 | 1 | 2 | 3 | 4 |
P4,m | 0,4096 | 0,4096 | 0,1536 | 0,0256 | 0,0016 |
3. В примере 4.12, где отношение n/N мало (n/N = 2/20 = 0,1), расхождение вероятностей, вычисленных двумя способами (табл. 4.11 и 4.12), невелико. Его максимальное значение равно 0,005 (0,100–0,095). В примере 4.13, где отношение n/N в два раза больше (n/N = 4/20 = 0,2), максимальное расхождение достигает значительной величины – 0,052 (табл. 4.11 и 4.12).
В случае выбора из большой генеральной совокупности биномиальное распределение более удобно, чем гипергеометрическое. Важно понять, однако, что гипергеометрическое распределение – более корректно для выборок без возврата.
Вообще при достаточно большом значении N и малом объеме выборки п (когда ![]() ) гипергеометрическое распределение практически совпадает с биномиальным. Кроме того, при условии
) гипергеометрическое распределение практически совпадает с биномиальным. Кроме того, при условии ![]() гипергеометрическое распределение является трехпараметрическим (N, К, п), табулирование которого затруднено, и его можно аппроксимировать двухпараметрическим (n, р) биномиальным.
гипергеометрическое распределение является трехпараметрическим (N, К, п), табулирование которого затруднено, и его можно аппроксимировать двухпараметрическим (n, р) биномиальным.
4.7. Производящая функция
Выше были рассмотрены способы определения вероятности Рn, m для случаев, когда вероятность события А во всех п независимых испытаниях одна и та же. На практике приходится встречаться и с такими случаями, когда вероятность наступления события А от испытания к испытанию меняется.
Пример 4.14. Устройство состоит из трех независимо работающих элементов. Вероятность безотказной работы (за время t) первого элемента равна 0,9, второго – 0,8 и третьего – 0,7. Составим закон распределения числа элементов, вышедших из строя.
Пусть проведено два независимых испытания. Вероятность появления события А в первом из них – p1, во втором – р2; вероятности непоявления события А соответственно равны q1 = 1– p1; q2 = 1– р2. Требуется определить вероятности P2,0, P2,1, P2,2, т. е. вероятности появления события А ровно 0 раз, ровно 1 раз и ровно 2 раза в двух независимых испытаниях.
Решение. Применяя теорему сложения вероятностей для несовместных событий и теорему умножения для независимых событий, получим: P2,0 = q1q2; P2,1 = p1q2 + q1p2; P2,2 = p1p 2. Пусть теперь проведено три независимых испытания с вероятностями появления события А: p1, p2, p3. Вероятности непоявления события А в первом, во втором и третьем опытах соответственно равны q1 = 1– p1, q2 = 1– р2, q3 = 1– р3. Определим вероятности P3,0, P3,1, P3,2, P3,3, т. е. вероятности появления события А ровно 0 раз, ровно 1 раз, ровно 2 раза и ровно 3 раза в трех независимых испытаниях.
Применяя теорему сложения вероятностей несовместных событий и теорему умножения вероятностей для независимых событий, получим: P3,0 = q1q2 q3; P3,1 = p1q2q3 + q1p2q3 + q1q2p3; P3,2 = p1p2q3 + p1q2p3 + q1p2p3; P3,3 = p1p2p3.
Эти вероятности можно получить, если перемножить три бинома
![]() и привести подобные члены. Тогда коэффициенты при zm будут соответствовать вероятностям P3,m(m = 0, 1, 2, 3). Здесь z произвольный параметр. Для n независимых испытаний получим
и привести подобные члены. Тогда коэффициенты при zm будут соответствовать вероятностям P3,m(m = 0, 1, 2, 3). Здесь z произвольный параметр. Для n независимых испытаний получим
![]()
![]() ·
·
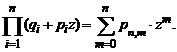 Выражение
Выражение 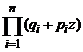 обозначают
обозначают
![]() и называют производящей функцией.
и называют производящей функцией.
4.8. Мультиномиальное распределение
Напомним, что в биномиальном эксперименте мы классифицируем исходы как успехи и неуспехи. Если обобщить ситуацию, то исходы можно классифицировать более чем по двум категориям. Предположим, есть k категорий исходов: «покупка товара А», «покупка товара В», «покупка товара К». Обозначим Х1 – число проданных единиц товара A, Х2 – число проданных единиц товара В,...., Хk – число проданных единиц товара К. Вероятностное распределение Х1, Х2,..., Хk в выборке объемом п есть мультиномиальное распределение с параметрами п и вероятностями р1, р2,…, рk, где рi – вероятность появления категории i (рi = 1 – qi), и они остаются неизменными от испытания к испытанию и испытания независимы.
