

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица символов должна иметь ту же блочную структуру, что и программа, чтобы различить виды употребления одного и того же идентификатора.
Рассмотрим язык, обладающий следующими свойствами:
- Определяющая реализация идентификатора появляется (текстуально) раньше любой прикладной реализации.
- Все описания в блоке помещаются непосредственно за begin, т. е. раньше всех операторов или предложений.
- При наличии прикладной реализации идентификатора соответствующая определяющая реализация находится в наименьшем включающем блоке, в котором содержится описание этого идентификатора.
- В одном и том же блоке идентификатора не может описываться более одного раза.
Эти свойства присущи почти всем языкам с блочной структурой.
Синтаксис языка задается правилами:
DEC –> real IDS | integer IDS | boolean IDS
IDS –> id
IDS –> IDS, id
а блок определяется как
BLOCK –> begin DECS; STAT end
где
DECS –> DECS; DEC
DECS –> DEC
STATS –> STATS; s
STATS –> s
Таблица символов может иметь списковую структуру: каждому блоку программы будет соответствовать свой список локальных идентификаторов таблице символов.
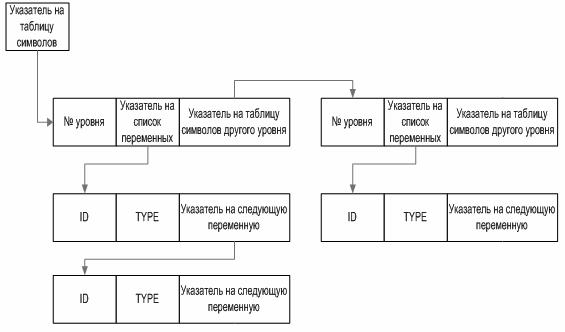
При грамматическом разборе, при вхождении в блок должна создаваться новая структура в таблице символов, в которую помещаются описанные идентификаторы этого блока. Эта структура имеет форму списка, т. к. при вхождении в блок количество идентификаторов неизвестно. При выходе из блока, соответствующая структура таблицы символов может быть уничтожена (для однопроходного транслятора) или сохранена для последующей обработки при повторном проходе компилятора. Таким образом, каждому блоку программы будет соответствовать свой список локальных идентификаторов таблице символов.
Поэтому в грамматику могут быть включены следующие 4 действия, определяющие работу в блоке с таблицей символов.
BLOCK –> begin <A1> DECS; STAT <A2> end
IDS –> id <A3>
IDS –> IDS, id <A3>
STATS –> STATS; s <A4>
STATS –> s <A4>
Действие А1 - вход в блок, создание таблицы символов данного блока.
Действие А2 - связано с выходом из блока (уничтожение таблицы символов блока).
Действие A3 - обработка декларативного оператора. Для каждой определенной реализации идентификатора проверяется наличие описания в списке таблицы символов, если оно отсутствует, создается строка списка в таблице символов данного блока.
Действие А4 - обработка прикладной реализации идентификатора: обращение к таблице символов проверка существования описания и соответствия использования идентификатора его описанию.
В языке, обладающем перечисленными выше свойствами, в качестве структуры данных для таблиц символов очень удобен стек, содержащий описание идентификаторов для блока. При описании соответствующего идентификатора помещается в верхнюю часть стека, а при выходе из блока все элементы таблицы символов, соответствующие описаниям в этом блоке, удаляются из стека. Указатель же стека принимает значение, которое он имел при вхождении в блок. В результате, в любой момент синтаксического разбора элементы таблицы символов, соответствующие всем текущим идентификаторам, находятся в стеке, а связанные с ними прикладные и определяющие реализации идентификаторов требуют поиска в стеке в направлении сверху вниз. Применение стека вместо более сложной цепной структуры дает возможность сэкономить место, занимаемое указателями в этой цепной структуре.
9. Трансляция. Семантика. Внутренние формы программы. Определение числа проходов компилятора. Промежуточные языки.
Семантический анализ служит соединением между фазой анализа и синтеза транслятора. Семантический анализ и генерация кода являются отчасти стадией анализа, отчасти стадией генерации кода. На этой стадии выполняются следующие вспомогательные функции:
- Ведение таблиц символов
- Обнаружение большинства ошибок
- Замена макросов макрорасширениями
- Выполнение инструкций, отнесенных ко времени компиляции
При простой трансляции семантический анализатор может генерировать объектный код, но, как правило, выходом этой стадии служит некоторая внутренняя форма выполняемой программы. В качестве внутреннего языка может использоваться прямая и обратная польские записи, запись триадами и тетрадами.
A = B + C * D
C D * B + A = {постфиксная форма}


Обычно семантический анализатор представляет собой набор отдельных процедур, связанных с определенной синтаксической конструкцией. Семантические процедуры взаимодействуют между собой посредством информации, которая хранится в различных таблицах. Наиболее глобальной является таблица символов.
