

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
real A, B,C ^, где ^ - конец цепочки
в стеке: real; вне A, B,C ^ в стеке: real А; вне, B,C ^ в стеке: real id; по 4-му правилу – свертка; вне, B,C ^ в стеке: real id “,“; вне B, C ^ в стеке: real id “,“ B; вне, C ^ в стеке: real id “,“ id; по 4-му правилу-свертка; вне, C ^ в стеке: real id “,“ id “,“; вне C ^ в стеке: real id “,“ id “,“ C; вне ^ в стеке: real id “,“ id “,“ id ; вне ^ в стеке: real id “,“ id “,“ idlist ; свертка по 3-му правилу ; вне ^ в стеке: real id “,“ idlist ; свертка по 2-му правилу; вне ^ в стеке: real idlist ; свертка по 2-му правилу; вне ^ в стеке: S вне ^ свертка по 1-му правилуВ методе восходящего разбора используются две операции. Первая операция – это сдвиг. Она состоит в том, что в стек заносится символ входной цепочки, и параллельно с этим происходит сдвиг по входной цепочке. Вторая операция – операция свертки. Она заключается в следующем: из верхушки стека достаются символы, которые сворачиваются по некоторому правилу.
Основной проблемой восходящего разбора является детерминированность, то есть на каждом шаге алгоритма хотелось бы знать, что производить сдвиг или свертку и по какому правилу. Все методы восходящего разбора отличаются друг от друга тем, как они определяют, что надо делать на каждом шаге: сдвиг или свертку.
При восходящем разборе слева направо на каждом шаге редуцируется основа (самая левая простая фраза) текущей сентенциальной формы и поэтому цепочка справа от основы всегда содержит только терминальные символы.
Проблема восходящего разбора состоит в следующем: при восходящем разборе на каждом шагу редуцируется основа. Как найти основу сентенциальной формы и то, к чему она должна приводиться?
Грамматика называется LR(0), если для всех состояний стека в процессе LR-вывода нет конфликтов сдвиг-свертка или свертка-свертка.
Для выбора между сдвигом или сверткой в LR(0) разборе используется только состояние стека. В LR(k) разборе учитывается также k-первых символов не просмотренной части входной цепочки (так называемая аванцепочка).
Существует три метода построения таблицы LR-анализа для грамматики:
1. метод, простой LR (simple LR, SLR) , является самым легким в реализации, но наименее мощным из них. Он не может построить таблицу разбора для некоторых грамматик, которые успешно обрабатываются другими методами.
2. канонический LR – наиболее мощный, но требующий наибольших ресурсов.
3. метод LR с предпросмотром (lookahead LR, или LALR), по мощности и требуемым ресурсам занимает промежуточное положение. Метод LALR работает с большинством грамматик и может быть эффективно реализован.
7. Трансляция. LR(1)-грамматики. LR(1) таблица разбора. Принцип построения.
Название “LR(к) - грамматика” указывает на то, что для нее существует МП автомат, который начинает просмотр слева направо (Left), распознает правило, когда добирается до самого правого (Rightmost) символа, выводимого из этого правила и может обнаружить любую основу просмотром k-го количества символов, расположенных правее последнего входного символа, выводимого из основы. На практике чаще всего к=1 (LR(1) грамматика) или к=0 (LR(0) грамматика).
Используются также промежуточные между LR(0) и LR(1) методы, известные под названиями SLR(1) и LALR
Отличие LR(k) грамматик от LL(k) состоит в том, что LL(k) грамматики по считанному символу определяют правую часть, а LR(k) грамматики считывают в стек всю правую часть и еще один символ. LR грамматики шире LR грамматик. Можно решить обладает ли грамматика свойством LR(k) для заданного k. Но нельзя решить существует ли k, для которого заданная грамматика будет LR(k) грамматикой.
Алгоритм построения SLR(1)-таблицы:
Если для грамматики невозможно построить LR(0) таблицу разбора, т. е. некоторые состояния получаются неадекватными, т. к. в строке необходимо разместить и сдвиг и свертку, переходят на следующий шаг, строят SLR(1)-таблицу разбора.
SLR(1)-анализатор иначе называется анализатор с предварительным просмотром входного символа.
Элементы строки при построении таблицы заполняются таким образом: Пусть Q - грамматическое вхождение, которым помечена строка, Z - входной символ.
а) если Q не самый правый символ любого правила для любого Z: Q <= Z - элементы таблицы соответствий входным символом удовлетворяется условием
Z FIRST * Y заполняются соответствующими грамматическими вхождениями этих символов (т. е. отмечается номер правила);
б) если Q - самое правое вхождение в правиле <L>, и существует Z: <L> = Z (т. е. существует правило U::=..LZ..), то в соответствующую Z клетку вставляем элемент свертки по правилу <L>.
Если таблица строится по этому алгоритму, то грамматика SLR(1) (простая LR(1) грамматика).
Пример,
1. S Þ real <idlist>
2. <idlist> Þ <idlist>, <id>
3. <idlist> Þ <id>
4. <id> Þ A | B | C
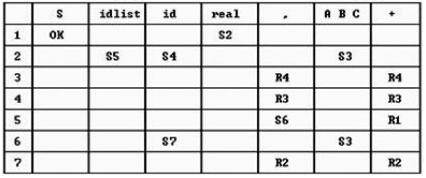
LALR(1)-грамматики. (Look ahead)
Символы следователи - это символы, которые могут следовать за левой частью правила при выполнении операций приведения.