Формула мультиноминального распределения имеет следующий вид:
P(Х1, Х2,., Хk) = n!/(Х1! Х2! ...∙Хk!)∙р1x1∙р2x2 ·…∙рkxk. (4.17)
Пример 4.15. Предположим, что из общего числа семей, живущих на данной территории, 25 % имеют душевые доходы ниже прожиточного минимума (черты бедности), 35 % имеют доходы, равные среднедушевым доходам, у 20 % доходы в полтора раза выше средних, а у остальных 20 % семей доходы в два и более раза превышают средний душевой доход для данной территории. Пусть А1 – случайное событие, состоящее в случайном отборе семьи, которая принадлежит к первой группе. А2, А3 и А4 – аналогичные события, состоящие в случайном отборе семей, которые принадлежат соответственно ко второй, третьей и четвертой доходным группам.
По условию p1 = 0,25; р2 = 0,35; р3 = 0,20; р4 = 0,20. Предположим, что для целей обследования необходимо провести случайный повторный отбор 50 семей для обследования уровня жизни населения. Определим вероятность того, что все отобранные семьи будут бедными (с доходом ниже прожиточного минимума).
Решение. По формуле (4.17) имеем: P(Х1 = 50, Х2 = 0, Х3 = 0, Х4 = 0) = 50!/(50!∙0!∙0!∙0!)∙0,2550∙0,350∙0,200∙0,200 = 0,2550 ≈ 0.
4.9. Геометрическое распределение
Рассмотрим биномиальный эксперимент с обычными условиями. Пусть вместо вычисления числа успехов в независимых испытаниях случайная величина определяет число испытаний до первого успеха. Такая случайная величина распределена по закону геометрического распределения. Вероятности геометрического распределения вычисляются по формуле
P(m) = pqm–1, (4.I8)
где т = 1, 2, 3, ...; p и q – биномиальные параметры. Математическое ожидание геометрического распределения
M(m)= 1/p, (4.19)
а дисперсия σ2 = D(m) = q/p
Например, число деталей, которые мы должны отобрать до того, как найдем первую дефектную деталь, есть случайная величина, распределенная по геометрическому закону. В чем здесь смысл математического ожидания? Если доля дефектных деталей равна 0, 1, то вполне логично, что в среднем мы будем иметь выборки, состоящие из 10 деталей до тех пор, пока не встретим дефектную деталь.
Пример 4.16. Исследования в некотором регионе показали, что пепси-кола занимает 33,2 % рынка безалкогольных напитков, а кока-кола 40,9 %. Исследователи рынка собираются провести новое исследование, чтобы проверить вкусы и предпочтения потребителей пепси-колы. Потенциальные участники отбираются случайным образом среди потребителей безалкогольных напитков. Определим вероятность того, что случайно отобранный потребитель пьет пепси-колу. Рассчитаем вероятность того, что среди (двух, трех, четырех) отобранных потребителей безалкогольных напитков первым будет найден потребитель пепси-колы.
Решение. Пусть «успех» в единичном испытании с вероятностью 0,332 есть событие «первый случайно отобранный потребитель предпочитает пепси-колу». Используя геометрическое распределение при т=1, найдем из формулы (4.18): Р(1) = 0,332∙0,6880 = 0,332. Точно так же первый выбранный человек не будет, а второй будет потребителем пепси-колы с вероятностью P(2) = 0,332∙0,6881 = 0,2218. Вероятность того, что двое потребителей, не употребляющих пепси-колу, будут проинтервьюированы до того, как первый потребитель пепси-колы будет найден, равна P(3) = 0,332∙0,6882 = 0,1481. И окончательно P(4) = 0,332∙0.6883 = 0,099.
5. Непрерывные случайные величины
5.1. Определение непрерывной случайной величины. Функция распределения непрерывной случайной величины
Непрерывной случайной величиной называют случайную величину, которая может принимать любые значения на числовом интервале.
