


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Другие примеры. Интервалы времени до первого телефонного звонка на станцию, время ожидания такси – подчиняются экспоненциальному закону.
Обозначив среднее значение появления событий в некоторый промежуток времени через λ, а время до появления первого события х=t, можно получить дифференциальную функцию экспоненциального распределения:
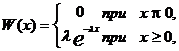 (6.9)
(6.9)
где х³0, λ>0 – параметр. Функция экспоненциального закона:
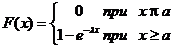 . (6.10)
. (6.10)
Числовые характеристики экспоненциально распределенной СВ X: М(Х)=1/λ, D(x)=1/λ2,s(x)=1/λ.
6.7. Закон равномерного распределения (равномерной плотности)
Если известно, что значения непрерывной СВ принадлежат определенному интервалу, а ее плотность распределения на интервале постоянна, то СВ распределена по равномерному закону.
В равномерном распределении вероятность того, что СВ будет принимать значения внутри заданного интервала, пропорциональна длине этого интервала.
Пусть непрерывная СВ X распределена на интервале (α;β) с равномерной плотностью. Ее плотность W(х) на этом участке постоянна и равна C. Вне этого интервала она равна нулю, так как СВ X за пределами интервала (α; β) значений не имеет. Найдем значение постоянной С. Площадь, ограниченная кривой плотности распределения вероятностей и осью абсцисс, должна быть равна единице, т. е. С(β–α)=1.
Следовательно, С=1/(β–α) и плотность для равномерного распределения:
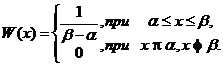 (6.14)
(6.14)
Функция распределения (6.15)
Числовые характеристики равномерно распределенной СВ: М(Х)=(α+β)/2, D(x)=(β–α)2/12, s(x)=√D(x)=(β–α)/2√3.
Для непрерывной равномерно распределенной СВ X, заданной на интервале (a<X<b)
P(a<X<b)=(b–a)/(β–α). (6.19)
7. Закон больших чисел
7.1. Принцип практической уверенности. Формулировка закона больших чисел
в литературе этот принцип иногда называется принципом практической невозможности маловероятных событий. Известно, что если событие имеет очень малую вероятность, то в единичном испытании это событие может наступить и не наступить. Но так рассуждаем мы только теоретически, а на практике считаем, что событие, имеющее малую вероятность, не наступает, и поэтому мы, не задумываясь, пренебрегаем им.
Но нельзя дать ответ в рамках математической теории на вопрос, какой должна быть верхняя граница вероятности, чтобы можно было назвать «практически невозможными» события, вероятности которых не будут превышать найденной верхней границы.
Пример. Рабочий изготавливает на станке 100 изделий, из которых одно в среднем оказывается бракованным. Вероятность брака равна 0,01, но ею можно пренебречь и считать рабочего неплохим специалистом. Но если строители будут строить дома так, что из 100 домов (в среднем) в одном доме будет происходить разрушение крыши, то вряд ли можно пренебречь вероятностью такого события.
Итак, в каждом отдельном случае мы должны исходить из того, насколько важны последствия в результате наступления события. При «практически достоверных» событиях, вероятность которых близка к единице, также встает вопрос о степени этой близости. Вероятность, которой можно пренебречь в исследовании, называется уровнем значимости.
Принцип практической уверенности. Если какое-нибудь событие имеет малую вероятность (например, р < 0.01), то при единичном испытании можно практически считать, что это событие не произойдет, а если событие имеет вероятность, близкую к единице (р > 0,99), то практически при единичном испытании можно считать, что событие произойдет наверняка.
Таким образом, исследователя всегда должен интересовать вопрос, в каком случае можно гарантировать, что вероятность события будет как угодно близка к 0 или как угодно близка к 1. Основной закономерностью случайных массовых явлений является свойство устойчивости средних результатов.
В широком смысле слова под «законом больших чисел» понимают свойство устойчивости случайных массовых явлений. Это свойство состоит в том, что средний результат действия большого числа случайных явлений практически перерастает быть случайным и может быть предсказан с достаточной определенностью. Свойство вытекает из того, что индивидуальные особенности отдельных случайных явлений, их отклонения от среднего результата в массе своей взаимно погашаются, выравниваются.
В узком смысле слова под «законом больших чисел» понимают совокупность теорем, в которых устанавливается факт приближения средних характеристик к некоторым постоянным величинам в результате большого числа наблюдений.
