

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
7. Нити и процессы.. 245
8. Управление памятью. Типы адресов. Обзор методов распределения памяти. 248
9. Методы управления памятью без использования внешней памяти.. 250
10. Оверлеи. Виртуальная память. Способы организации виртуальной памяти.. 253
11. Свопинг и кэширование. 259
12. ОС. Управление вводом-выводом.. 262
13. Файловая система. Основные функции. Общая схема. 265
14. Логическая и физическая организация файлов. Права доступа к файлу. Кэширование файла. Отображение файла в оперативную память. Проблемы совместного использования. 269
XII. Теория вычислительных процессов и структур.. 274
1. Операции над формальными языками.. 274
2. Двоичное кодирование переменных и функций трехзначной логики.. 276
3. Перечислить способы представления конечного автомата. 278
4. Определение недетерминированного и конечного автомата. 280
5. Программная реализация логических функций.. 282
XIII. Архитектура вычислительных систем.. 284
1. Виды систем обработки данных. Режимы обработки данных. Сформулируйте различия между многомашинными вычислительными комплексами и вычислительными сетями. 284
2. Уровни комплексирования устройств в вычислительных системах. Постройте структурную схему ПЭВМ, состоящей из двух процессоров. Покажите на ней используемые уровни комплексирования. Ответ поясните. 286
3. Методы улучшения ОКОД структуры. Степень, уровни и виды параллелизма. Какой из видов параллелизма реализуется в современных универсальных процессорах (например, в процессоре Pentium)? Ответ обоснуйте. 289
4. Подсистема памяти. Методы повышения быстродействия памяти. Виды ЗУ. Иерархическая организация памяти. Какие вычислительные системы, на каком уровне иерархической организации требуют организации пакетного доступа к памяти. Ответ поясните. 292
5. Организация кэш-памяти. Зарисуйте структуру памяти (ОЗУ и кэш) для секторированного наборно-ассоциативного кэша, состоящего из трех банков. Поясните её. 295
6. Операционный и командный конвейер. Необходимые условия организации конвейеров этих типов. Режимы работы конвейеров. Объясните, почему при организации конвейера команд не целесообразно использовать Принстонскую архитектуру ЭВМ? 297
7. Многопроцессорные вычислительные комплексы (МПВК). Типы структур. Проблемы организации. Способы распределения ресурсов в МПВК. Сравните типы структур МПВК по следующим критериям: а) быстродействию; в) аппаратным затратам на систему коммутации; г) надежности. 300
8. Машины, управляемые потоком данных. Недостатки принципа управления потоком данных. Граф потока данных. Типы вершин графа потока данных. Можно ли использовать принцип управления потоком данных в конвейерных вычислительных системах? Ответ обоснуйте. 303
XIV. Практическая часть.. 305
1. Разработка баз данных. 305
2. UML диаграммы. 320
3. Написание технического задания. 327
4. Написание постановки задачи. 330
5. ГОСТ о стадиях разработки. 331
6. ГОСТ о техническом задании. 334
7. ГОСТ о видах программ и программных документов. 337
I. Структуры и алгоритмы обработки данных в ЭВМ.
1. Линейные списки. Стеки и очереди
Линейный список – это упорядоченная структура, каждый элемент которой связан со следующим элементом. Списки могут быть реализованы статически (на массивах) и динамически (на указателях).
Статические списки более просты в реализации, но у них есть недостатки:
1) они не обладают достаточной гибкостью при необходимости изменения их структуры,
2) память под них должна быть выделена на этапе компиляции и не будет освобождена до выхода из области действия списка.
Динамические списки характеризуются высокой гибкостью. Это достигается благодаря возможности выделять и освобождать память под элементы в любой момент времени работы программы и возможности установить связь между любыми 2-я элементами с помощью указателей. Для организации связей между элементами динамической структуры данных требуется, чтобы каждый элемент содержал кроме информационных значений как минимум 1 указатель. Поэтому, наиболее часто в качестве элементов списков используют записи, которые могут объединять в единое целое разнородные элементы. В простейшем случае элемент динамической структуры должен состоять из 2 полей: информационного и указательного. Схематично:
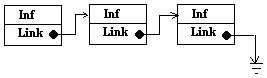
Наибольшее распространение получили два вида линейных односвязных списков: стеки и очереди. Очередью называется упорядоченный набор элементов, которые могут удаляться с одного его конца (называемого началом очереди) и помещаться в другой конец этого набора (называемого концом очереди). При работе с очередью первый помещенный в неё элемент удалится первым (т. е. реализуется принцип FIFO). Примеры - очередь в банке, на автобусной остановке, в ЭВМ – очередь на получение ресурсов, последовательность операций. При использовании массива начало очереди обычно находится в первом элементе, а конец задается индексом и меняется при изменении очереди. При создании динамической очереди требуются указатели: на начало очереди и на конец очереди. Кроме того, для освобождения памяти удаляемых элементов требуется дополнительный временный указатель:
Добавление элемента в очередь: | Удаление из очереди |
type TPtr=^Telem; Telem=record Inf:Real; Link:TPtr End; Var BegQ, EndQ:TPTr;{начало и конец} Procedure AddElement(Val:real); Var P:TPtr; Begin New(P); P^.Inf:=Val; P^.Link:=nil; If EndQ=nil {если создается 1-й эл-т} Then BegQ:=P {если очередной эл-т} Else EndQ^.Link:=P; EndQ:=P; End; | Procedure DelElement(var Val:Real); Var P:TPtr; Begin Val:=BegQ^.Inf; P:=BegQ; BegQ:=P^.Link; If BegQ=nil {если удаляется последний эл-т} Then EndQ:=nil; Dispose(P); End; |
Стек - частный случай линейного односвязного списка, для которого разрешено добавлять и удалять элементы только с одного конца списка, который называется вершиной (головой) стека. Т. о. элемент, помещенный в стек первым удалится из него последним (принцип FILO). В статическом представлении стек задается одномерным массивом, величина которого определяется с запасом. Необходимо обрабатывать ошибку переполнения и попытку удаления из пустого стека.
Для работы с динамическим стеком, в отличие от очереди, необходимо иметь один основной указатель на вершину стека и один дополнительный временный указатель, который используется для выделения и освобождения.
Кольцевой список – список, в котором последний элемент соединен с первым.

