

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Граф=структура, состоящая из вершин и связей между ними (ребер). Если ребра имеют направление, то их называют дугами, а граф - ориентированным.
Представление графа
1) Матрица смежности = матрица, в которой aij равно 1, если вершина ai связана с вершиной aj, иначе 0.Для неориентированных графов эта матрица симметрична.

Достоинства: наглядность, легкий доступ к сыновьям и предшественникам, возможность использования аппарата матричной алгебры.
Недостатки: неэкономичность (особенно для разреженных графов),неудобство корректировки (добавления и удаления вершин).
2) Списковое представление.
Часто использование матрицы смежности неудобно, т. к. число узлов требуется знать заранее. Для решения этой проблемы используют динамическое представление графа (аналогично представлению бинарных деревьев).
Граф представляется в виде двух списков: Первый описывает вершины графа и содежрит ссылку на ту часть второго списка, где описываются ребра для этой веришны:
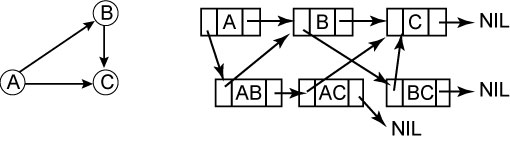
Достоинства: экономичность, возможность корректировки
Недостатки: сложность поиска, невозможность сразу найти предшественников текущей вершины. Эти недостатки можно преодолеть введением дополнительных списков, но это еще больше усложняет структуру.
Возможны и смешанные варианты представления графа. Например, для графов, допускающих существование нескольких дуг между двумя вершинами, элементами матрицы смежности могут быть указатели на соответствующие списки дуг.
4. Бинаpные деpевья поиска и их коppектиpовка
Бинарное дерево = дерево, у каждой вершины которого не более 2 сыновей.
Бинарное дерево поиска = бинарное дерево, в котором у каждой вершины ключевое значение больше ключевых значение левого поддерева и меньше ключевых значений левого поддерева.
Рассмотрим бинарное дерево
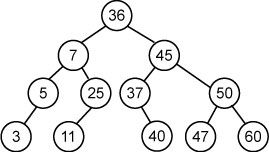
Вставка. Для того чтобы определить место вставки нового ключа, вершины просматриваются начиная с корня – Если ключ для вставки меньше значения ключа текущей вершины, то переходим по левой ветке, а если больше – то по правой.
Например, вставка ключа 48:
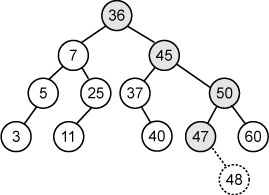
Удаление.
1) Если удаляемый узел не имеет сыновей – он может быть удален без дальнейших изменений дерева (напр., вершины 3,11,40 и т. д)
2) Если узел имеет только одно поддерево, то его единственный сын перемешается на его место (Например при удалении вершин 5,25,37)
3) Если узел имеет двух сыновей: сначала на место удаленной вершины помещается один из двух соседних элементов (это может быть 1)меньший ключ самой правой вершины левого поддерева 2)больший ключ самой левой вершины правого поддерева). Найденная вершина имеет не более одного сына, поэтому дальнейшее удаление идет по описанному выше алгоритму.
Например, при удалении вершины 36 из исходного дерева, она может быть заменена вершиной 25 либо 37. При замене вершиной 25, на месте вершины 25 оказывается узел 11 (по правилу 2):
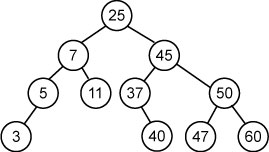
5. АВЛ-деpевья и их балансиpовка
Трудоемкость поиска по бинарному дереву поиска зависит от структуры дерева. Наболее эффективен поиск по т. н. сбалансированному дереву – дереву, в котором для каждого узла высота его поддеревьев отличается не более, чем на 1. Такие деревья поиска называют АВЛ-деревьями (по имени авторов Адельсон-Вельский и Лендис) hl - высота левого поддерева; hr - высота правого поддерева |hl-hr|=2 - признак нарушения балансировки. Высота пустого дерева= -1 (для удобства)
Чтобы получить сбалансированное дерево, необходимо выполнить некоторую трансформацию данного дерева так, чтобы: 1) прохождение трансформированного дерева в симметрично порядке должно быть таким же, как для первоначального дерева; 2) трансформированное дерево должно быть сбалансированным
Преобразование дерева с целью балансировки наз-ся поворотом.
Сущ.4 вида поворотов:LL, RR, LR, RL. Повороты LL, RR–одинарные. LR, RL – двойные.
Пример LL-поворота. Пусть в исходное АВЛ дерево включается новый элемент с ключом 2:
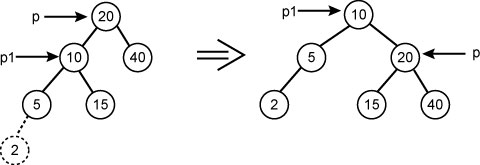
Поворот осуществляется в три операции:
p1 := p^.left; p^.left := p1^.right; p1^.right := p;
RR поворот осуществляется симметрично.
Пример LR поворота. Пусть в исходное АВЛ дерево включается новый элемент с ключом 17:
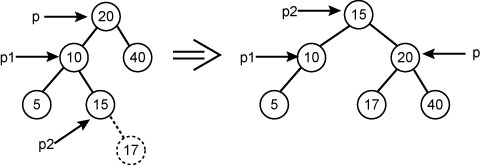
LR поворот требует шести операций: p1 := p^.left; p2 := p1^.right; p1^.right := p2^.left; p2^.left := p1; p^.left := p2^.right; p2^.right := p
RL поворот осуществляется симметрично.
При любом включении рассматривается число уровней в левом и правом поддереве для всех вершин на пути от включаемой вершины к корню. При первом же случае нарушения баланса он восстанавливается. При включении достаточно 1 раз восстанавливать баланс.