Различные формы закона больших чисел дают возможность уверенно оперировать случайными величинами, осуществлять научные прогнозы случайных явлений и оценивать точность этих прогнозов.
Формулировка закона больших чисел, развитие идеи и методов доказательства теорем, относящихся к этому закону, принадлежат русским ученым: , и A. M. Ляпунову. В нашей работе некоторые формы закона больших чисел приводятся без доказательства.
7.2. Неравенства Маркова и Чебышева
Доказательство закона больших чисел основано на неравенстве Чебышева. Неравенство Маркова в литературе иногда называется леммой Маркова или леммой Чебышева, так как оно является частным случаем неравенства Чебышева.
Лемма Маркова. Если случайная величина Х не принимает отрицательных значений, то для любого положительного числа α справедливо неравенство
P(Х ≥ α ) ≤ М(Х/α). (7.1)
События Х < α и Х ≥ α – противоположные, поэтому, используя (7.1), получаем
Р(Х < α ) = 1–Р(Х ≥ α ) ≥ 1– М(Х)/α . (7.2)
Выражения (7.1–7.2) справедливы для дискретных и непрерывных случайных величин.
Пример 7.1. Дана случайная величина X:
Xi | 2 | 4 | 6 | 8 | 10 | 12 |
Pi | 0,1 | 0,2 | 0,25 | 0,15 | 0,15 | 0,15 |
Пользуясь неравенством Маркова, оценим вероятность того, что случайная величина X примет значение, меньшее 11.
Решение. Исходя из условия, будем рассуждать так:
(Х < 11) = Р(X = 2) + Р(Х = 4)+ Р(Х = 6) + Р(Х = 8)+Р(Х = 10) =
= 0,1 + 0,2 + 0,25 + 0,15 + 0,15 = 0,85.
Используя неравенство Маркова (7.2), получаем
Р(Х < 11) ≥1 – М(Х)/11 = 1–(2·0,1 + 4·0,2 + 6·0,25 + 8·0,15 + 10·0,15 + 12·0,15)/11 = 1– (0,2 + 0,8 + 1,5 + 1,2 + 1,8)/11 = 1 – 7/11 = 1 – 0,636 = 0,364. Р(Х < 11) ≥ 0,364.
Пример 7.2. Сумма всех вкладов в некоторой сберегательной кассе составляетруб., а вероятность того, что случайно взятый вклад меньше , равна 0,8. Определим число вкладчиков сберегательной кассы.
Решение. Пусть X – величина случайно взятого вклада, а n – число всех вкладчиков. Тогда из условия задачи следует, что М(Х) =/n; Р(X < = 0,8, и по неравенству Маркова Р(X < ≥ 1– М(Х)/
Таким образом, 0,8 ≥ 1 –/ (n·;/ (n·≥ 0,2; 200 ≥ n·0,2; n ≤ 1000.
Неравенство Чебышева. Вероятность того, что отклонение X от ее математического ожидания по абсолютной величине будет меньше данного положительного числа ε, ограничена снизу величиной
1–D(X)/ε2, т. е. Р(|X – M(X)|< ε) ≥ 1–D(X)/ε2. (7.3)
Из (7.3) переходом к противоположному событию можно получить:
Р(|X–M(X) | ≥ ε) ≤ D(X)/ε2. (7.4)
Пример 7.3. Вероятность наступления некоторого события р = 0,3 в каждом из n = 900 независимых испытаний. Используя неравенство Чебышева, оценим вероятность того, что событие повторится число раз, заключенное в пределах от m1 = 240 до m2 = 300.
Решение. Здесь по условиям задачи имеет место биномиальный эксперимент. Следовательно, М(X) = а = пр = 900∙0,3 = 270;
ε = |240–270| = |300–270| = 30; D(X) = npq = 900∙0,3∙0,7 = 189;
Р(|X–270| < 30) ≥ 1 – D(X)/ε2 = 1–189/302 = 1–0,21 = 0,79,
т. е. Р(|X–270| < 30 ≥ 0,79.
7.3. Теорема Чебышева (частный случай)
Теорема устанавливает в количественной форме связь между средней арифметической наблюдаемых значений случайной величины X и М(X) = а.