Примеры непрерывных случайных величин: возраст студентов, длина ступни ноги человека, масса детали и т. д. Это положение относится ко всем случайным величинам, измеряемым на непрерывной шкале, таким как меры веса, длины, времени, температуры, расстояния. Измерение может быть проведено с точностью до какого-нибудь десятичного знака, но случайная величина – теоретически непрерывная величина. В экономическом анализе находят широкое применение относительные величины, различные индексы экономического состояния, которые также вычисляются с определенной точностью, скажем, до двух знаков после запятой, хотя теоретически их значения – непрерывные случайные величины.
У непрерывной случайной величины возможные значения заполняют некоторый интервал (или сегмент) с конечными или бесконечными границами.
Закон распределения непрерывной случайной величины можно задать в виде интегральной функции распределения, являющейся наиболее общей формой задания закона распределения случайной величины, а также в виде дифференциальной функции (плотности распределения вероятностей), которая используется для описания распределения вероятностей только непрерывной случайной величины.
Функция распределения (или интегральная функция) F(x) – универсальная форма задания закона распределения случайной величины. Для непрерывной случайной величины функция распределения также определяет вероятность того, что случайная величина X примет значение, меньшее фиксированного действительного числа х, т. е.
F(x) = F(X < x). (5.1)
При изменении х меняются вероятности Р(Х < x) = F(x). Поэтому F(x) и рассматривают как функцию переменной величины. Принято считать, что случайная величина X известна, если известна ее функция распределения F(x).
Теперь можно дать более точное определение непрерывной случайной величины: случайную величину называют непрерывной, если ее функция распределения есть непрерывная, кусочно-дифференци-руемая функция с непрерывной производной.
5.2. Свойства функции распределения (для дискретных и непрерывных случайных величин)
1. Функция распределения есть неотрицательная функция, заключенная между 0 и 1, т. е. 0 ≤ F(x) ≤ 1.
2. Функция распределения есть неубывающая функция, т. е. F(x2) ≥ F(x1), если х2 > х1. Тогда P(x1 ≤ Х < х2) = P(Х < х2) – P(Х < х1) = F(x2) – F(x1).
Так как любая вероятность есть число неотрицательное, то P(x1 ≤ ≤ Х < х2) ³ 0, а следовательно, F(x2) – F(x1) ≥ 0 и F(x2) ≥ F(x1).
Следствие 1. Вероятность того, что случайная величина X примет значение, заключенное в интервале (α, β), равна приращению функции распределения на этом интервале, т. е.
P(α ≤ Х < β) = F(β) – F(α). (5.2)
Следствие 2. Вероятность того, что непрерывная случайная величина X примет одно определенное значение, равна нулю.
Р(Х = х1) =
Согласно сказанному, равенство нулю вероятности Р(Х = х1) не всегда означает, что событие Х = х1 невозможно. Говоря о вероятности события Х = х1, априорно пытаются угадать, какое значение примет случайная величина в опыте.
Если х1 лежит в области возможных значений непрерывной случайной величины X, то с некоторой уверенностью можно предсказать область, в которую случайная величина может попасть. В то же время невозможно хотя бы с малейшей степенью уверенности угадать, какое конкретное значение из бесконечного числа возможных примет непрерывная случайная величина.
Например, если метеослужба объявляет, что температура воздуха в полдень составила 5 °С, то это не означает, что температура будет точно равна этому значению. Вероятность такого события равна нулю.
3. Если все возможные значения случайной величины принадлежат интервалу (α, β), то
F(х) = 0 при х ≤ α; F(х) = 1 при х > β. (5.4)
В самом деле, F(x) = 0 для всех значений х ≤ α и F(х) = 1 при х > β, поскольку события X < х для любого значения х ≤ α, являются в этом случае невозможными, а для любого значения х > β – достоверными.
Следствие. Если возможные значения непрерывной случайной личины расположены на всей оси ОХ, то справедливы следующие предельные соотношения:
![]()
![]() , (5.5)
, (5.5)
или F(– ∞) = 0; F(+ ∞) = 1. Это следствие справедливо и для дискретных случайных величин.
5.3. График функции распределения для непрерывной случайной величины
Из перечисленных выше свойств F(х) может быть представлен график функции распределения (рис. 5.1).
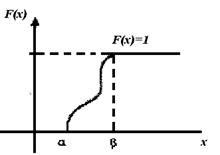
Рис. 5.1. График функции распределения непрерывной случайной величины
График функции распределения смешанной случайной величины – кусочно-непрерывная функция (рис. 5.2).

