

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Хотя в состав компилятора могут входить все компоненты, то есть ЛА, Син. А, Сем. А, генерация кода, их взаимодействие может осуществляться различными способами. Трехпроходной компилятор – такая организация не может придать компилятору высокую скорость выполнения, так как обращение к файлам происходит три раза, но ее преимущество состоит в независимости фаз компиляции, т. е. переделки для новых машин коснутся только генерации кода. Любой блок может работать отдельно, и выгружаться из памяти после выполнения.
2. Трансляция. Синтаксический анализ. Задача разбора. Сравнение восходящих и нисходящих методов разбора.
О синтаксическом анализе читайте в предыдущем вопросе.
Синтаксический разбор имеет дело с предложениями языка программирования или с сентенциальной формой. Разбор сентенциальной формы означает построение вывода, и, возможно, синтаксического дерева для нее. Программу разбора называют также распознавателем, так как она распознает только предложения рассматриваемой грамматики. Все алгоритмы разбора, которые мы рассматривали, называются алгоритмами разбора слева направо ввиду того, что они обрабатывают сначала самые левые символы рассматриваемой цепочки и продвигаются по цепочке только тогда, когда это необходимо.
Различают две категории алгоритмов разбора: нисходящий (сверху вниз) и восходящий (снизу вверх). Эти термины соответствуют способу построения синтаксических деревьев. При нисходящем разборе дерево строится от корня (начального символа) вниз к концевым узлам.
Пример. Рассмотрим предложение 35 в следующей грамматике целых чисел:
N ::= D | N D
D ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
На первом шаге непосредственный вывод N –> N D будет строиться так, как это показано в первом дереве:
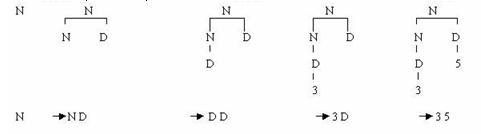
На каждом последующем шаге самый левый нетерминал V текущей сентенциальной формы xVy заменяется на правую часть u правила V ::= u, в результате чего получается следующая сентенциальная форма. Фокус в том, что получить ту сентенциальную форму, которая совпадает с заданной цепочкой.
При нисходящем разборе существует проблема выбора альтернативного правой части правила для замены нетерминала. Предположим, что надо заменить самый левый нетерминал V некоторой сентенциальной формы, и пусть имеется n правил:
V ::= x1 | x2 | …| xn.
Как узнать, какой цепочкой x1 следует заменить V?
Метод восходящего разбора состоит в том, что, отправляясь от заданной цепочки, пытаются привести ее к начальному символу. На первом шаге при разборе предложения 3 5 терминал 3 приводится к D, в результате чего получается сентенциальная форма D 5. На следующем шаге D приводится к N. Этот процесс продолжается до тех пор, пока не будет получено первое дерево.
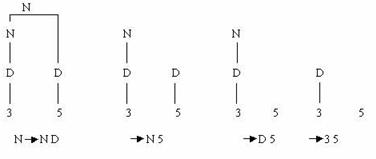
Деревья на рис. расположены справа налево, потому что такое расположение лучше иллюстрирует построенный вывод, который теперь читаем, как обычно, слева направо. Выводы, произведенные двумя различными распознавателями различны, но имеют одно и то же синтаксическое дерево.
При восходящем разборе слева направо на каждом шаге редуцируется основа (самая левая простая фраза) текущей сентенциальной формы и поэтому цепочка справа от основы всегда содержит только терминальные символы.
Проблема восходящего разбора состоит в следующем: при восходящем разборе на каждом шагу редуцируется основа. Как найти основу сентенциальной формы и то, к чему она должна приводиться?
Транслируемая программа рассматривается слева направо, поэтому при разборе и фразу сентенциальной формы лучше брать самую левую, т. е. основу.
Определение. Непосредственный вывод xUy –> x u y называется каноническим и записывается xUy –> x u y, если y содержит только терминалы. Вывод w –> + v называется каноническим и записывается w –> + v, если каждый непосредственный вывод в нем является каноническим.
Каждое предложение, но не каждая сентенциальная форма имеет канонический вывод. Рассмотрим в качестве примера сентенциальную форму 3 D. Ее единственным выводом является <число> –>N D –>D D –> 3 D. И второй, и третий непосредственные выводы не являются каноническими. Сентенциальная форма, которая имеет канонический вывод, называется канонической сентенциальной формой.
3. Трансляция. Сканер. Принципы построения. Регулярные грамматики и автоматы.
Лексический анализатор (сканер) представляет ту часть компилятора, которая читает литеры первоначальной исходной программы и строит слова, или иначе символы, исходной программы: идентификаторы, служебные слова, целые числа, одно - или двулитерные разделители, такие как *, +,**, /*. Иногда символы называются атомами или лексемами.
Сканер строит внутреннее представление для каждого символа. В большинстве случаев это целое число фиксированной длины (байт, полуслово, слово и т. д.). В других частях компилятора гораздо эффективнее обрабатываются эти целые числа, чем цепочки переменной длины, которыми фактически представляются символы.