Теорема. При неограниченном увеличении числа n независимых испытаний средняя арифметическая наблюдаемых значений случайной величины сходится по вероятности к ее математическому ожиданию, т. е. для любого положительного ε
Р(|![]() – а| < ε) =
– а| < ε) =
Смысл выражения «![]() сходится по вероятности к a» состоит в вероятности того, что будет сколь угодно мало отличаться от a, неограниченно приближаясь к 1 с ростом n. Для конечного n
сходится по вероятности к a» состоит в вероятности того, что будет сколь угодно мало отличаться от a, неограниченно приближаясь к 1 с ростом n. Для конечного n
Р(|![]() – M(X)| < ε) ≥ 1 –D(X)/(n∙ε2 (7.6)
– M(X)| < ε) ≥ 1 –D(X)/(n∙ε2 (7.6)
Если в (7.6) взять сколь угодно малое ε >0 и n® ¥, то
что и доказывает теорему Чебышева.
Из рассмотренной теоремы вытекает важный практический вывод. Он состоит в том, что неизвестное нам значение математического ожидания случайной величины мы вправе заменить средним арифметическим значением, полученным по достаточно большому числу опытов. При этом чем больше опытов для вычисления, тем с большей вероятностью (надежностью) можно ожидать, что связанная с этой заменой ошибка ( – а) не превзойдет заданную величину ε.
Кроме того, можно решать другие практические задачи. Например, по значениям вероятности (надежности) Р = Р(| – а|< ε и максимальной допустимой ошибке ε, определить необходимое число опытов n; по Р и п определить ε; по ε и п определить границу вероятности события | –а|<ε.
Пример 7.4. Дисперсия случайной величины X равна 4. Опредеим, сколько потребуется произвести независимых опытов, чтобы с вероятностью не менее 0,9 можно было ожидать, что среднее арифметическое значение этой случайной величины будет отличаться от математического ожидания менее чем на 0,5?
Решение. По условию задачи ε = 0,5; Р(| – а| < 0,5) ≥ 0,9; n = ? Применив формулу (7.6), получим P(|![]() – M(X)| < ε) ≥ 1–D(X)/(n∙ε2). Из соотношения 1–D(X)/(nε2) = 0.9 определяем п = D(X)/(0,1ε2) = 4/(0,1∙0,25) = 160.
– M(X)| < ε) ≥ 1–D(X)/(n∙ε2). Из соотношения 1–D(X)/(nε2) = 0.9 определяем п = D(X)/(0,1ε2) = 4/(0,1∙0,25) = 160.
Если использовать утверждение, что в любом случае средняя арифметическая распределена примерно нормально, то получаем:
Р(| –а|< ε) = 2Φ0(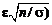 ≥ 0,9. Откуда, воспользовавшись таблицей интеграла вероятностей, получим
≥ 0,9. Откуда, воспользовавшись таблицей интеграла вероятностей, получим ![]() ≥ 1,645, или
≥ 1,645, или ![]() ≥ 6,58, т. е. n ≥ 49.
≥ 6,58, т. е. n ≥ 49.
Пример 7.5. Дисперсия случайной величины D(X) = 5. Произведено 100 независимых опытов, по которым вычислено ![]() . Вместо неизвестного значения математического ожидания а принята
. Вместо неизвестного значения математического ожидания а принята ![]() . Определим максимальную величину ошибки, допускаемой при этом, с вероятностью не менее 0,8.
. Определим максимальную величину ошибки, допускаемой при этом, с вероятностью не менее 0,8.
Решение. По условию n = 100, Р(|![]() – а|< ε) ≥ 0,8. ε = ? Применяем формулу (7.6)
– а|< ε) ≥ 0,8. ε = ? Применяем формулу (7.6)
Р(|![]() -а|< ε) ≥ 1–D(X)/(nε2).
-а|< ε) ≥ 1–D(X)/(nε2).
Из соотношения 1–D(X)/(nε2) = 0,8 определяем ε
ε2 = D(X)/(0,2∙n) = 5/(0,2∙100) = 0,25; ε = 0,5.
7.4. Теорема Бернулли
Пусть произведено п независимых испытаний, в каждом из которых вероятность появления некоторого события А постоянна и равна Р.
Теорема Бернулли. При неограниченном возрастании числа независимых испытаний п относительная частота m/n появления события А сходится по вероятности к вероятности p события А, т. е.