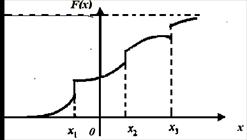
Рис. 5.2. График кусочно-непрерывной функции распределения
5.4. Плотность распределения вероятностей непрерывной случайной величины
(дифференциальная функция)
Плотностью распределения вероятностей непрерывной случайной величины X называется функция W(x), равная первой производной от функции распределения F(x),
W(x) = F ′(x), (5.6)
где W(x) – дифференциальная функция распределения. Дифференциальная функция применяется только для описания распределения вероятностей непрерывных случайных величин.
5.5. Вероятность попадания непрерывной случайной величины в заданный интервал
Вероятность того, что непрерывная случайная величина примет значение, принадлежащее интервалу (α, β), равна определенному интегралу от дифференциальной функции, взятому в пределах от α до β,
P(α < X < β) = . (5.7)
Используя соотношения (5.2) и (5.1), получим P(α ≤ X < β) = P(α < < X < < β) = 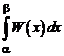 .
.
Геометрически этот результат равен площади криволинейной трапеции, ограниченной осью ОХ, кривой распределения W(x) и прямыми х = α, х = β.
5.6. Нахождение функции распределения по известной плотности распределения
Зная плотность распределения W(x), можно найти функцию распределения F(x) по формуле
F(x) = . (5.8)
В самом деле, так как неравенство X < х можно записать в виде двойного неравенства – ∞ < X < х, то F(x) = P(– ∞ < X < х) = (рис. 5.3).
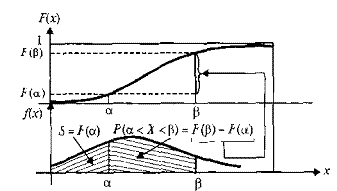
Рис. 5.3. Связь функции распределения с плотностью распределения вероятностей
Таким образом, для полной характеристики непрерывной случайной величины достаточно задать функцию распределения или плотность ее вероятности.
5.7. Свойства дифференциальной функции распределения
1. Дифференциальная функция – неотрицательная функция:
W(x) ≥
Это следует из того, что F(x) – неубывающая функция, а значит, ее производная неотрицательна.
2. Несобственный интеграл от дифференциальной функции в пределах от – ∞ до + ∞ равен 1
. (5.10)
Очевидно, что этот интеграл выражает вероятность достоверного события – ∞ < Х + ∞.
5.8. Числовые характеристики непрерывных случайных величин
Математическим ожиданием непрерывной случайной величины называется несобственный интеграл вида
М(Х) =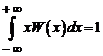 . (5.11)
. (5.11)
Дисперсией непрерывной случайной величины называется несобственный интеграл вида
D(x) = σ2 =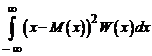 . (5.12)
. (5.12)
Средним квадратическим отклонением непрерывной случайной величины называется квадратный корень из дисперсии
σ = . (5.13)
Для числовых характеристик непрерывных случайных величин справедливы те же свойства, что и для дискретных. В частности, для дисперсии непрерывной случайной величины справедлива формула
D(X)= . (5.14)
Начальным моментом k-го порядка (mk) случайной величины X называется математическое ожидание ее k-й степени:
для дискретной случайной величины mk= ;
для непрерывной случайной величины mk = 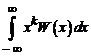 . (5.15)
. (5.15)
Центральным моментом k-го порядка (μк) случайной величины X называют математическое ожидание k-й степени отклонения случайной величины X от ее математического ожидания:
для дискретной случайной величины μk = ;
для непрерывной случайной величины
μk =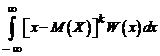 . (5.16)
. (5.16)
Заметим, что начальный момент первого порядка m1 представляет собой математическое ожидание случайной величины, а центральный момент второго порядка μ2 – дисперсию случайной величины.
Центральный момент третьего порядка применяется для характеристики скошенности или асимметрии распределения (коэффициент асимметрии):
β1 = μ3/σ3. (5.17)
Для симметричных распределений β1 = 0. Центральный момент 4-го порядка применяется для характеристики крутости (эксцесса) распределения (неприведенный коэффициент эксцесса):
β2 = μ4/σ4. (5.18)
Часто в практических ситуациях используют квадрат коэффициента асимметрии и приведенный коэффициент эксцесса.
γ1 = β12 = μ23/σ6; γ2 = β2 –3 = μ4/σ4–3.
Величина хр, определяемая равенством F(xp) = Р(Х < хр), называется квантилью уровня p. Квантиль х0,5 называется медианой. Значение х, при котором W(x) принимает максимальное значение, называется модой.
