

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
<E> –> <E>+<T>{+}
<E> –> <T>
<T> –> <T>*<P>{*}
<T> –> <P>
<P> –> (<E>)
<P> –> a{a}
<P> –> b{b}
<P> –> c{c}
Эта новая грамматика называется транслирующей грамматикой или грамматикой перевода.
Транслирующая грамматика - это такая КС-грамматика, множество терминальных символов которой разбито на множество входных элементов и множество символов действия. Цепочки языка, определяемого транслирующей грамматикой, называются последовательностями актов.
Грамматики, транслирующие цепочки, способны описывать перевод только той компоненты символа, которая указывает его класс. Расширенное понятие транслирующей грамматики, включающее в перевод и значение символа, называется “атрибутной грамматикой”.
Атрибутная транслирующая грамматика – это транслирующая грамматика, к которой добавляются следующие определения:
- Каждый входной символ, символ действия или нетерминальный символ имеет конечное множество атрибутов, и каждый атрибут имеет (возможно, бесконечное) множество допустимых значений.
- Все атрибуты нетерминальных символов и символов действия делятся на наследуемые и синтезируемые.
- Правила вычисления наследуемых атрибутов определяются следующим образом:
o каждому вхождению наследуемого атрибута в правую часть данной продукции сопоставляется правило вычисления значения этого атрибута как функции некоторых других атрибутов символов, входящих в правую или левую часть данной продукции
o задается начальное значение каждого наследуемого атрибута начального символа
- Правила вычисления синтезируемых атрибутов определяются так:
- каждому вхождению синтезируемого нетерминального атрибута в левую часть данной продукции сопоставляется правило вычисления значения этого атрибута как функции некоторых других атрибутов символов, входящих в левую или правую часть данной продукции; каждому синтезируемому атрибута символа действия сопоставляется правило вычисления значения этого атрибута как функции некоторых других атрибутов этого символа действия.
Главная идея, лежащая в основе понятия атрибутивной грамматики, состоит в том, что значения символов сопоставляются всем вершинам дерева вывода, как терминальным, так и нетерминальным. Отношения между входными и выходными значениями выражаются по принципу “от правила к правилу”, при этом значения находятся в вершинах дерева. Атрибуты нетерминалов могут передаваться и вычисляться по дереву вывода сверху вниз (синтезируемые атрибуты) и снизу вверх (наследуемые атрибуты).
Пример синтезирующего атрибута.
Предположим существует лексический блока, задающий входное множество {(,),+,*,c} , c-const для синтаксического блока допускающего выражения
S –> <E> {ОТВЕТ} E –> <E> + <T> E –> <T> T –> <T> * <P> T –> <P> P –> (<E>) P –> CЗначение выходного символа {ОТВЕТ} должно быть числом. Требуемое отношение между значениями входных лексем и значением выходного ОТВЕТ можно выразить словами "ОТВЕТ - это числовое значение входного выражения". Найдем математическое выражение этой фразы. Рассмотрим конкретную входную цепочку: (С3 + С9) * (С2 + С41), где значения входных лексем, выданных лексическим блоком, указаны индексами. Этой входной цепочке должна соответствовать выходная цепочка ОТВЕТ516. Построим дерево вывода, соответствующее данной входной цепочке:
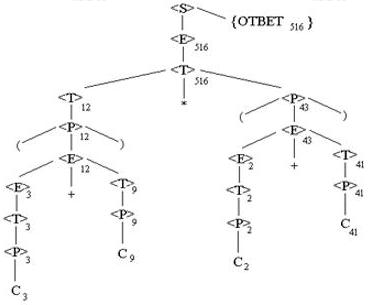
Каждый нетерминал этого дерева <E>, <T>, <P> помечен значением соответствующего подвыражения, а выходной символ – требуемым выходным значением.
Чтобы определить, как расставлять значения на дереве вывода, получаемом по данной грамматике, вначале определим, как получить значение любой нетерминальной вершины, если даны значения ее прямых потомков. С этой целью сопоставим каждому правилу грамматики для <E>, <T> и <P> правило вычисления значения вершины, соответствующей нетерминалу левой части продукции, по данным значениям ее прямых потомков, соответствующих символам правой части грамматики.
Например, правило вычисления значений для продукции E <E> + <T> состоит в том, что значения нетерминала <E> в левой части равно сумме значения нетерминала <E> в правой части и значения нетерминала <E>. Чтобы применить это правило к левому, заключенному в скобки вхождению <E>, в дереве вывода примера, значение <E> в правой части равно 3, а значение <T> равно 9.Отсюда следует, что значение <E> в левой части равно 12 и можно приписать значение 12 соответствующей вершине дерева.
Правило для продукции <E> –> <T> состоит в том, что значение <E> равно значению <T>. Правило для продукции <T> –> <T>*<P> состоит в том, что значение <T> в левой части равно произведению значения <T> в правой части и значения <P>. Правило для <T> –> <P> состоит в том, что значение <T> равно значению <P>. Правило для <P> –> (<E>) состоит в том, что значение <P> равно значению <E>. Правило для <P> –> c состоит в том, что значение <P> равно значению с.
И, наконец, продукцию <S> –> <E>{ОТВЕТ} снабдим правилом, что значение символа ОТВЕТ равно значению <E>.