![]()
где ε – сколь угодно малое положительное число. Для конечного n при условии, что ![]() , неравенство Чебышева для случайной величины m/n будет иметь вид
, неравенство Чебышева для случайной величины m/n будет иметь вид
P(|m/n–p|< ε) ≥1– pq/(n ε
Каким бы малым ни было число ε, при n → ∞ величина дроби pq/(n∙ε2)→0, а P(|m/n–p|< ε)→1.
Из теоремы Бернулли следует, что при достаточно большом числе испытаний относительная частота т/п появления события практически утрачивает свой случайный характер, приближаясь к постоянной величине p – вероятности данного события. В этом и состоит принцип практической уверенности.
Пример 7.6. С целью установления доли брака по схеме возвратной выборки было проверено 1000 единиц продукции. Какова вероятность того, что установленная этой выборкой доля брака по абсолютной величине будет отличаться от доли брака по всей партии не более чем на 0,01, если что в среднем на каждыеизделий приходится 500 бракованных?
Решение. По условию задачи число независимых испытаний n = 1000.
p = 500/10 000 = 0,05; q = 1 – p = 0,95; ε = 0,01. P(|m/n–p| < 0,01?
Применив формулу (7.8), получим
P(|m/n–p| < 0,01) ≥ 1–pq/(nε2) = 1–0,05∙0,95/(1000∙0,0001) = 0,527.
Итак, с вероятностью не менее 0,527 можно ожидать, что выборочная доля брака (относительная частота появления брака) будет отличаться от доли брака во всей продукции (от вероятности брака) не более чем на 0,01.
Пример 7.7. При штамповке деталей вероятность брака составляет 0,05. Сколько нужно проверить деталей, чтобы с вероятностью не менее 0,95 можно было ожидать, что относительная частота бракованных изделий будет отличаться от вероятности брака менее чем на 0,01?
Решение. По условию задачи р = 0,05; q = 0,95; ε = 0,01.
P(|m/n–p|< 0,01) ≥ 0,95; n = ? Из равенства 1–pq/(nε2) = 0,95
находим:
n = pq/(0,05ε2) = 0,05∙0,95/(0,05∙0,0001) = 9500.
Замечание. Оценки необходимого числа наблюдений, получаемые при применении теоремы Бернулли (или Чебышева) очень преувеличены. Существуют более точные оценки, предложенные Бернштейном и Хинчиным, но требующие применения более сложного математического аппарата. Чтобы избежать преувеличения оценок, иногда пользуются формулой Лапласа
P(|m/n–p|<ε) ≈ 2Φ0 ![]() .
.
Недостатком этой формулы является отсутствие оценки допускаемой погрешности.
7.5. Теорема Пуассона
В теореме Бернулли устанавливается связь между относительной частотой появлений события и его вероятностью p при условии, что последняя от опыта к опыту не изменяется. Теорема Пуассона устанавливает связь между относительной частотой появления события и некоторой постоянной величиной при переменных условиях опыта.
Теорема Пуассона. Если производится n независимых опытов и вероятность появления события А в i-м опыте равна pi, то при увеличении n относительная частота появления события m/n сходится по вероятности к среднему арифметическому значению вероятностей pi, т. е.
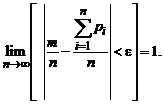 (7.9)
(7.9)
Для конечного n будем иметь:
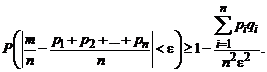 (7.10)
(7.10)
Каким бы ни было ε, при n→ ∞ величина дроби 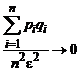 , а вероятность
, а вероятность
![]()
Пример 8.9. Одинаковые партии изделий размешены в 11 ящиках, причем доли первосортных изделий в них составляют 0,0; 0,1; 0,2; 0,3; 0,4; 0,5; 0,6; 0,7; 0.8; 0,9; 1,0. Из каждого ящика наудачу извлечено по одному изделию. Определим вероятность того, что доля первосортных изделий в выборке будет отличаться от средней арифметической доли менее чем на 0,2.
Решение. По условию задачи: n = 11; p1 = 0,0; p2 = 0,1; p3 = 0,2; p4 = = 0,3; p5 = 0,4; р6 = 0,5; p7 = 0,6; p8 = 0,7; p9 = 0,8; p10 = 0,9; p11 = 1,0; ε = 0,2.
Применив формулу (7.10), получим
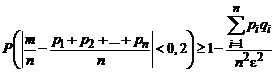 = 1–0,0 + 0,09 + 0,16 + 0,21 + 0,24 + 0,25 + 0,24 + 0,21 + 0,16 + 0,09 + 0,0)/(121∙0,04) = 1–1,165/4,84 = 0,64.