Достоинства. 1)Удобство создания структур данных для циклического обслуживания.
2) Из любого элемента можно попасть в любой. 3)Экономия памяти.
Двусвязные списки – списки, элементы которых имеют по 2 указателя – на правого и левого «соседа» по очереди. Удаление из таких списков происходит очень быстро и легко. Пример: удаление элемента kon в середине списка
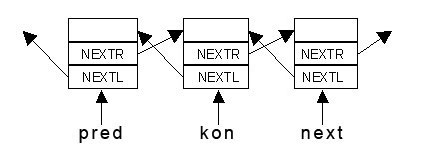
pred := kon^.nextL; next := kon^.nextR; pred^.nextR := next; next^.nextL := pred;
Мультисписок - связанный список, в котором каждый элемент без дублирования может находиться в нескольких подсписках. Вместе с указателем типа Next мультисписок имеет дополнительно столько указателей, сколько предусмотрено подсписков. Каждый подсписок может быть просмотрен отдельно. Например, общий список студентов может включать подсписки отличников, ударников и неуспевающих.
2. Деревья и способы их организации в памяти. Рекурсивные алгоритмы обхода бинарных деревьев.
Дерево – связный граф без циклов. Элемент дерева = вершина. Связь между вершинами – ребро. Первый элемент дерева = корень. Вершина, не имеющая потомков, = лист. Высота дерева = число уровней вершины. Степень вершины = количество потомков вершины. Степень дерева = макс. из степеней его вершин.
Деревья: бинарные (деревья со степень 2, т. е. у каждой вершины не >2 сына) и сильноветвящиеся (> 2 сына). Идеально сбалансированное дерево – дерево, в котором для любого узла число вершин в поддеревьях отличается не более чем на 1
Способы представления деревьев.
1)Список. Каждый элемент списка содержит информационную часть, ссылку на отца, список сыновей. Основной недостаток в неэффективном использовании памяти, особенно если число сыновей у вершин разное.
2)Упаковка в два списка. Первый список содержит описание вершины, а второй список вершины содержит ссылки на сыновей вершин. Описание вершины в первом списке = информ. часть, ссылка на отца, количество сыновей и ссылка на ту часть второго списка, с которой начинается перечисление сыновей вершины;
достоинство:экономичнее по памяти; недостаток:сложность корректировки
3)В СУБД часто исп-ся только 1 ссылка–на отца. Т. о. поиск сыновей=поиск всех записей с определенным значением поля отца (обход дерева снизу вверх).
3). Кодирование сильноветвящегося дерева с помощью бинарного.
Первый сын представляется левой ссылкой. Младший брат представляется правой ссылкой. Признак корня – отсутствие правого сына. Признак листа – отсутствие левого сына. Пример:
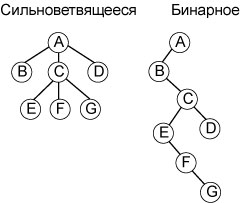
+компактная форма представления, удобство внесения изменений.
-левая и правая ветки в бинарном дереве имеют разный смысл.
Обходом дерева называется обработка всех его вершин в некотором порядке. Пусть есть дерево с корнем R и листьями A и B. Сущ. три стандартных обхода: сверху вниз(R, A, B), снизу вверх(A, B, R), слева направо(A, R, B). Эти варианты обхода можно обобщить на случай любого бинарного дерева. (Т. е. если вершина A= корень поддерева, то на поддерево рекурсивно распространяется вариант обхода.
Сверху вниз Procedure PechPr(T: ukaz); Begin if T<>Nil then Begin WriteLn(T^.Key); PechPr(T^.Left); PechPr(T^.Right); End; End; | Снизу вверх Procedure PechPr(T: ukaz); Begin if T<>Nil then Begin PechPr(T^.Left); PechPr(T^.Right); WriteLn(T^.Key); End; End; | Справа налево Procedure PechPr(T: ukaz); Begin if T<>Nil then Begin PechPr(T^.Left); WriteLn(T^.Key); PechPr(T^.Right); End; End; |
3. Представления графов с помощью матрицы смежности и списковых структур

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