Строим символы-следователи для всех символов исходя из вывода:
A ::= a b c D
.... A e |
e - символ следования для a b c D;Символы следователи приписываются грамматическим вхождениям. Если состояния, имеющие одинаковые грамматические вхождения, но различных следователей, объединены в единое состояние и не порождают неадекватных состояний (противоречий), то они называются LALR(1) LR(1) с предварительным рассмотрением символов.
Пример,
(1) S Þ T else F
(2) T Þ E
(3) T Þ i
(4) F Þ E
(5) E Þ E + i
(6) E Þ i

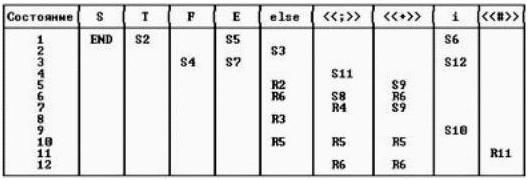
В полном алгоритме LR(1) состояния, соответствующие одинаковым грамматическим вхождениям по различным символам следователям, считаются различными. В LR(1) определение состояния требует учета символов следователей.
Преимущества LR:
- LR-анализаторы могут быть созданы для распознавания, по сути, всех конструкций языков программирования, для которых может быть написана контекстно-свободная грамматика.
- Метод LR-анализа – наиболее общий известный метод ПС-анализа без отказа, к-ый, кроме того, не уступает в эффективности другим методом этого типа.
- Класс грамматик, которые могут быть разобраны с использованием LR-методов, представляет собой собственное надмножество класса грамматик, к-ые могут быть разобраны предиктивными синтаксическими анализаторами.
- LR-анализатор может обнаруживать синтаксические ошибки сразу же, как только это становится возможным при сканировании входного потока.
8. Трансляция. Включение действий в синтаксис.
Анализ и синтез в компиляции удобно рассматривать отдельно, но на практике это часто происходит параллельно. Это совершенно очевидно для однопроходного компилятора, в много проходных – параллельно с синтаксическим разбором создается промежуточный код.
Грамматики могут содержать вызов действий не только для генерации кода, но и для выполнения других задач:
1. Получение тетрад
2. Т. к. синтаксический анализатор обычно использует КС-граматику, необходимо найти метод определения контекстно-зависимых частей языка. Например, во многих языках идентификаторы не могут применяться, если не описаны.
3. Программное размещение. Трансляция не в код, а в другое представление.
4. Анализаторы программ:
а) перечислить идентификаторы в любом блоке;
б) учет числа реализаций и т. п.
в) оптимизация исходного кода.
5. Атрибутивные грамматики.
Пример перевода арифметического выражения в тетрады:
Параллельно с грамматическим разбором выполняются действия – генерируются тетрады (четверки). Грамматика + действие для арифметических выражений выглядит так:
<S> –> <E> A4
<E> –> <T> | <E> + A1 <T> A3
<T> –> <F> | <T> * A1 <F> <A3>
<F> –> '-' A1 <F> A2 | id A1 | (E)
A1 - поместить в стек для любого идентификатора.
А3 - взять три элемента из стека, напечатать их, припечатать знак «=» и очередной номер (целое число), поместить полученное целое число в стек.
А2 - взять два элемента из стека напечатать их, припечатать знак «=» и очередной номер (целое число), поместить полученной целое число в стек.
А4 - взять один элемента из стека.
Грамматика для четверок
<S> –> <OPER> <OP1> <OPER> = < INT> | <OP2> <OPER> = <INT>
<OPER> –> INT | ID
<INT> –> DIGIT | DIGIT <INT>
<OP1> –> + | x
<OP2> –> -
Рассмотрим для примера строку: (-a + b)*(c + d).
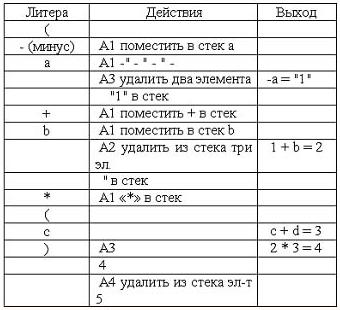
Следует заметить:
Hиразу не пришлось сравнивать приоритеты (т. к. они заданы в граматике). Метод не сложно распространить и на различных приоритетах. Для LL(1) методе необходимо преобразовать грамматику, т. к. она леворекурсивная.Грамматики могут содержать вызов действий не только для генерации кода, но и для выполнения других задач. Например, для работы с таблицей символов.
Поскольку синтаксический анализатор обычно использует контекстно-свободную грамматику, необходимо найти метод определения контекстно-зависимых частей языка. Например, во многих языках идентификаторы не могут применяться, если они не описаны, и имеются ограничения в отношении способов употребления в программе значений различных типов. Для запоминания описанных идентификаторов и их типов большинство компиляторов пользуются таблицей символов.
Когда описывается идентификатор, например, int a, мы говорим, что имеется определяющая реализация «а». Однако «а» может встречаться и в другом контексте: а:=4 или a+b или read(a), здесь будут прикладные реализации «а».
Если мы имеем дело с определяющей реализацией идентификатора (или специфицируемым пользователем видом либо знаком операции), то компилятор помещает объект в таблицу символов, а если с прикладной реализацией, - то в таблице символов осуществляется поиск элемента, соответствующего определяющей реализации объекта, чтобы узнать его тип и (возможно) другие признаки, требующиеся во время компиляции.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