= 1–0,0 + 0,09 + 0,16 + 0,21 + 0,24 + 0,25 + 0,24 + 0,21 + 0,16 + 0,09 + 0,0)/(121∙0,04) = 1–1,165/4,84 = 0,64.
8. Первичная обработка данных.
Случайная величина – переменная величина, принимающая одно из возможных значений в зависимости от случайных обстоятельств. Случайная величина считается полностью заданной своим распределением, если указан закон, по которому можно вычислить вероятность попадания случайной величины в любое подмножество ее возможных значений.
Распределение вероятностей – совокупность всех возможных значений случайной величины и соответствующих им вероятностей.
Случайная величина называется дискретной, если она принимает конечное или счетной число значений. Дискретная величина задается с помощью ряда распределения – функции, ставящей в соответствие каждому возможному значению случайной величины определенную вероятность. Таким образом, ряд распределения - это конечное или счетное множество пар элементов:
![]()
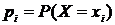
Так как случайная величина Х примет обязательно какое-нибудь из своих значений ![]() , сумма вероятностей
, сумма вероятностей ![]() всех возможных значений равно единице, т. е.
всех возможных значений равно единице, т. е. 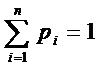 для случайной величины, принимающей конечное число n возможных значений, и
для случайной величины, принимающей конечное число n возможных значений, и 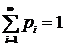 для дискретной случайной величины, принимающей счетное число значений.
для дискретной случайной величины, принимающей счетное число значений.
Обычно ряд распределения удобно изображать в виде таблицы, где в верхней строке указаны возможные значения ![]() дискретной случайной величины Х, в нижней – соответствующие вероятности того, что Х примет значение
дискретной случайной величины Х, в нижней – соответствующие вероятности того, что Х примет значение ![]() .
.
Х= 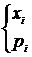
![]()
![]() .
.
Полигоном (многоугольником) распределения называется графическое изображение ряда распределения. Для того чтобы построить полигон распределения необходимо отложить возможные значения случайной величины ![]() по оси абсцисс, а соответствующие им вероятности по оси ординат.
по оси абсцисс, а соответствующие им вероятности по оси ординат.
Множество значений непрерывной случайной величины несчетно и обычно представляет собой некоторый промежуток, конечный или бесконечный. Непрерывная величина принимает возможные значения, заполняющие сплошь заданный интервал, причем для любого х из этого интервала существует предел:
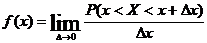
Функция![]() называется плотностью распределения или дифференциальным законом распределения.
называется плотностью распределения или дифференциальным законом распределения.
Плотность распределения обладает следующими свойствами:
1) ![]()
![]() ;
;
2) Для любых ![]() <
< ![]() выполняется равенство:
выполняется равенство: ![]() =
=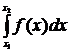
3) Интеграл по всей числовой прямой от плотности распределения вероятностей равен 1, т. е. ![]() .
.
4) Вероятность того, что непрерывная случайная величина примет конкретное значение, равна 0, т. е. ![]() .
.
График плотности распределения носит название кривой распределения. ![]()
Функцией распределения F(x) случайной величины Х, принимающей любое действительное значение x, называется вероятность того, что случайная величина Х приимет значение меньшее чем х, то есть 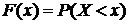 . Функцию распределения F(x) называют также интегральным законом распределения.
. Функцию распределения F(x) называют также интегральным законом распределения.
Для дискретной случайной величины функция F(x) вычисляется по формуле:
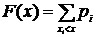 ,
,
где суммирование осуществляется по всем значениям i, для которых ![]() .
.
Для непрерывной случайной величины интегральный закон выражается формулой: 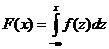 , где функция
, где функция ![]() - плотность распределения.
- плотность распределения.
Функцией распределения F(x) обладает следующими свойствами:
1) ![]() = F(x2) – F(x1);
= F(x2) – F(x1);
2) ![]() , если
, если ![]() ;
;
3) ![]() ;
;
4) ![]() ;
;
5)![]() (для непрерывной случайной величины).
(для непрерывной случайной величины).
График функции распределения F(x) для непрерывных случайных величин называется интегральной кривой распределения.