Для того, чтобы выразить приведенные выше правила математически более строго, можно в каждой продукции дать разные имена разным встречающимся в ней значениям, а затем сформулировать соответствующие ей правила при помощи этих имен. Тогда продукции и соответствующие им правила можно записать так:
1. S –> <E>q {ОТВЕТr}
r <– q
2. Ep –> <E>q + <T>r
p <– q + r
3. Ep –> <T>q
p <– q
4. Tp –> <T>q * <P>r
p <– q * r
5. Tp –> <P>q
p <– q
6. Pp –> (<E>q)
p <– q
7. Pp –> Cq
p <– q
Приведенные выше продукции вместе с соответствующими правилами вычисления значений являются примерами “атрибутных правил”, и взятые вместе с начальным нетерминалом <S> образуют “атрибутную грамматику”. Значения вышеприведенных правил называются “атрибутами”.
В этом примере значение атрибута каждого нетерминала определяется символами, расположенными в дереве вывода под этим нетерминалом. Такое “восходящее” вычисление выражается в том, что правила вычисления атрибутов нетерминалов, ассоциированные с продукциями, указывают, как вычислять атрибуты в левой части продукции по данным атрибутам символов правой части. Атрибуты, значения которых получаются таким восходящим способом, то есть снизу вверх, называются “синтезируемыми ” атрибутами.
Пример наследуемого атрибута.
Рассмотрим следующую грамматику:
1. <описание>::= type id <список переменных>
2. <список переменных>::=, id <список переменных>
3. <список переменных>::= e /пустое правило/
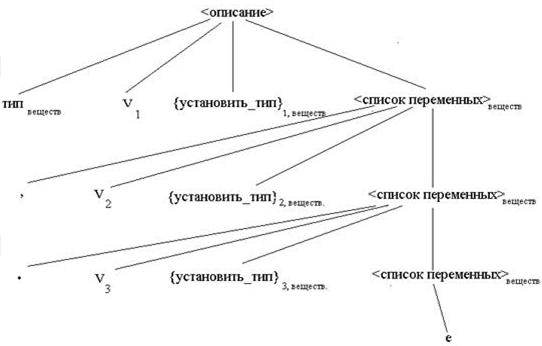
Предположим, что существует лексический блок, задающий три лексемы id ТИП, где лексема id обозначает идентификатор и ее значение является указателем на соответствующий этому идентификатору элемент таблицы имен. ТИП – лексема со значением, определяющим, какой из типов, ВЕЩЕСТВЕННЫЙ, ЦЕЛЫЙ или ЛОГИЧЕСКИЙ, должен быть поставлен в соответствии идентификаторам из данного списка. При обработке описания каждой переменной синтаксический блок вызывает процедуру УСТАНОВИТЬ_ТИП, которая помещает один из типов ВЕЩЕСТВЕННЫЙ, ЦЕЛЫЙ или ЛОГИЧЕСКИЙ в надлежащее поле таблицы символов. Вызов процедуры УСТАНОВИТЬ_ТИП лучше всего осуществлять сразу после того как, идентификатор поступил на блок синтаксического анализатора. Это можно описать следующей грамматикой, использующей символ действия:
1.<описание>::=type id {УСТАHОВИТЬ_ТИП} <список переменных>
2. <список переменных>::=, id {УСТАHОВИТЬ_ТИП} <список переменных>
3. <список переменных>::= e /пустое правило/
Пусть процедура УСТАНОВИТЬ_ТИП имеет два аргумента: это идентификатор (или его адрес) и тип. Тогда вызов процедуры УСТАHОВИТЬ_ТИП можно записать УСТАНОВИТЬ_ТИП (id, type). Введем в вышеприведенную грамматику атрибуты и правила их вычисления, чтобы в последовательностях актов входные символы были представлены вместе с их значениями, играющими роль атрибутов, а вхождения символов действия {УСТАНОВИТЬ_ТИП} имели по два атрибута, представляющих аргументы соответствующего вызова процедуры УСТАНОВИТЬ_ТИП. Тогда вхождения УСТАНОВИТЬ_ТИП будут иметь такой вид: {УСТАНОВИТЬ_ТИП}id, type.
Рассмотрим, как УСТАНОВИТЬ_ТИП получает свои атрибуты. В правиле 1 это делается просто, так как атрибуты можно получить, используя входные символы type и id, входящие в это правило. В правиле 2 type не доступен, его нужно передать, используя атрибуты нетерминала. Поэтому нетерминал <список переменных> должен иметь атрибут, который будет представлять тип.
Таким образом, грамматика перепишется:
1. <описание>::=typet idp {УСТАHОВИТЬ_ТИП}p1, t1 <список переменных> t2
(t2, t1) <– t, p1 <– p
2. <список переменных> t ::=, id p {УСТАHОВИТЬ_ТИП}p1,t1 <список переменных> t2
(t2, t1) <– t, p1 <– p
3. <список переменных> t ::= e /пустое правило/
Запись означает, что t присваивается одновременно t1 и t2. Чтобы получить значения атрибутов, соответствующие вхождениям нетерминала (список переменных), используются символы, расположенные выше в дереве вывода, или символы, входящие в ту же часть правила. Входной символ ТИП определяет значение ВЕЩЕСТВЕННЫЙ, которое передается самому верхнему вхождению нетерминала (список переменных), а затем передается вниз по дереву другим вхождениям.
Такой нисходящий характер вычисления значений атрибутов отражается в том, что каждое правило вычисления атрибутов нетерминалов, сопоставленное продукциям, указывает, как вычислять атрибуты нетерминала, входящего в правую часть продукции. Атрибуты, значения которых задаются таким нисходящим способом, называются “наследуемыми” атрибутами.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
