

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Задача синтаксического анализа – формирование из набора лексем предложений языка. Методы преобразования грамматик позволяют переделать данную грамматику таким образом, чтобы новая грамматика порождала тот же язык и имела желательные свойства. Один из методов – рекурсивный.
Процессор грамматического разбора, основанный на методе рекурсивного спуска, состоит из отдельных процедур.
Процедура разбора старается во входном потоке найти подстроку, которая может быть интерпретирована, как правая часть правила для нетерминала, связанного с данной процедурой.
В процессе работы она может вызывать другие подобные процедуры или даже рекурсивно саму себя, для поиска других нетерминальных символов.
Если процедура находит соответствие нетерминальному символу, то она заканчивает свою работу, и передает в вызывающую ее программу признак успешного завершения и устанавливает указатель текущей лексемы на первый символ после распознанной подстроки. Иначе она заканчивается признаком неудачи, или же вызывает процедуру выдачи диагностического сообщения и процедуру восстановления.
Пример. Рассмотрим процедуру разбора для оператора READ.
Грамматика для оператора: READ:: = READ(<id - list>);
• обнаружили лексему READ
• следующая лексема должна быть (,
• <id-list> вызов процедуры,
• если успешно, то лексема должна быть ),
• должна быть ; ,
• успех. end.
Достоинства рекурсивного спуска:
- простота и скорость написания транслятора;
- соответствие грамматики и анализаторов. Это увеличивает вероятность правильности написания программы.
Недостатки
- большое число вызовов процедур, отсюда относительно медленый анализатор;
- большой объем полученного анализатора;
- данный метод способствует включению в синтаксический анализ процедур семантического анализа и генерации кода. С одной стороны, это хорошо, так как оператор разбирается полностью в одном месте. А с другой стороны, это плохо, так как транслятор становится машинозависимым, и это делает его не мобильным.
Проблемы нисходящего разбора
- Первая проблема - сам по себе метод не исключает возвратов, т. е. для нетерминала, имеющего несколько правых частей, приходится решать, какую альтернативу необходимо выбрать. Пример, <idlist> = id | id, <idlist>.
Для решения этой проблемы используются правила факторизации.
- Второй проблемой является левая рекурсия.
Рассмотрим предложение <idlist> = id | <idlist>, id. Если процедура выберет вторую альтернативу <idlist>, id, то она немедленно вызовет рекурсивно саму себя для поиска нетерминала <idlist>. В результате будет зацикливание.
В связи с этим недостатком рекурсивного спуска, в процессе грамматического разбора часто используется замена левой рекурсии на правую.
Правила факторизации (левой факторизации) заключаются в том, что общие части грамматических правил выносятся за скобку. Принцип левой факторизации можно выразить в символической форме следующим образом:
если грамматика содержит n правил <A> Þ ab1 . . .<A> Þ abn,
где <A> - нетерминал, а a и bi для 1£ i £ n - цепочки нетерминалов и терминалов, то эти правила можно заменить на следующие n+1 правила:
<A> Þ a<В>
<В> Þ b1 ... <B> Þ bn
где <В>- нетерминальный символ, не входящий в исходную грамматику.
Пример, A Þ BC A Þ BCM
A Þ BCD A Þ axN
A Þ axy M Þ e
A Þ аxz M Þ D
N Þ y
N Þ z
Нетерминал называется леворекурсивным, если, применяя к нему одно или более правил, можно вывести цепочку, начинающуюся этим нетерминалом. Правило называется леворекурсивным, если оно используется на первом шаге такого вывода. Пример, <A> Þ a<B>
<A> Þ <B>b
<B> Þ <A>c
<B> Þ d
Правило называется самолеворекурсивным, если его первый символ правой части и левая часть – это один и тот же символ.
Пример, <S> Þ <S> a
<S> Þ b
Грамматику с левой рекурсивностью всегда можно переделать в грамматику с правой рекурсией. Основная идея при этом состоит в том, чтобы смотреть на рекурсивный нетерминал как на порождающий некоторую цепочку, за которой следует список из одного или более элементов.
Пример, грамматика: <idlist> Þ id | <idlist> , id заменяется на
<idlist> Þ id <A>
<A> Þ e | , id <A>
5. Трансляция. LL(1)-грамматики. Направляющие символы. Идея разбора. Построение таблицы. Достоинство и недостатки метода.
КС-грамматика называется LL(1) грамматикой, тогда и только тогда, когда множества выбора правил с одинаковой левой частью не пересекаются. Название “LL(1)” объясняется тем, что автомат начинает просматривать входную цепочку слева (Left) и обнаруживает появление правила по самому левому (Leftmost) символу цепочки, выводимой из этого правила, причем это решение принимается по одному текущему символу. Нисходящий разбор можно также рассматривать в терминах “множества выбора”, состоящих из входных цепочек длины k. В таком случае говорят о LL(k)-грамматиках.
Пример: <S> Þ IF <B> THEN <S1>
<S> Þ IF <B> THEN <S1> ELSE <S>
Эта грамматика не может быть LL(1) грамматикой, так как с IF начинаются обе альтернативы. Применив факторизацию получим:
<S> Þ IF <B> THEN <S1> <нечто>
<нечто> Þ ELSE <S>
<нечто> Þ ε
где <нечто> - это новый нетерминал, к-ый в грамматике больше нигде не встреч-ся.