Числовые характеристики случайных величин. Функция распределения дает полную информацию о законе распределения случайной величины. Однако часто бывает достаточно знать одну или несколько числовых характеристик случайной величины, дающих наглядное представление о ней, например, некоторое «среднее» число, вокруг которого группируются значения случайной величины (центр группирования распределения), и ту или иную характеристику вариации значений случайной величины (степень рассеивания ее значений).
Основной характеристикой центра группирования случайной величины в генеральной совокупности является ее математическое ожидание. Выборочным аналогом математического ожидания является среднее значение ![]() .
.
Математическое ожидание М(х) дискретной случайной величины определяется по формуле: ![]() (8.1)
(8.1)
Если случайная величина Х непрерывна и ![]() - ее плотность распределения, то математическим ожиданием называется интеграл:
- ее плотность распределения, то математическим ожиданием называется интеграл:
![]() , (8.2)
, (8.2)
в тех случаях, когда существует интеграл ![]() .
.
Приведем без доказательств основные свойства математического ожидания.
1. Математическое ожидание постоянной равно этой постоянной, т. е. если с – постоянная, то М(Х)=с .
2. Постоянную величину можно выносить за знак математического ожидания, т. е. если Х – случайная величина, а с – постоянная, то М(сХ)=с*М(Х).
3. Математическое ожидание суммы случайных величин равно сумме математических ожиданий этих случайных величин, т. е. если определены МХ и МY, то определено математическое ожидание М(Х+Y), причем М(Х+Y)= МХ+ МY. Это свойство верно как для зависимых, так и независимых случайных величин.
4. Математическое ожидание произведения независимых случайных величин равно произведению математических ожиданий этих случайных величин, т. е. если Х и Y – независимые случайные величины, то М(ХY)= МХ* МY.
Модальное значение (или просто мода) Мо случайной величины определяется как такое возможное значение исследуемого признака, при котором значение плотности вероятности ![]() (в непрерывном случае) или вероятности
(в непрерывном случае) или вероятности ![]() (в дискретном случае) достигает своего максимума. Мода представляет собой наиболее часто встречающееся значение случайной величины.
(в дискретном случае) достигает своего максимума. Мода представляет собой наиболее часто встречающееся значение случайной величины.
Медиана Ме исследуемого признака определяется как его средневероятное значение, т. е. такое значение, которое обладает следующим свойством: вероятность того, что случайная величина окажется больше Ме , равна вероятности того, что она окажется меньше. Для обладающих непрерывной плотностью случайных величин выполняется условие:
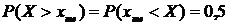 (8.3)
(8.3)
и медиану можно определить как такое значение ![]() на оси абсцисс, при котором прямая, параллельная оси ординат и проходящая через точку
на оси абсцисс, при котором прямая, параллельная оси ординат и проходящая через точку ![]() делит площадь под кривой плотности на две равные части. В некоторых случаях дискретных распределений может не существовать величины, точно удовлетворяющей сформулированному требованию. Поэтому для дискретных величин медиану можно определить как любое
делит площадь под кривой плотности на две равные части. В некоторых случаях дискретных распределений может не существовать величины, точно удовлетворяющей сформулированному требованию. Поэтому для дискретных величин медиану можно определить как любое ![]() , лежащее между соседними возможными значениями
, лежащее между соседними возможными значениями ![]() и
и ![]() , такими, что
, такими, что ![]() <0,5 и
<0,5 и ![]()
![]() 0,5.
0,5.
Характеристики вариации уточняют представление о распределении вероятностей случайной величины. Они дают представление о степени рассеивания случайной величины относительно центра группирования. Наиболее часто используемыми характеристиками вариации являются дисперсия случайной величины и ее среднеквадратическое отклонение.
Дисперсией случайной величины Х называется число DX , равное математическому ожиданию квадрата отклонения случайной величины от своего математического ожидания:
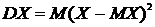 . (8.4)
. (8.4)
Если известен закон распределения случайной величины Х, то для дискретной и непрерывной случайных величин дисперсию можно вычислить соответственно по формулам:
![]() (8.5)
(8.5)
![]() , (8.6)
, (8.6)
где 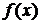 - плотность распределения случайной величины.
- плотность распределения случайной величины.
В качестве меры рассеивания случайной величины наряду с дисперсией используют среднеквадратическое отклонение ![]() , равное квадратному корню из дисперсии случайной величины:
, равное квадратному корню из дисперсии случайной величины: ![]() =
=![]() . (8.7)
. (8.7)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