Исключение из АВЛ дерева происходит как из обычного дерева поиска, далее требуется анализ, есть ли нарушение баланса и соответствующие повороты на пути от исключаемой вершины к корню.
6. Хеширование
Эффективность всех методов поиска зависит от числа сравнений. Чем меньше сравнений, тем выше эффективность.
Рассмотрим таблицу элементов, характеризующихся значением ключей. Адресом элемента таблицы будем считать номер элемента в таблице, с 0.
Хэш-функция H=функция преобразующая ключевое значение в адрес элемента(индекс таблицы).
Требования: легкость вычисления, равномерная расстановка ключей по диапазону индексов в таблице.
Коллизия – ситуации, когда при разных ключах хеш-фнукция возвращает одно значение, т. е. h(k1)=h(k2), а 2 записи не могут занимать одну и ту же позицию в таблице. Хорошей хеш-функцией является та, кот. минимизирует коллизии и распределяет записи равномерно по всей таблице. Чем > диапазон хеш-функции, тем менее вероятно, что 2 ключа дадут одинаковое значение хеш-функции.
Метод построения Хэш-функции:
Метод середины квадрата - H(k) = k mod N, где k-значение ключа, N-размер таблицы, H(k)-полученное значение адреса.
Методы разрешения коллизий:
Метод линейной пробы
если ячейка занята - занимаем первую свободную после занятой
h0=k mod N – исходное значение хеш-функции. Если эта ячейка занята, то
hi=(h0+i) mod N (где i – номер попытки размещения элемента)
Достоинства. Простота, использ. Все пространство таблицы
Недостатки. эффект скучивания
Метод квадратичной пробы.
h0=k mod N
hi=(h0+i*i) mod N (где i – номер попытки размещения элемента)
Достоинства. Простота, эффект скучивания отсутствует
Недостатки. Можно не найти свободного места в таблице, даже если оно есть.
Метод цепочек – все элементы, распределенные хэш-функцией в одно и то же место таблицы, организуются в линейный список. (т. е. помимо таблицы используется динамически распределяемая память)
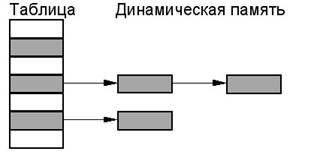
Достоинства. Удобно искать, исключать данные из таблицы
Недостатки. Более сложная организация
Достоинства и недостатки хеширования, как метода поиска данных:
Достоинства:высокая средняя скорость поиска, простота алгоритма.
Недостатки:необходимо заранее оценить кол-во элементов, записи в таблице не отсортированы, а задачи поиска и сортировки обычно решаются совместно, требуется заранее оценивать размер таблицы, сложно удалять записи из таблицы.
7. Быстрая сортировка Хоара
Сортировкой называют перестановку элементов множества в определенном порядке.
Алгоритм быстрой сортировки Хоара для некоторого массива А:
1) Выбирается средний элемент массива X= ak
2) Значения индекса i увеличивается от первого элемента массва до выполнения условия ai < X, значения индекса j уменьшается от последнего элемента до тех пор, пока не встретится aj > X. Если i < j и ai < X и aj > X, то элементы ai и aj меняются местами. Поиск продолжается до тех пор пока не выполнится i > j (т. е. индексы не перехлестнутся).
3) В результате массив делится на две части – слева все элементы меньше X, справа – больше. Процесс повторяется для каждой половины.
Т. о. после будет получен отсортированный массив
|
|
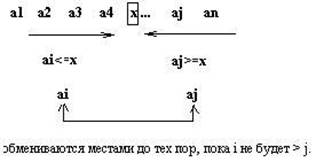
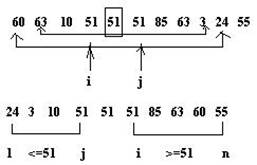
sort(1;n): sort(1;j) от 1 до j и sort(i; n) от i до n.
8. Методы внешней сортировки
Внешняяя сортировка = сортировка, выполняемая на внешних носителях.
Отличия внешней сортировки от внутреней:
1) Внутренняя сортировка - в ОЗУ. Внешняя - на внешних носителях, жесткая экономия памяти не требуется.
2) При внешней доступ к данным последовательный. При внутренней возможен произвольный доступ.
3) Для внешних сортировок более критично число пересылок.
4) При внеш. сортировке часто использ. дополн файлы (чтобы сминимизировать число проходов)
В основе всех внешних сортировок - процедура слияния - объединения 2-х или более отсортированных последовательностей в 1 результирующую.
Сортировка простым слиянием.
Имеется исходный файл A: 2,18,14,25,6,70,43,11,14,9,13 и два вспомогательных файла B, C. Разбиваем файл A (по 1 эл.):
B: 2|14|6 |43|14|13
C:18|25|70|11|9
Собираем в файл А поэлементно из B и C по возрастанию:
A:2,18|14,25|6,70|11,43|9,14|13. В результате имеем файл из отсортированных пар.
Разбиваем файл A (по 2 эл.) в файлы В и С:
B:2,18|6, 70|9,14
C:14,25|11,43|13
Собираем аналогично: A:2,14,18,25|6,11,43,70|9,13,14
Разбиваем файл А по 4 элемента
B:2,14,18,25|9,13,14
C:6,11,43,70
И собираем в A:2,6,11,14,18,25,43,70|9,13,14
Разбиваем
B:2,6,11,14,18,25,43,70|

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