6. Законы распределения непрерывных случайных величин
6.1. Нормальное распределение
Наиболее важным распределением непрерывных СВ является нормальное распределение. Множество явлений в практической жизни можно описать с его помощью, например, высоту деревьев, площади садовых участков, массу людей, дневную температуру и т. д. Оно используется для решения многих проблем в экономической жизни, например, число дневных продаж, число посетителей универмага в неделю, число работников в некоторой отрасли, объемы выпуска продукции на предприятии и т. д.
Нормальное распределение находит широкое применение и для аппроксимации распределения дискретных СВ, например, доходы от определенных видов рискованного бизнеса.
Нормальное распределение иногда называют законом ошибок, например, отклонения в размерах деталей от установленного.
Нормальная СВ имеет плотность распределения:
(6.1)
где | х<∞, а=М(Х), λ=σ(Х).
Основные свойства W(x):
а) W(x)>0 и существует при любых действительных значениях х;
б) при | х|→∞ limW(x)=0;
в) W(x=а)=Wmax(x).
г) W(x) симметрична относительно прямой х=а.
д) W(x) имеет две точки перегиба, симметричные относительно прямой х=а; с абсциссами а–λ и а+λ и ординатами 1/(λ√2π).
Формула (6.1) содержит два параметра: математическое ожидание а=М(Х) и стандартное отклонение λ=σ. Существует бесконечно много нормально распределенных СВ с разными M(Х) и σ(X).
Математическое ожидание а характеризует положение кривой распределения на оси абсцисс. Изменение параметра а при неизменном σ приводит к перемещению оси симметрии (х=а) вдоль оси абсцисс и, следовательно, к соответствующему перемещению кривой распределения. М(Х)=а иногда называют центрам распределения или параметром сдвига.
Изменение среднего квадратического отклонения при фиксированном значении математического ожидания приводит к изменению формы кривой распределения. С уменьшением λ вершина кривой распределения будет подниматься, кривая будет более «островершинной». С увеличением λ кривая распределения менее островершинная и более растянута вдоль оси абсцисс.
Одновременное изменение параметров a и λ приведет к изменению и формы, и положения кривой нормального распределения.
Условимся о форме записи СВ X~D(X;М(Х),σ2), что означает: СВ X подчиняется закону распределения D с математическим ожиданием М(Х) и стандартным отклонением, либо дисперсией σ2.
6.2. Стандартное (нормированное) нормальное распределение
Если в формуле (6.1) а=0; λ=1, то
![]() = (6.2)
= (6.2)
– стандартное (нормированное) нормальное распределение.
Стандартная нормальная СВ обозначается Z~N(X;0,12). Оно табулировано.
Свойства функции φ(z):
а) функция ω(z) – четная, т. е. ω(z)= ω(–z);
б) при |z|→∞ W(z)→0; при |z|>5 можно считать, что ω(z)=0. В связи с этим таблицы ограничиваются аргументами z=4 или z=5;
г) максимальное значение функция ω(z) принимает при z=0.
Любая нормально распределенная СВ может быть преобразована в стандартную (нормированную) нормально распределенную СВ действием:
Z=(X-a)/ λ. (6.3)
Обратное преобразование стандартной нормальной СВ Х~N (X;a,λ2):
X=a+Z∙λ. (6.4)
6.3. Вероятность попадания в интервал нормально распределенной СВ. Интегральная функция Лапласа–Гаусса и ее свойства. Связь нормальной функции распределения с интегральной функцией Лапласа–Гаусса
Если СВ задана плотностью распределения W(x), то вероятность того, что X примет значение, принадлежащее интервалу (α, b), определяется:
P(a<X<b) .
Если СВ X~N(X; a, λ2), то
P(a<X<b)=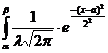 dx.
dx.
Чтобы пользоваться таблицами для вычисления вероятностей, преобразуем X в Z и найдем новые пределы интегрирования. При х=a, z=(a–а)/λ; при х=b, z=(b–а)/λ, x=a+λz, dx=λdz. Тогда
P(a<X<b)=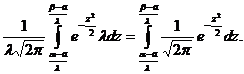
Функция вида
(6.5)
называется интегралом вероятностей или функцией Лапласа.
Функция Лапласа в общем виде не берется. Ее можно вычислить одним из способов численного интегрирования. Эта функция табулирована. Пользуясь функцией Лапласа, окончательно получим:
P(a<X<b)= . (6.6)
Формула (6.6) называется интегральной теоремой Лапласа.