Введение таблицы символовТаблица символов образуется вначале процесса компиляции. В эту таблицу семантические процедуры обработки декларативных операторов заносят информацию об идентификаторах, а процедуры семантического анализа исполняемых операторов обращаются к таблице с целью получения информации об идентификаторах.
В некоторых языках программирования приняты соглашения по умолчанию – внесение в таблицу символов не объявленных явно переменных. Например, для языков ALGOL, FORTRAN, PL1 переменные, начинающиеся с символов i, j, k, l по умолчанию вставляются в таблицу символов с типом “целые”. Поэтому при обработке исполнительных операторов они заносятся в таблицу символов.
Обнаружение ошибокОбнаружить ошибку достаточно просто, необходимо не только обнаружить, но и сообщить как можно более полно об этой ошибке пользователю.
МакрообработкаВ простейшей форме макрос представляет собой кусок текста программы, который вставляется в программу при трансляции. Зачастую бывает необходимо прервать работу сканера и синтаксического анализатора и переключить их на анализ тела макроса. Только после этого будет возобновлен анализ исходной программы. Простейшим примером макроса является число PI=3.1416.
Операции, относящиеся ко времени компиляцииНекоторые языки программирования позволяют вставлять куски исходного текста в программу в зависимости от некоторых условий. Эти куски тоже необходимо проверить лексически, синтаксически, семантически. Это самая неформализованная часть транслятора.
Проходом компилятора называется просмотр исходной программы или ее версии на некотором внутреннем языке одной из фаз компилятора.
Компиляторы: однопроходные, двухпроходные, трехпроходные.
Однопроходные компиляторы: “+”: быстрота, “-”: полученный код недостаточен.
Необходимость более чем в одном проходе может быть связана со следующими моментами:
- Если определяющая реализация идентификатора может появляется в любом месте блока. Тогда, чтобы определить операцию и сгенерировать соответствующий код необходим дополнительный проход.
- Если мы уберем требование предварительного описания меток и процедур, то рекурсию A->B, B->A невозможно выполнить за один проход, так как невозможно сгенерировать код для процедуры В, так как неизвестно ни типы параметров В, ни типы возвращаемых значений.
1-й проход - заполнение таблицы символов.
2-й проход - генерация кода.
- Необходимость дополнительных проходов бывает вызвана и перегрузкой символов.
- Дополнительный проход при оптимизации кода.
Расплата за многопроходность - создание промежуточных языков.
Промежуточный язык может быть близким
- или к реализуемым языкам (например, Р-код для языка Pascal, Diana для языка Ada, байт-код для языка Java)
- или к машинам, на которых осуществляется реализация (CTL –промежуточный язык для машины MU5).
Простейшей формой промежуточного представления является синтаксическое дерево программы. Синтаксическое дерево изображает естественную иерархическую структуру исходной программы. Даг (Directed Acyclic Graph, направленный ациклический граф) дает ту же информацию, но в более компактном виде, т. е. одинаковые подвыражения в нем объединены.
Наиболее известные промежуточные коды:
- Трехадресный код. Каждый оператор трехадресного кода имеет максимум три адреса. Трехадресный код является линеаризованным представлением синтаксического дерева или дага, в котором внутренним вершинам графа соответствуют явные переменные.
- Р-код. Является промежуточным кодом на основе стека. Инструкция P-кода имеет формат: F (код функции) P (применяется для определения уровня промежуточного результата) Q (для определения статического блока (например, константы)).
- Байт-код – это промежуточный язык для Java Virtual Machine (JVM). Он также основан на использовании стека. Для каждого класса инструкции байт-кода находятся в классификационном файле Java (Java class file). В каждом файле содержится виртуальный машинный код для используемых классом методов (функций/процедур), информация таблицы символов (набор констант в Java), соединений с суперклассами и т. д.
10. Транслирующая грамматика. Атрибутивные грамматики.
Построим КС грамматику, описывающую множество последовательностей актов для перевода инфиксной записи в постфиксную польскую запись.
Грамматика для инфиксных выражений (с начальным нетерминалом <Е>) такова:
<E> –> <E>+<T>
<E> –> <T>
<T> –> <T>*<P>
<T> –> <P>
<P> –> (<E>)
<P> –> a
<P> –> b
<P> –> c
Чтобы построить грамматику для последовательностей актов, опишем действия, соответствующие каждой правой части правил грамматики. Например, чтобы напечатать a после того, как а прочитано, правило 6 изменится следующим образом:
<P> –> a{a}. Чтобы напечатать знак сложения после того, как напечатаны оба его операнда, правило 1 заменяется на <E> –> <E>+<T>{+}. Это новое правило можно выразить словами “обработка <E> состоит из обработки <E>, чтения +, обработки <T> и печатания +”. После аналогичных изменений в других правилах новая грамматика будет такой:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