Для каждого нетерминала и его альтернативы определяем множество терминальных символов, с которых может начинаться цепочка, выводимая из данного нетерминала по данной альтернативе. Это множество нетерминальных символов называется множеством символов предшественников. Необходимым условием того, что грамматика обладает свойством LL(1) является непересекаемость множества символов предшественников для альтернатив каждого правила.
Если из нетерминала А выводится пустое множество: А -> ε
В этом случае рассматривается множество отношения FOLLOW для А, т. е. все терминальные символы, которые могут следовать за А в правых частях правила грамматики. Введем определение направляющего множества символов для нетерминала и альтернативы
N(A,α)={ P(A,α) для α –> *ε
FOLLOW A для α –> *ε }
Необходимым условием того, что грамматика обладает свойством LL(1) является непересекаемость направляющих множеств символов для альтернатив каждого правила. КС-грамматикой называется LL(1)-грамматика, если для любого правила, имеющего альтернативы, направляющие множества альтернативы не пересекаются.
Идея разбора
- Для каждого нетерминального символа, находящегося в левой части строится строка таблицы, в которую вносится имя нетерминала, множество направляющих символов для этого нетерминала и указатель на группу строк соответствующей правой части правила.
- Если нетерминал имеет несколько альтернатив, то для него строятся соответствующие альтернативам строки, в каждую вносится имя нетерминала, множество направляющих символов для этого нетерминала и альтернативы, указатель на группу строк соответствующей альтернативы.
- Каждому элементу из правой части отводится строка таблиц:
Если символ терминальный, то в строку вносится символ, и указатель на следующую строку таблицы, если символ не последний в альтернативе, иначе указателю присваивается нулевое значение.
Для нетерминала правой части строится строка таблицы, в которую вносится имя нетерминала, множество направляющих символов для этого нетерминала и указатель на строку, помеченную этим нетерминалом для левой части правила.
Для пустого символа тоже создается строка, в которую вносится пустой символ, множество направляющих символов и указателю присваивается нулевое значение.
Пример построения LL(1) :
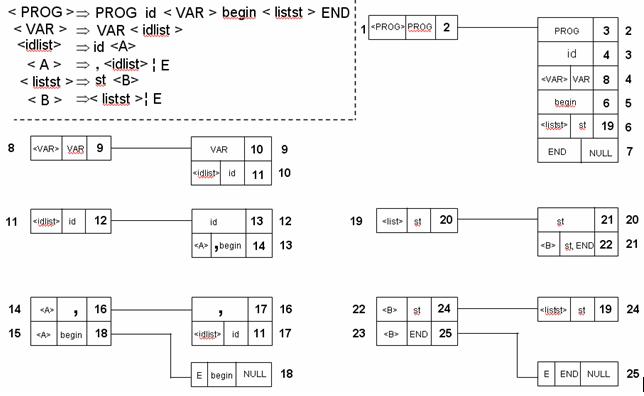
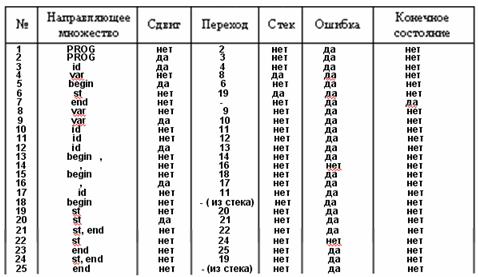
Достоинства распознавателей, основанных на LL(1) грамматике
- в отличие от рекурсивного спуска в методе нет возвратов, это детерминированный метод;
- время разбора пропорционально длине входной программы;
- имеются хорошие диагностические характеристики, и существует возможность исправления ошибок, так как распознавание ведется по одному символу;
- таблица разбора меньше, чем соответствующая таблица разбора в других методах.
Недостаток распознавателей, основанных на LL(1) грамматиках
- не все классы языков описываются LL(1) грамматиками.
6. Трансляция. Восходящий разбор. Основа. Проблемы. Обзор методов.
Восходящий метод разбора – разбор снизу-вверх, при котором промежуточные выводы перемещаются по дереву по направлению к корню
При восходящем методе разбора все правила грамматики обязательно нумеруются. Рассматривается, как правило, пополненная грамматика, то есть грамматика, для которой из аксиомы выводится только одна альтернатива.
Суть всех методов разбора заключается в следующем: сначала в стек символ за символом помещают входную цепочку, до тех пор, пока в стеке не будет находиться некоторое правило. Символы этого правила извлекаются из стека, заменяются на соответствующий нетерминал, затем процесс продолжается до тех пор, пока в стеке не окажутся аксиомы, а во входной цепочке не останется символ конца.
Пример. Рассмотрим грамматику со следующими правилами:
1. S Þ real <idlist>
2. <idlist> Þ id, <idlist>
3. <idlist> Þ <id>
4. <id> Þ A | B | C
Разберем следующее предложение real A, B, C ^ , где ^ обозначает конец цепочки. Шаги (на каждом шаге рисовать стек и символы, находящиеся в нем; символы, перечисленные после «в стеке:» рисуются снизу - вверх):

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