Поскольку “идентификатор” для синтаксического анализатора является терминальным символом, то безразлично, какой идентификатор встречается в каждом конкретном случае. Однако, при семантическом анализе приходится иметь дело с самим идентификатором, поэтому его необходимо сохранить. Вопрос исчерпан, если сканером выдается две величины: первая - внутренне представление, вторая – фактический символ или ссылка на него. Работа сканера основана на регулярных грамматиках. Регулярные грамматика – грамматика, правила которой имеют вид:

К типу регулярных грамматик относятся два эквивалентных класса грамматик: леволинейные (вид: α –> βγ) и праволинейные (вид: α –> γβ). Регулярные грамматики используются при описании простейших конструкций языков программирования: идентификаторов, констант, строк, комментариев и т. д.
Пример. Рассмотрим грамматику для целых чисел
<число> ::= <цифра>
<цифра> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Данная грамматика является регулярной, т. к. она соответствует виду регулярной грамматики: A –> y, A –> B y, A –> y B.
В данной грамматике символы, которые встречаются в левой части правил, являются нетерминалами или синтаксическими единицами языка. Они образуют множества нетерминальных символов: Vn {<число>, <цифра>}
Символы, которые не входят во множество Vn, называются терминальными символами или терминалами. Они образуют множество: Vt {0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }.
Алфавит данной грамматики представляет собой: V = Vt U Vn.
Для иллюстрации всех правил регулярной грамматики используют диаграмму состояний, к-ая представляет собой ориентированный граф, вершины к-го соответствуют нетерминальным символам правил. Переход от одного состояния к другому изображается в виде дуги, помеченной терминальным символом по к-му осуществляется переход. В зависимости от вида регулярного выражения - праволинейного и леволинейного - диаграмму состояний также строят сверху - вниз и снизу - вверх.
Пример построения диаграммы состояний сверху - вниз:
Грамматика: S –> c A, A –> d A, A –> b B, B –> c.
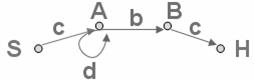
По диаграмме состояний начинаем двигаться с состояния S. Осуществляем переход из состояния S в следующее по соответствующему правилу. Продолжаем до тех пор, пока не достигнем начального состояния H.
Пример построения диаграммы состояний снизу - вверх:
Грамматика: S –> A c, A –> A d, A –> B b, B –> c.
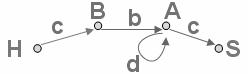
По диаграмме состояний начинаем двигаться с начального состояния H. Осуществляем переход из начального состояния в следующее по соответствующему правилу. Продолжаем до тех пор, пока не достигнем аксиомы S.
Разбор входной цепочки по диаграмме состояния. Рассмотрим вторую диаграмму и возьмем входную цепочку сbdc. По диаграмме состояний начинаем двигаться с символа H. Рассматриваем символ входной цепочки, как символ перехода из одного состояния диаграммы в другое. Конец цепочки должен соответствует конечному состоянию диаграммы S. Если конечное состояние достигнуто, то входная цепочка принадлежит языку. Т. о. цепочка cbdc принадлежит языку.
По диаграмме состояний можно построить таблицу состояний
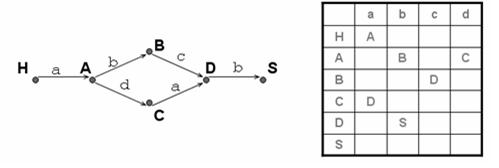
Строки таблицы состояний помечаются вершинами графа, а столбцы –допустимыми входными символами. Если существует переход из состояния 1 в состояние 2 по входному символу х, то на пересечении строки, помеченной состоянием 1 и столбца, помеченном символом х ставится нетерминальный символ состояния 2.
Таблица состояний используется в конечных автоматах для распознавания предложений, принадлежащих языку. Конечным автоматом S называется формальная система вида S={A, Q, V, d, l}, где A - входной алфавит {a1, a2, …, am}; Q - алфавит состояний (нетерминальное множество грамматики {q1, q2, …, qn}); V - выходной алфавит; d - функция переходов, для которой характерно A × Q → Q; l - функция выходов, определяющая отображение вида A × Q → V.
Недетерминированным конечным автоматом называется такой автомат, любая клетка таблицы переходов которого имеет более одного состояния. Таблица переходов – таблица, где по строкам располагаются состояния, а по столбцам символы входного алфавита. Клетки таблицы заполняются состояниями, в которые переходит автомат под воздействием входных символов, а также символами входного алфавита, с соответствующими реакциями автомата на входные символы.
Детерминированным конечным автоматом называется такой автомат, любая клетка таблицы переходов которого не содержит более одного состояния.
4. Трансляция. Синтаксический анализ. Нисходящий разбор, рекурсивный спуск. Проблемы нисходящего разбора, их разрешение.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