Свойства F0(z):
а) F0(z) – нечетная; т. е. F0(–z)=-F0(z);
б) при z=0 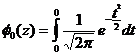 =0;
=0;
в) при z®+∞ F0(z)® 0,5; при z®–∞ F0(z)® –0,5. Ф0(4)=0,
Ф0(–4) = –0, т. е. при úzú>4 можно считать, что Ф0(z)»±0,5.
Следовательно, все возможные значения интегральной функции Лапласа-Гаусса принадлежат интервалу (0,5; +0,5).
Итак, функция распределения СВ, подчиняющейся нормальному закону распределения, представленная через функцию Лапласа есть:
F(x)=0,5+Фо[(x–a)/λ]. (6.7)
Во многих ситуациях может быть рассмотрена задача обратная предыдущей: определение z по заданной вероятности попадания случайной величины в интервал.
6.4. Правило «трех сигм»
Если обозначить (X–a)/σ=Z, Δ=(X–a)=σZ, то:
P(|X–a|<Zσ)=2Ф0(z), (6.8)
где 2Ф0(z) – вероятность того, что отклонение СВ от ее математического ожидания М(Х)=а по абсолютной величине будет меньше z сигм.
Пусть z равно: 1; 2; 3. Пользуясь формулой (6.8) и таблицей интеграла вероятностей, вычислим вероятность того, что отклонение по абсолютной величине будет меньше σ, 2σ и Зσ:
при z=1, Δ=σ и P(|X–a|< σ)=2Ф0(1)=0,6826;
при z=2, Δ=2σ и P(|X–a|<2σ)=2Ф0(2)=0,9544;
при z=3, Δ=3σ и P(|X–a|<3σ)=2Ф0(3)=0,9973.
Вероятность того, что СВ попадет в интервал (а–3σ; а+3) равна 0,9973.
Т. е. вероятность того, что отклонение СВ от математического ожидания по абсолютной величине превысит утроенное σ, очень мала и равна 0,0027. В этом состоит правило «трех сигм»: если СВ распределена по нормальному закону, то ее отклонение от математического ожидания практически не превышает ±3σ.
6.5. Понятие о теоремах, относящихся к группе «центральной предельной теоремы»
В теоремах этой группы выясняются условия, при которых возникает нормальное распределение. Общим для этих теорем является следующее: закон распределения суммы достаточно большого числа независимых СВ при некоторых условиях неограниченно приближается к нормальному.
Познакомимся с содержанием (без доказательства) с одной из теорем.
Ø Центральная предельная теорема для одинаково распределенных слагаемых (теорема П. Леви).
Теорема. Если независимые СВ Х1, Х2,… Хn, имеют один и тот же закон распределения с математическим ожиданием а и дисперсией σ2, то при неограниченном увеличении n закон распределения суммы Х1+Х2+…+Хn неограниченно приближается к нормальному.
Теорема Ляпунова. Если СВ Y представляет собой сумму большого числа независимых СВ Y1, Y2,… Yn, влияние каждой из которых на всю сумму равномерно мало, то величина Y имеет распределение, близкое к нормальному, и тем ближе, чем больше п.
Ценно то, что законы распределения суммируемых СВ могут быть любыми, заранее не известными исследователю. Практически данной теоремой можно пользоваться и тогда, когда речь идет о сумме сравнительно небольшого числа СВ. Опыт показывает, что при числе слагаемых около 10 закон распределения суммы близок к нормальному.
Теорема Ляпунова имеет важное практическое значение, поскольку многие СВ можно рассматривать как сумму независимых слагаемых (ошибки измерений, отклонения размеров деталей, распределение числа продаж некоторого товара, валютные курсы и т. д.)
6.6. Показательное (экспоненциальное) распределение
Экспоненциальное (показательное) распределение связано с распределением Пуассона, используемым для вычисления вероятности появления события в некоторый период времени. Распределение Пуассона – это распределение числа появления событий в заданный интервал времени длиной t. Параметр распределения Пуассона λ характеризует интенсивность процесса, с его помощью вычисляют среднее число появления события.
Например, в банк в среднем входит пять посетителей в час. Предположим теперь, что вместо числа появления события в заданный промежуток времени нас интересует длина промежутка времени до появления первого посетителя в банке. Такая задача решается при помощи экспоненциального распределения, а не распределения Пуассона.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
